How Nyckel Built An API for Semantic Image Search
Written by George Mathew, Co-Founder at Nyckel.
Businesses that accumulate large amounts of data eventually run into problems with information retrieval – especially if they’re working with image data. While information retrieval for text is mostly a solved problem, the same cannot be said for images. Recent advances in deep neural networks and in vector search databases make it possible to search through large sets of images. Nyckel implements a simple API for semantic image search – let’s look deeper at how it is implemented.
What is semantic image search?
Semantic search is the ability to search based on user intent and on the contextual meaning of both the search query and the target content. For images, this means understanding the meaning of search queries (whether in the form of text or images), and then mapping them to images in the search set. This is exactly what Google’s image search engine does. I could use a picture of my dog catching a frisbee on the beach, paste it into Google reverse image search, and it would retrieve public web images that are similar to my picture. Alternatively, I could use the more common means of Google searching by typing in “dog catching a frisbee on the beach”, and Google will retrieve public web images that match those search terms. The latter search case is called a cross-modal search because the search term and the result item are in different modalities: in this case, text and image respectively.

Applications of Image Search
As a platform, we are constantly surprised and encouraged by the variety of use-cases we see. Here are a few examples of applications that our customers are using our image search API for:
- Detecting the unauthorized use of images, e.g., copyright infringement or fraud;
- De-duplicating images in a collection when the duplicates are not exact matches;
- Image classification into hundreds of thousands of classes where traditional classification mechanisms are difficult;
- Enabling search functionality over their images for their end-customers or employees. To showcase this, we built a demo app to search over the wild world of NFT images:
Nyckel’s Image Search Service
Nyckel is the lightning fast ML-platform for non-experts. We make ML functionality, such as image / text classification, object detection, and image search, accessible to developers and companies without any ML expertise.
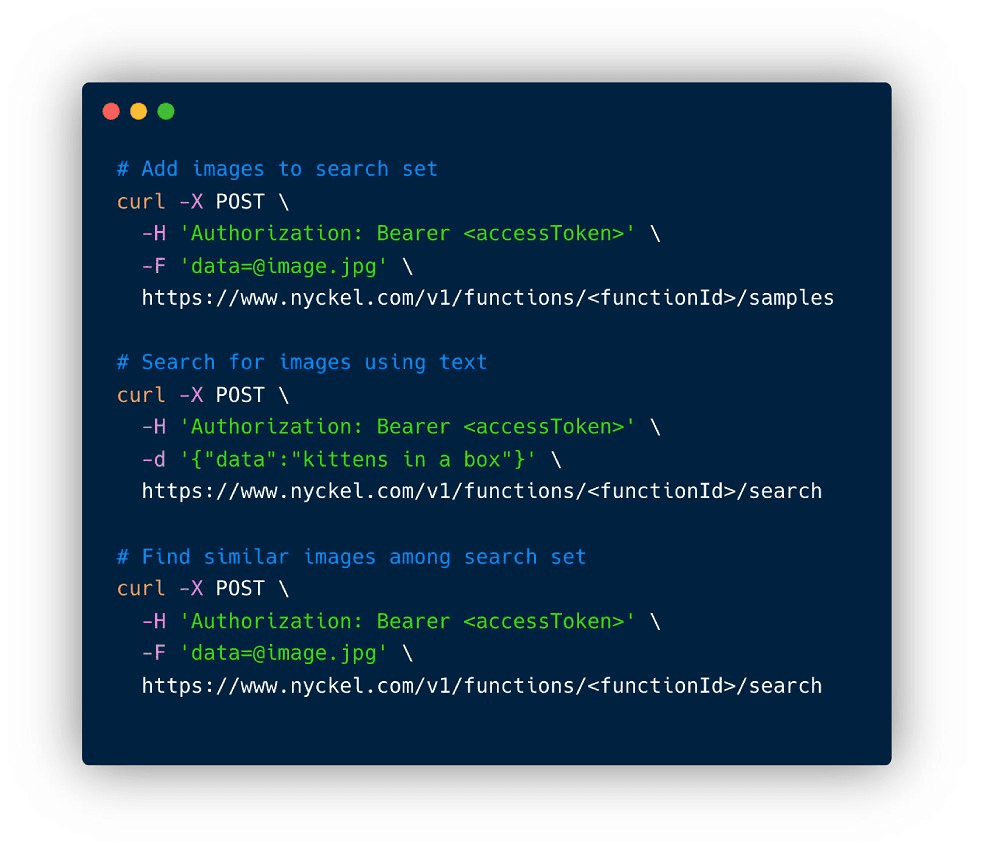
For image search, our customers don’t want to deal with model selection, tuning, deployment, and infrastructure management and scaling. They use the following simple API, and we take care of the rest:
What goes into implementing the API?
Searching within any medium requires two capabilities:
- Extracting semantic information from the data – both the search set and query data;
- Indexing the semantic information for fast and accurate retrieval.
