How Spotify Uses Semantic Search for Podcasts
Want to add audio search to your applications just like Spotify? You’ll need a vector database like Pinecone. Try it now for free.
The market for podcasts has grown tremendously in recent years, with the number of global listeners having increased by 20% annually in recent years [1].
Driving the charge in podcast adoption is Spotify. In a few short years, they have become the undisputed leaders in podcasting. Despite only entering the game in 2018, by late 2021, Spotify had already usurped Apple, the long-reigning leader in podcasts, with more than 28M monthly podcast listeners [2]
To back their podcast investments, Spotify has worked on making the podcast experience as seamless and accessible as possible. From their all-in-one podcast creation app (Anchor) to podcast APIs and their latest natural language enabled podcast search.
Spotify’s natural language search for podcasts is a fascinating use case. In the past, users had to rely on keyword/term matching to find the podcast episodes they wanted. Now, they can search in natural language, in much the same way we might ask a real person where to find something.
This technology relies on what we like to call semantic search. It enables a more intuitive search experience because we tend to have an idea of what we’re looking for, but rarely do we know precisely which terms appear in what we want.
Imagine we wanted to find a podcast talking about healthy eating over the holidays. How would we search for that? It might look something like:

There is a podcast episode talking about precisely this. Its description is:
"Alex Straney chats to Dr. Preeya Alexander about how to stay healthy over Christmas and about her letter to patients."We have zero overlaps between the query and episode description using term matching, so this result would not be returned using keyword search. To make matters worse, there are undoubtedly thousands of episode descriptions on Spotify containing the words “eat”, “better”, and “holidays”. These episodes likely have nothing to do with our intended search query, but we could return them.
Suppose we were to swap that for a semantic search query. We could see much better results because semantic search looks at the meaning of the words and sentences, not specific terms.
Despite sharing no words, our query and episode description would be identified as having very similar meanings. They both describe being or eating healthier over the winter holidays.
Enabling meaningful search is not easy, but the impact can be huge if done well. As Spotify has proven, it can lead to a much greater user experience. Let’s dive into how Spotify built its natural language podcast search.
Semantic Search
The technology powering Spotify’s new podcast search is more widely known as semantic search. Semantic search relies on two pillars, Natural Language Processing (NLP) and vector search.
These technologies act as two steps in the search process. Given a natural language query, a particular NLP model can encode it into a vector embedding, also known as a dense vector. These dense vectors can numerically represent the meaning of the query.
These vectors have been encoded by one of these special NLP models, called sentence transformers. We can see that queries with similar meanings cluster together, whereas unrelated queries do not.
