Unsupervised Training of Retrievers Using GenQ
Fine-tuning effective dense retrieval models is challenging. Bi-encoders (sentence transformers) are the current best models for dense retrieval in semantic search. Unfortunately, they’re also notoriously data-hungry models that typically require a particular type of labeled training data.
Hard problems like this attract attention. As expected, there is plenty of attention on building ever better techniques for training retrievers.
One of the most impressive is GenQ. This approach to building bi-encoder retrievers uses the latest text generation techniques to synthetically generate training data. In short, all we need are passages of text. The generation model then augments these passages with synthetic queries, giving us the exact format we need to train an effective bi-encoder model.
GenQ Method
Let’s work through the details of this training method. At a high level, there are two key steps.
- Generate queries for pre-existing but unlabeled passages: Creating (query, passage) pairs.
- Fine-tune a bi-encoder model using these (query, passage) pairs and Multiple Negatives Ranking (MNR) loss.
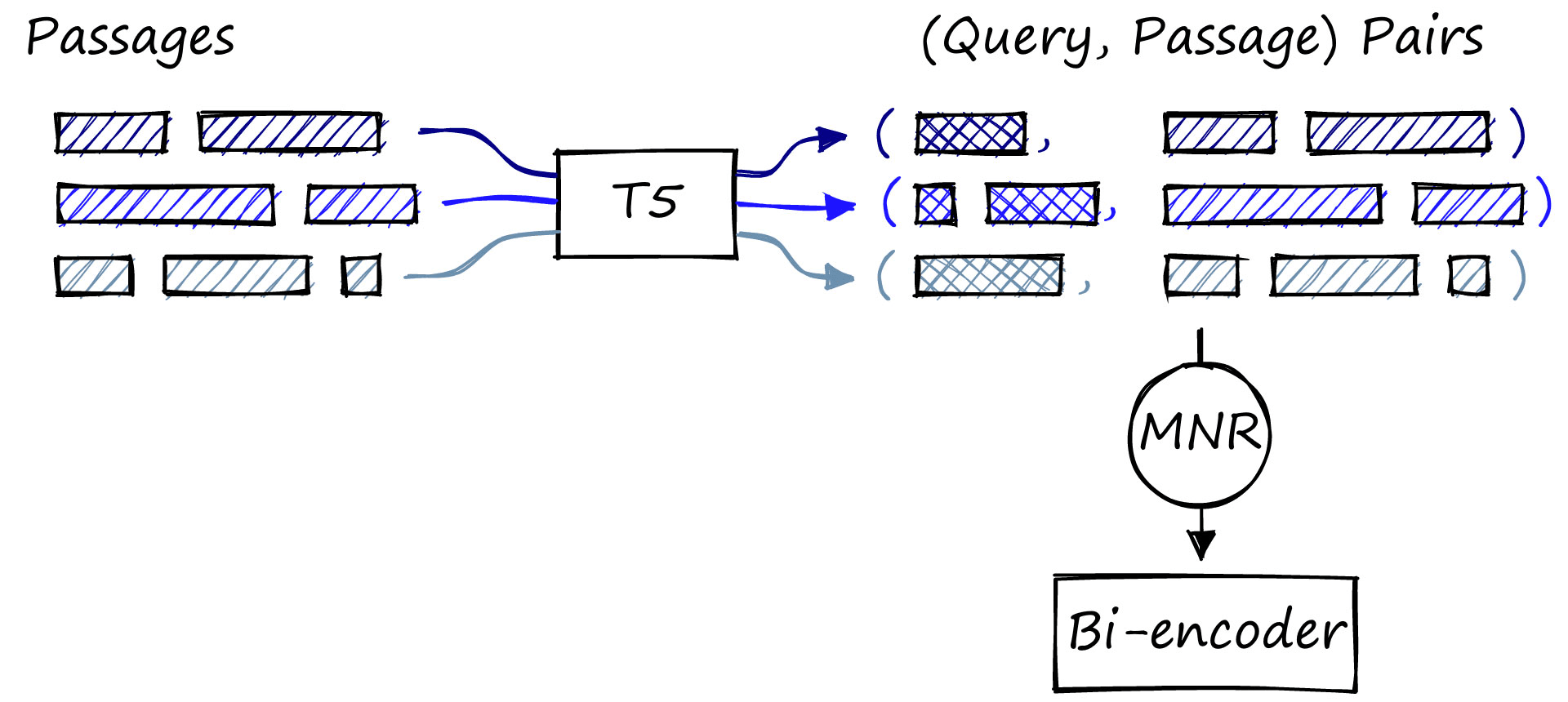
Don’t worry if any (or even all) of the above doesn’t make sense. We’ll detail everything from start to finish.