Extracting Semantic Information from Images
Neural networks, such as Resnet, are good at extracting a semantic representation of an image in the form of “embeddings”: fixed-length vectors of floating point numbers. Once you have a set of images that have been mapped in this way, then you can use your vector database to index the vector embeddings. If two images have similar embeddings, meaning that they are close to one another in vector space, then they are semantically similar. Conversely, the embeddings for two dissimilar images will be far apart in vector space. You can read more about embeddings and how useful they are in Peter Gao’s blog post.
But what about cross-modal semantic search, for example when queries for image data come in the form of textual descriptions? What do we do in these cases? We could use a natural language model like BERT to get text embeddings, but these embeddings will be unrelated to the image embeddings. What this means is that the embedding for “dog catching a frisbee on the beach” is not guaranteed to be close to the embedding for an image of a dog catching a frisbee on the beach. In the next section we’ll talk about how to solve this problem.
Cross-Modal Embeddings
In order to support searching for images with a text query, we need a neural network that can provide embeddings for images and text in the same “embedding space”. OpenAI’s CLIP is one such network. It’s actually two networks: one for images and one for text, trained together to minimize “contrastive loss”. CLIP is trained on a large corpus of (image, text) pairs from the internet. With the idea that (image, text) pairs that accompany each other are likely to be semantically similar, the training objective was to minimize the distance between vector embeddings for pairs that accompany each other and maximize the distance between embeddings for unrelated pairs. You can read more about CLIP here.
The result is that CLIP’s embeddings for an image of a dog catching a frisbee on the beach, and the text “dog catching frisbee on beach” will be close together. This gives us the embeddings we need for cross-modal search.
Indexing
Once you have embeddings, searching for images becomes a problem of finding the closest vectors to the embedding for that particular query. Finding the closest vectors is a computationally challenging problem for large numbers of high-dimensional vectors. But there are relatively efficient mechanisms for finding approximate closest matches (commonly known as approximate nearest neighbors, or ANN) and several vector-database products that offer this capability. We evaluated several vector databases and picked pinecone because they are a fully managed service with low ingest latency, low query latency, on-demand and scalable provisioning and pricing, and an easy-to-use API.
Putting it together
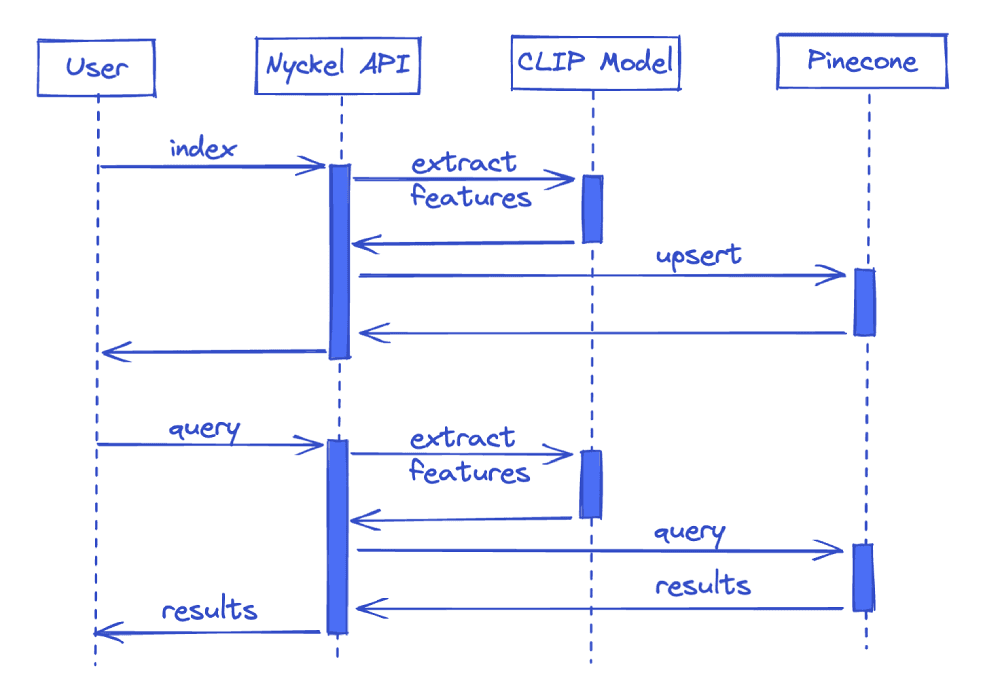
Now that we’ve talked about all the pieces involved in semantic image search, let’s look at how Nyckel puts them together for its image search service. The sequence diagram below ignores some of the complexities and asynchronous processing, but provides a general overview of how things work:
Future work
What we’ve described above is just the beginning and we have an exciting roadmap for image search. Here are a couple of items items on our to-do list:
- Support multilingual text queries. CLIP currently only does well with English queries, and we want to support many more languages;
- Model selection and fine-tuning for specialized use-cases based on search feedback. CLIP does surprisingly well for a wide range of subject matter, but in cases where the set of images is in a very narrow or specialized domain, model fine-tuning will help provide significantly better search results.
Was this article helpful?