Once we have these vectors, we need a way of comparing them. That is where the vector search component is used. Given our new query vector, we perform a vector search and compare it to previously encoded vectors and retrieve those that are nearest or the most similar.
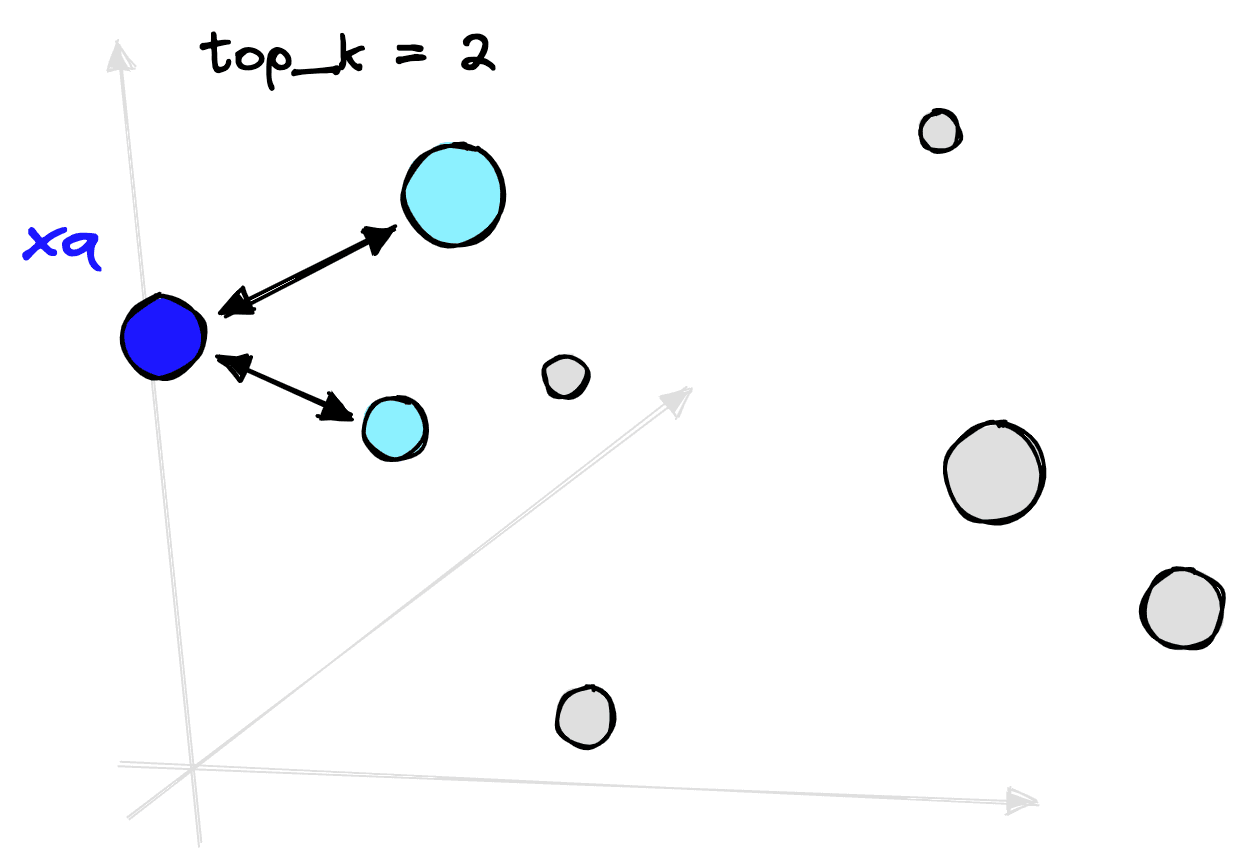
NLP and vector search have been around for some time, but recent advancements have acted as catalysts in the performance increase and subsequent adoption of semantic search. In NLP, we have seen the introduction of high-performance transformer models. In vector search, the rise of Approximate Nearest Neighbor (ANN) algorithms.
Transformers and ANN search have powered the growth of semantic search, but why is not so clear. So, let’s demystify how they work and why they’ve proven so helpful.
Transformers
Transformer models have become the standard in NLP. These models typically have two components: the core, which focuses on “understanding” the meaning of a language and/or domain, and a head, which adapts the model for a particular use case.
There is just one problem, the core of these models requires vast amounts of data and computing power to pretrain.
Pretraining refers to the training step applied to the core transformer component. It is followed by a fine-tuning step where the head and/or the core are trained further for a specific use case.
One of the most popular transformer models is BERT, and BERT costs a reported 2.5K - 50K (USD) to train; this shifts to 80K - 1.6M (USD) for the larger BERT model [4].
These costs are prohibitive for most organizations. Fortunately, that doesn’t stop us from using them. Despite these models being expensive to pretrain, they are an order of magnitude cheaper to fine-tune.
The way that we would typically use these models is:
- The core of the transformer model is pretrained at great cost by the likes of Google, Microsoft, etc.
- This core is made publicly available.
- Other organizations take the core, add a task-specific “head”, and fine-tune the extended model to their domain-specific task. Fine-tuning is less computationally expensive and therefore cheaper.
- The model is now ready to be applied to the organization’s domain-specific tasks.
In the case of building a podcast search model, we could take a pretrained model like bert-base-uncased. This model already “understands” general purpose English language.
Given a training dataset of user query to podcast episode pairs, we could add a “mean pooling” head onto our pretrained BERT model. With both the core and head, we fine-tune it for a few hours on our pairs data to create a sentence transformer trained to identify similar query-episode pairs.
We must choose a suitable pretrained model for our use case. In our example, if our target query-episode pairs were English language only, it would make no sense to take a French pretrained model. It has no base understanding of the English language and could not learn to understand the English query-episode pairs.
Another term we have mentioned is “sentence transformer”. This term refers to a transformer model that has been fitted with a pooling layer that enables it to output single vector representations of sentences (or longer chunks of text).