Unlabeled Passages
We can describe data as either being in-domain or belonging to another domain. The domain here refers to the target data and use-case where we apply the eventual fine-tuned bi-encoder model.
For example, we may want to build a retriever model that encodes sentences (passages) for financial documents in German. In that case, any text from German financial documents is in-domain, and everything else is out-of-domain.
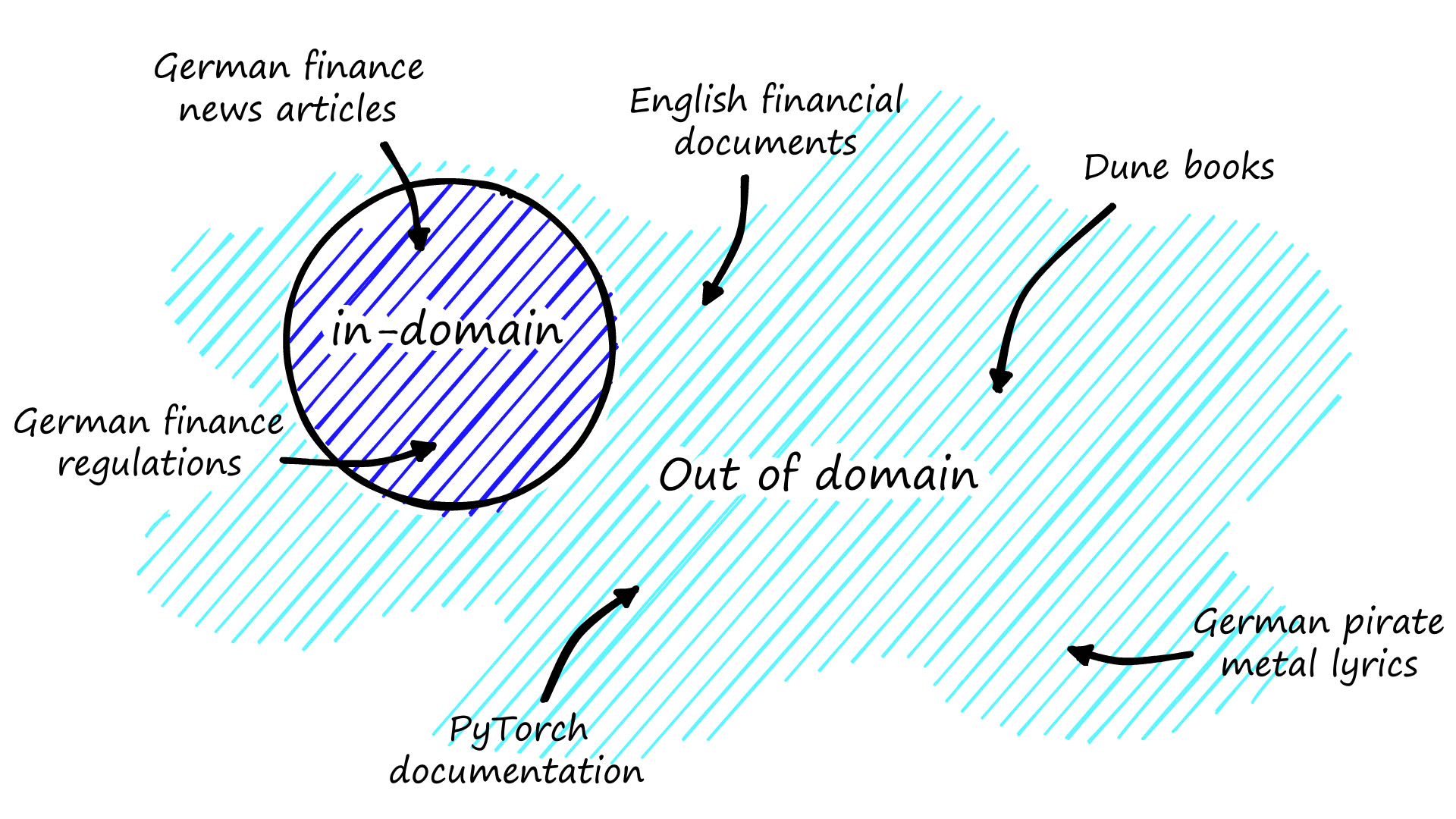
To achieve good performance with a language model (LM), we need to train (fine-tune) it on in-domain data. We would typically need a lot of labeled in-domain data to fine-tune a bi-encoder.