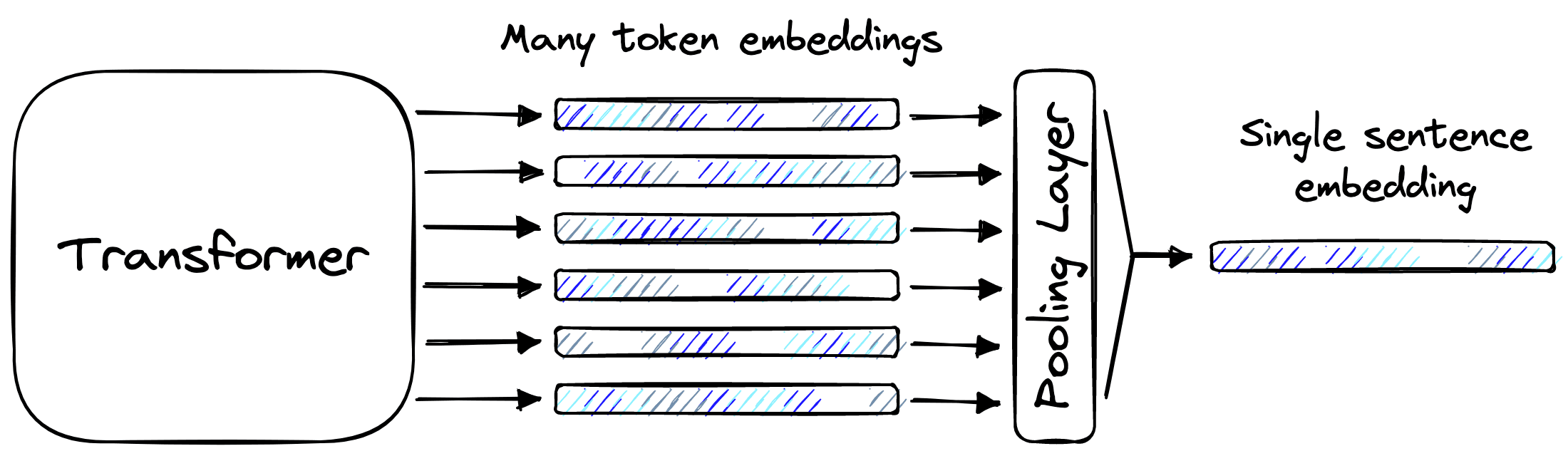
There are different types of pooling layers, but they all consume the same input and produce the same output. They take many token-level embeddings and merge them in some way to build a single embedding that represents all of those token-level embeddings. That single output is called a sentence embedding.
The sentence embedding is a dense vector, a numerical representation of the meaning behind some text. These dense vectors enable the vector search component of semantic search.
ANN Search
Approximate Nearest Neighbors (ANN) search allows us to quickly compare millions or even billions of vectors. It is called approximate because it does not guarantee that we will find the true nearest neighbors (most similar embeddings).
The only way we can guarantee that is by exhaustively comparing every single vector. At scale, that’s slow.
Rather than comparing every vector, we approximate with ANN search. If done well, this approximation can be incredibly accurate and super fast. But there is often a trade-off. Some algorithms offer speedier search but poorer accuracy, whereas others may be more accurate but increase search times.
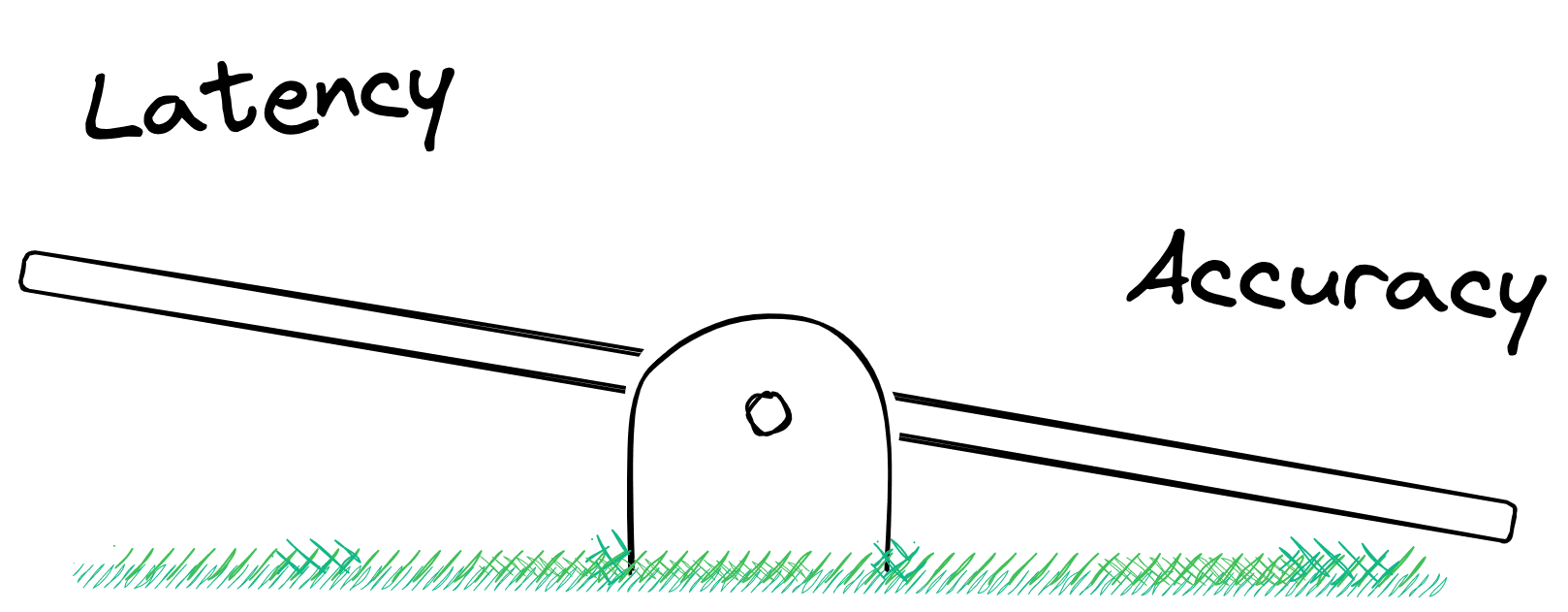
In either case, an approximate solution is required to maintain reasonable query times at scale.
How Spotify Did It
To build this type of semantic search tool, Spotify needed a language model capable of encoding similar (query, episode) pairs into a similar vector space. There are existing sentence transformer models like SBERT, but Spotify found two issues with using this model:
- They needed a model capable of supporting multilingual queries; SBERT was trained on English text only.
- SBERT’s cross-topic performance without further fine-tuning is poor [5].
With that in mind, they decided to use a different, multilingual model called the Universal Sentence Encoder (USE). But this still needed fine-tuning.
To fine-tune their USE model to encode (query, episode) pairs in a meaningful way, Spotify needed (query, episode) data. They had four sources of this:
- Using their past search logs, they identified (query, episode) pairs from successful searches.
- They identified unsuccessful searches that were followed by a successful search. The idea is that the unsuccessful query is likely to be a more natural query, which was then used as a (query_prior_to_successful_reformulation, episode) pair.
- Generating synthetic queries using a query generation model produces (synthetic_query, episode) pairs.
- A small set of curated queries, manually written for episodes.
Sources (1 - 3) fine-tune the USE model, with some samples left for evaluation. Source (4) was used for evaluation only.
Unfortunately, we don’t have access to Spotify’s past search logs, so there’s little we can do in replicating sources (1 - 2). However, we can replicate the approach of the building source (3) using query generation models. And, of course, we can manually write queries as per source (4).
Data Preprocessing
Before generating any queries, we need episode data. Spotify describes episodes as a concatenation of textual metadata fields, including episode title and description, with the podcast show’s title and description.
We can find a podcast episodes dataset on Kaggle that contains records for 881k podcast episodes i. Including episode titles and descriptions, with podcast show titles and descriptions.
We use the Kaggle API to download this data, installed in Python with pip install kaggle. An account and API key are needed (find the API key in your Account Settings). The kaggle.json API key should be stored in the location displayed when attempting to import kaggle. If no location or error appears, the API key has already been added.
We then authenticate access to Kaggle.
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()Once authenticated, we can download the dataset using the dataset_download_file function, specifying the dataset location (found from its URL), files to download, and where to save them.
api.dataset_download_file(
'listennotes/all-podcast-episodes-published-in-december-2017',
file_name='podcasts.csv',
path='./'
)
api.dataset_download_file(
'listennotes/all-podcast-episodes-published-in-december-2017',
file_name='episodes.csv',
path='./'
)Both podcasts.csv and episodes.csv will be downloaded as zip files, which we can extract using the zipfile library.
with zipfile.ZipFile('podcasts.csv.zip', 'r') as zipref:
zipref.extractall('./')
with zipfile.ZipFile('episodes.csv.zip', 'r') as zipref:
zipref.extractall('./')
We have two CSV files, podcasts.csv details the podcast shows themselves, including titles, descriptions, and hosts. The episodes.csv data includes data from specific podcast episodes, including episode title, description, and publication date.
To replicate Spotify’s approach of concatenating podcast shows and episode-specific details, we must merge the two datasets. We do this with an inner join on the podcast ID columns.
episodes = episodes.merge(
podcasts,
left_on='podcast_uuid',
right_on='uuid',
suffixes=('_ep', '_pod')
)
Before concatenating the features we want, let’s clean up the data. We strip excess whitespace and remove rows where any of our relevant features contain null values.
features = ['title_ep', 'description_ep', 'title_pod', 'description_pod']
# strip whitespace
episodes[features] = episodes[features].apply(lambda x: x.str.strip())print(f"Before: {len(episodes)}")
episodes = episodes[
~episodes[features].isnull().any(axis=1)
]
print(f"After: {len(episodes)}")Before: 873820
After: 778182
We’re ready to concatenate, giving us our episodes feature.