For most domains, we can either have a lot of unlabeled data or a little labeled data. It’s hard to get both, and most bi-encoder training needs both.
GenQ aims to break the reliance on requiring labeled data by synthetically generating queries for otherwise unlabeled passages of text. Producing (query, passage) pairs from an unlabeled dataset. That means that given a large, in-domain, but unlabeled dataset, we can train with GenQ.
The task that GenQ is designed for is referred to as asymmetric semantic search [3]. That means the query is much shorter than the passage we would aim to retrieve. A typical query may consist of (for example) six words “How do I tie my shoelaces?", and the relevant passage can be much longer:
“To tie your shoelaces, take both laces and place one over the other, pulling them tightly together…"
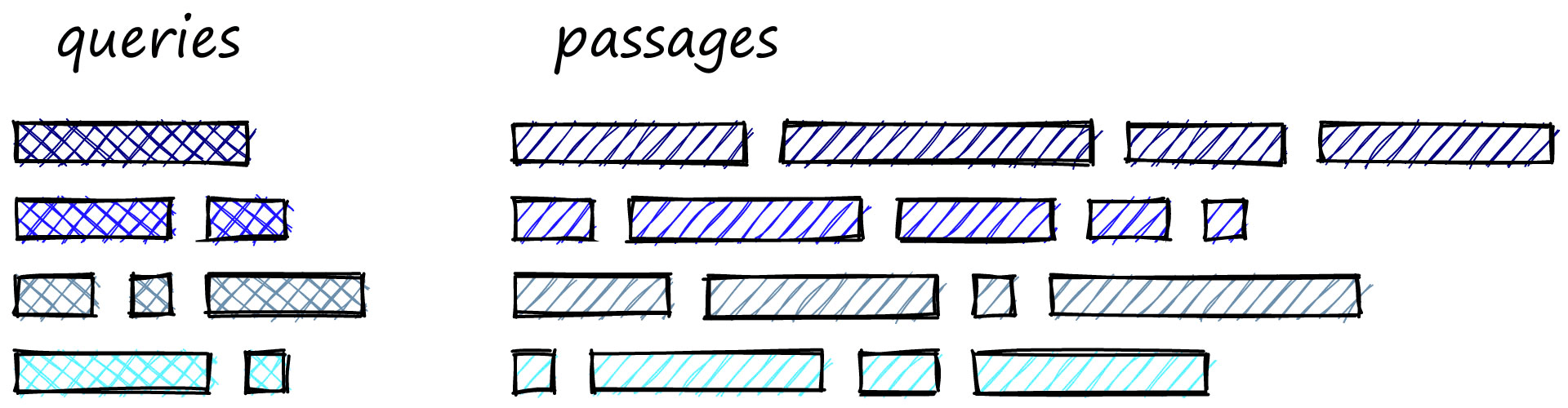
It is this task, with asymmetry between queries and passages, where GenQ can be applied.
Generation of Queries
We need passages and a query generation model to generate the (query, passage) pairs. The model used by GenQ is the Text-to-Text Transfer Transformer (T5).
The T5 model philosophy is that all NLP tasks can be defined as a text-to-text problem, so they are pretrained on many different tasks with vast amounts of data.
![T5 views every task as a text-to-text problem. Here are a few examples adapted from the paper that introduced T5 [4].](/_next/image/?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fvr8gru94%2Fproduction%2F51f1d1adf73884bde48eb7f54e6baa29f75b8840-1920x560.png&w=3840&q=75)
One of these tasks is query generation. In this case, the input text, or passage, is fed into a special query generation T5 model that generates questions that the passage may answer [2].