episodes = episodes['title_ep'] + '. ' + episodes['description_ep'] + '. ' \
+ episodes['title_pod'] + '. ' + episodes['description_pod']
episodes = episodes.to_list()episodes[50:53]['Fancy New Band: Running Stitch. <p>Running Stitch join Hannah to play sme new tracks ahead of their EP release next year. Cheers NZ On Air Music!</p>. 95bFM. Audio on demand from selected shows',
"Political Commentary w/ David Slack: December 21, 2017. <p>It's the end of the year, and let's face it... 2017 hasn't been a great one for empathy. From\xa0the public treatment of our politicians\xa0to the treament of our least fortunate citizens, David Slack reckons it's about time we all took pause. It is Christmas, after all.</p>. 95bFM. Audio on demand from selected shows",
'From the Crate w/ Troy Ferguson: December 21, 2017. <p>LP exploration with the ever-knowledgeable Troy, featuring the following new cakes and/or tasty re-releases:</p>\n\n<ul>\n\t<li>Ken Boothe - <em>You Keep Me Hangin\' On</em></li>\n\t<li>The New Sounds -\xa0<em>The Big Score</em></li>\n\t<li>Jitwam -\xa0<em>Keepyourbusinesstoyourself</em></li>\n</ul>\n\n<p>All available from and thanks to\xa0<a href="http://www.southbound.co.nz/shop/">Southbound Records</a>.</p>. 95bFM. Audio on demand from selected shows']Let's shuffle our data too.from random import shuffle
shuffle(episodes)Query Generation
We now have episodes but no queries, and we need (query, episode) pairs to fine-tune a model. Spotify generated synthetic queries from episode text, which we can do.
To do this, they fine-tuned a query generation BART model using the MS MARCO dataset. We don’t need to fine-tune a BART model as plenty of readily available models have been fine-tuned on the exact same dataset. Therefore, we will initialize one of these models using the HuggingFace transformers library.
from transformers import T5Tokenizer, T5ForConditionalGeneration
# after testing many BART and T5 query generation models, this seemed best
model_name = 'doc2query/all-t5-base-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).cuda()
We tested several T5 and BART models for query generation on our episodes data; the results are here. The doc2query/all-t5-base-v1 model was chosen as it produced more reasonable queries and has some multilingual support.
It’s time for us to generate queries. We will generate three queries per episode, in-line with the approach taken by the GenQ and GPL techniques.
# (OPTIONAL) it will take a long time to produce queries for the entire dataset, let's drop some episodes
episodes = episodes[:100_000]from tqdm.auto import tqdm
batch_size = 128 # larger batch size == faster processing
num_queries = 3 # number of queries to generate for each episode
pairs = []
ep_batch = []
for ep in tqdm(episodes):
# remove tab + newline characters if present
ep_batch.append(ep.replace('\t', ' ').replace('\n', ' '))
# we encode in batches
if len(ep_batch) == batch_size:
# tokenize the passage
inputs = tokenizer(
ep_batch,
truncation=True,
padding=True,
max_length=256,
return_tensors='pt'
)
# generate three queries per episode
outputs = model.generate(
input_ids=inputs['input_ids'].cuda(),
attention_mask=inputs['attention_mask'].cuda(),
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=num_queries
)
# decode query to human readable text
decoded_output = tokenizer.batch_decode(
outputs,
skip_special_tokens=True
)
# loop through to pair query and episodes
for i, query in enumerate(decoded_output):
query = query.replace('\t', ' ').replace('\n', ' ') # remove newline + tabs
ep_idx = int(i/num_queries) # get index of episode to match query
pairs.append([query, ep_batch[ep_idx]])
ep_batch = []100%|██████████| 100000/100000 [08:44:31<00:00]Query generation can take some time, and we recommend limiting the number of episodes (we used 100k in this example). Looking at the generated queries, we can see some good and some bad. This randomness is the nature of query generation and should be expected.
We now have (synthetic_query, episode) pairs that can be used in fine-tuning a sentence transformer model.
Models and Fine-tuning
As mentioned, Spotify considered using pretrained models like BERT and SBERT but found the performance unsuitable for their use case. In the end, they opted for a pretrained Universal Sentence Encoder (USE) model from TFHub.
We will use a similar model called DistilUSE that is supported by the sentence-transformers library. By taking this approach, we can use the sentence-transformers model fine-tuning utilities. After installing the library with pip install sentence-transformers, we can initialize the model like so:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('distiluse-base-multilingual-cased-v2')
When fine-tuning with the sentence-transformers library, we need to reformat our data into a list of InputExample objects. The exact format does vary by training task.
We will be using a ranking function (more on that soon), so we must include two text items, the (query, episode) pairs.
from sentence_transformers import InputExample
eval_split = int(0.01 * len(pairs))
test_split = int(0.19 * len(pairs))
# we separate a number of these for testing
test_pairs = pairs[-test_split:]
pairs = pairs[:-test_split]
# and take a small number of samples for evaluation
eval_pairs = pairs[-eval_split:]
pairs = pairs[:-eval_split]
train = []
for (query, episode) in pairs:
train.append(InputExample(texts=[query, episode]))
We also took a small set of evaluation (eval_pairs) and test set pairs (test_pairs) for later use.
As mentioned, we will be using a ranking optimization function. That means that the model is tasked with learning how to identify the correct episode from a batch of episodes when given a specific query, e.g., ranking the correct pair above all others.

The model achieves this by embedding similar (query, episode) pairs as closely as possible in a vector space. We measure the proximity of these embeddings using cosine similarity, which is essentially the angle between embeddings (e.g., vectors).
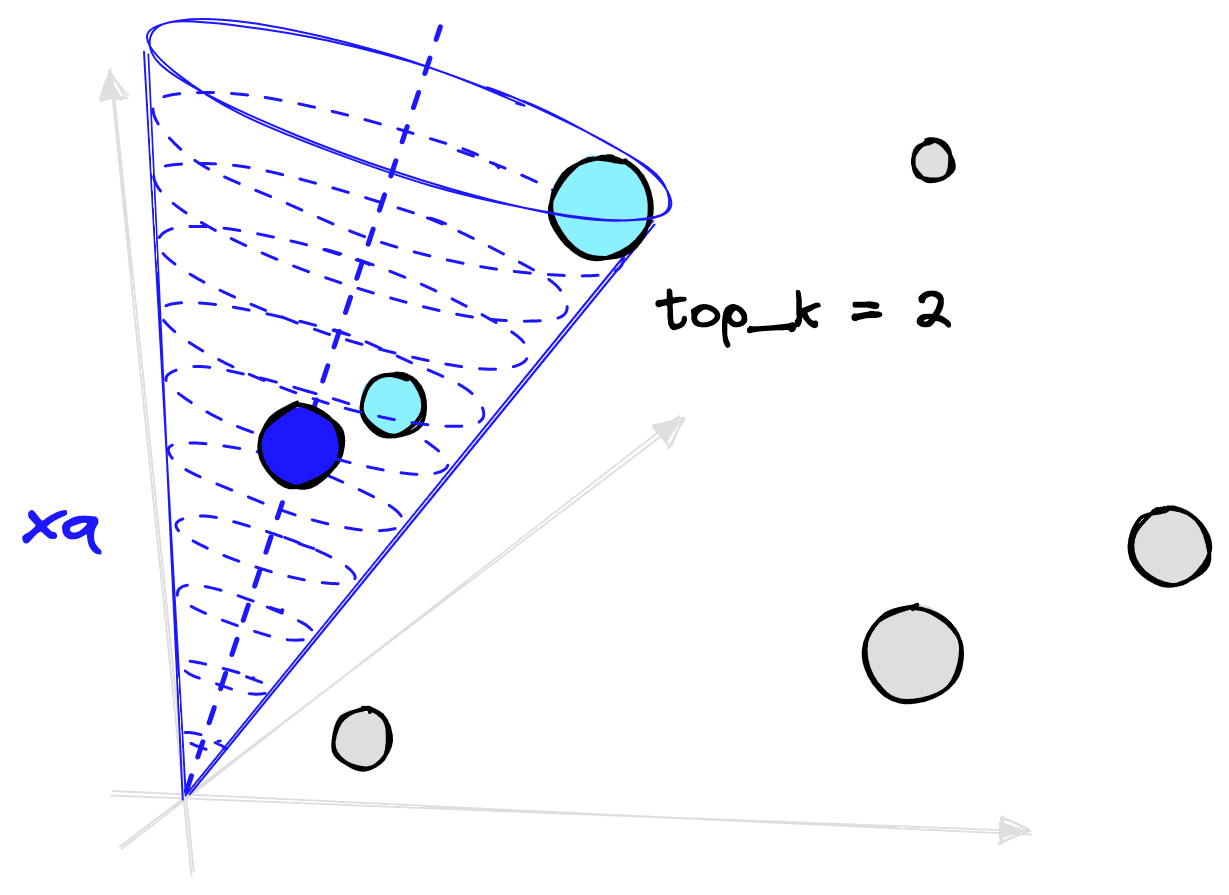
As we are using a ranking optimization function, we must make sure no duplicate queries or episodes are placed in the same training batch. If there are duplicates, this will confuse the training process as the model will be told that despite two queries/episodes being identical, one is correct, and the other is not.
The sentence-transformers library handles the duplication issue using the NoDuplicatesDataLoader. As the name would suggest, this data loader ensures no duplicates make their way into a training batch.
We initialize the data loader with a batch_size parameter. A larger batch size makes the ranking task harder for the model as it must identify one correct answer from a higher number of options.
It is harder to choose an answer from a hundred samples than from four samples. With that in mind, a higher batch_size tends to produce higher performance models.
from sentence_transformers.datasets import NoDuplicatesDataLoader
batch_size = 64
loader = NoDuplicatesDataLoader(train, batch_size=batch_size)
Now we initialize the loss function. As we’re using ranking, we choose the MultipleNegativesRankingLoss, typically called MNR loss.
from sentence_transformers.losses import MultipleNegativesRankingLoss
loss = MultipleNegativesRankingLoss(model)
In-Batch Evaluation
Spotify describes two evaluation steps. The first can be implemented before fine-tuning using in-batch metrics. What they did here was calculate two metrics at the batch level (using 64 samples at a time in our case); those are:
- Recall@k tells us if the correct answer is placed in the top k positions.
- Mean Reciprocal Rank (MRR) calculates the average reciprocal rank of a correct answer.
We will implement a similar approach to in-batch evaluation. Using the sentence-transformers RerankingEvaluator, we can calculate the MRR score at the end of each training epoch using our evaluation data, eval_pairs.
Before initializing this evaluator, we need to remove duplicates from the eval data.
dedup_eval_pairs = []
seen_eps = []
for (query, episode) in eval_pairs:
if episode not in seen_eps:
seen_eps.append(episode)
dedup_eval_pairs.append((query, episode))
eval_pairs = dedup_eval_pairs
print(f"{len(eval_pairs)} unique eval pairs")1001 unique eval pairs
Then, we reformat the data into a list of dictionaries containing a query, its positive episode (that it is paired with), and then all other episodes as negatives.
from sentence_transformers.evaluation import RerankingEvaluator
# we must format samples into a list of:
# {'query': '<query>', 'positive': ['<positive>'], 'negative': [<all negatives>]}
eval_set = []
eval_episodes = [pair[1] for pair in eval_pairs]
for i, (query, episode) in enumerate(eval_pairs):
negatives = eval_episodes[:i] + eval_episodes[i+1:]
eval_set.append(
{'query': query, 'positive': [episode], 'negative': negatives}
)
evaluator = RerankingEvaluator(eval_set, mrr_at_k=5, batch_size=batch_size)
We set the MRR@5 metric, meaning if the positive episode is returned within the top five results, we return a positive score. Otherwise, the score would be zero.
If the correct episode appeared at position three, the reciprocal rank of this sample would be calculated as 1/3. At position one we would return 1/1.
As we’re calculating the mean reciprocal rank, we take all sample scores and compute the mean, giving us our final MRR@5 score.
Using our evaluator, we first calculate the MRR@5 performance without any fine-tuning.
evaluator(model, output_path='./')0.6827534406474566Returning an MRR@5 of 0.68, we will compare this to the post-training MRR@5 score.
Fine-Tuning
With our evaluator ready, we can fine-tune our model. The Spotify article doesn’t give any information about the parameters they used, so we will stick with pretty typical training parameters for sentence transformer models using MNR loss. We train for a single epoch and “warm up” the learning rate for the first 10% of training steps.
epochs = 1
warmup_steps = int(len(loader) * epochs * 0.1)
model.fit(
train_objectives=[(loader, loss)],
evaluator=evaluator,
epochs=epochs,
warmup_steps=warmup_steps,
output_path='distiluse-podcast-nq',
show_progress_bar=True
)100%|██████████| 1/1 [02:12:13<00:00]After fine-tuning, the model will be saved into the directory specified by output_path. In distiluse-podcast-nq, we will see all the required model files and a directory called eval. Here, we will find a post-training MRR@5 score of 0.89, a sizeable 21-point improvement from the previous MRR@5 of 0.68.
This score looks promising, but there’s further evaluation to be performed.
Evaluation
We want to emulate a more real-world scenario for the final evaluation step. Rather than calculating MRR@5 across small batches of data (as done previously), we should index many episodes and recalculate some retrieval metrics.
Spotify details their full-retrieval setting metrics as using Recall@30 and MRR@30, performed both on queries from the eval set and on their curated dataset.
Our eval set is small, so we can discard that. Instead, we will use the much larger test set test_pairs.
As before, we must deduplicate the episodes from the dataset.
dedup_test_pairs = []
seen_eps = []
for (query, episode) in test_pairs:
if episode not in seen_eps:
seen_eps.append(episode)
dedup_test_pairs.append((query, episode))
test_pairs = dedup_test_pairs
print(f"{len(test_pairs)} unique test pairs")18579 unique test pairs
This time, rather than keeping all of our embeddings stored in memory, we use a vector database, Pinecone.
We first sign up for a free account, enter the default project and retrieve the default API key.
Back in Python, we ensure the Pinecone client is installed with pip install pinecone-client. Then we initialize our connection to Pinecone and create a new vector index.
import pinecone
pinecone.init(
api_key='YOUR_API_KEY', # app.pinecone.io
environment='YOUR_ENV' # find next to API key in console
)
# check if an evaluation index already exists, if not, create it
if 'evaluation' not in pinecone.list_indexes():
pinecone.create_index(
'evaluation', dimension=model.get_sentence_embedding_dimension(),
metric='cosine'
)
# now connect to the index
index = pinecone.Index('evaluation')
The vector index is where we will store all of our episode embeddings. We must encode the episode text using our fine-tuned distiluse-podcast-nq model and insert the embeddings into our index.
to_upsert = []
queries = []
eps_batch = []
id_batch = []
upsert_batch = 64
for i, (query, episode) in enumerate(tqdm(test_pairs)):
# create batch
queries.append((query, str(i)))
eps_batch.append(episode)
id_batch.append(str(i))
# on reaching batch_size we encode and upsert
if len(eps_batch) == upsert_batch:
embeds = model.encode(eps_batch).tolist()
# insert to index
index.upsert(vectors=list(zip(id_batch, embeds)))
# refresh batch
eps_batch = []
id_batch = []
Short on time? Download the fine-tuned model using model = SentenceTransformer('pinecone/distiluse-podcast-nq').
We will calculate the Recall@K score, which differs slightly from the MRR@K metric as if the match appears in the top K returned results, we score 1; otherwise, we score 0. As before, we take all query scores and compute the mean.
recall_at_k = []
for (query, i) in queries:
# encode the query to an embedding
xq = model.encode([query]).tolist()
res = index.query(xq, top_k=30)
# get IDs
ids = [x['id'] for x in res['results'][0]['matches']]
recall_at_k.append(1 if i in ids else 0)sum(recall_at_k)/len(recall_at_k)0.883309112438775So far, this looks great; 88% of the time, we are returning the exact positive episode within the top 30 results. But this does assume that our synthetic queries are perfect, which they are not.
We should measure model performance on more realistic queries, as Spotify did with their curated dataset. In this example, we have chosen a selection of episodes and manually written queries that fit the episode.
curated = {
"funny show about after uni party house": 1,
"interview with cookbook author": 8,
"eat better during xmas holidays": 14,
"superhero film analysis": 27,
"how to tell more engaging stories": 33,
"how to make money with online content": 34,
"why is technology so addictive": 38
}
Using these curated samples, we returned a lower score of 0.57. Compared to 0.88, this seems low, but we must remember that there are likely other episodes that fit these queries. Meaning, we’re calculating recall assuming there are no other relevant queries.
What we can do is: measure this score against the score of the model before fine-tuning. We create a new Pinecone index and replicate the same steps but using the distiluse-base-multilingual-cased-v2 sentence transformer. You can find the full script here.
Using this model, we return a score of just 0.29. By fine-tuning the model on this episode data, despite having no query pairs, we have improved episode retrieval performance by 28-points.
The technique we followed, informed by Spotify’s very own semantic search implementation, produced significant performance improvements.
Could this performance be better? Of course! Spotify fine-tuned their model using three data sources. We can assume that the first two of those, pulled from Spotify’s past search logs, are of much higher quality than our synthetic dataset.
Merging the approach we have taken with a real dataset, as done by Spotify, is almost certain to produce a significantly higher-performing model.
The world of semantic search is already huge, but what is perhaps more exciting is the potential of this field. We will continue seeing new examples of semantic search, like Spotify’s podcast search, applied in many interesting and unique ways.
If you’re using Pinecone for semantic search and are interested in showcasing your project, let us know! Comment them below or email them to us at info@pinecone.io.
Resources
[1] Podcast Content is Growing Audio Engagement (2020), Nielsen
[2] S. Lebow, Spotify Poised to Overtake Apple Podcasts This Year (2021), eMarketer
[3] A. Tamborrino Introducing Natural Language Search for Podcast Episodes (2022), Engineering at Spotify Blog
[4] O. Sharir, B. Peleg, Y. Shoham, The Cost of Training NLP Models (2020)
[5] N. Reimers, I. Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019), EMNLP
Was this article helpful?