Given a large corpus of passages, such as paragraphs scraped from documentation, web pages, etc. We use T5 to generate several queries for each passage.
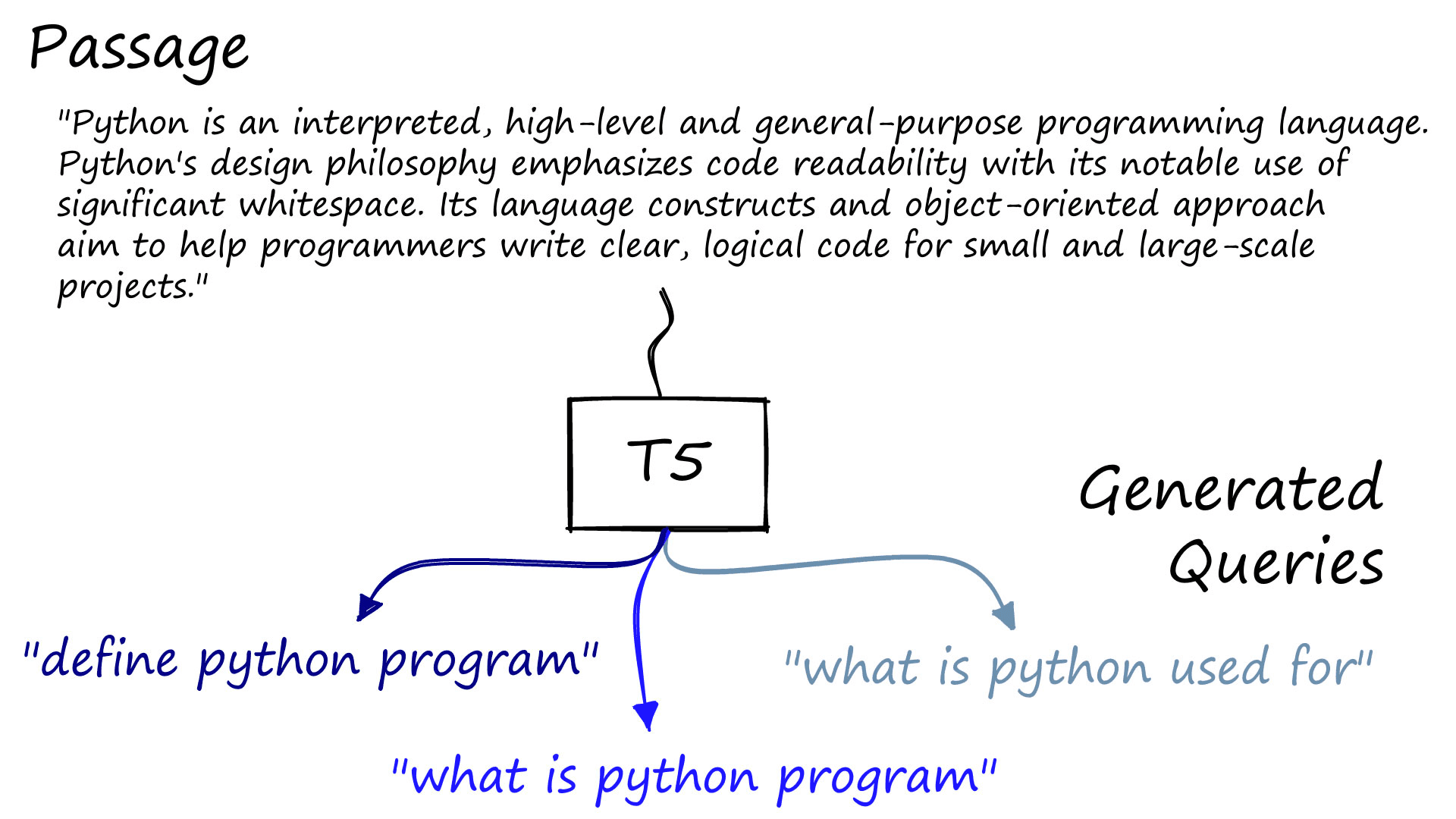
It’s important to note that query generation is not perfect. We’re using a general-purpose T5 model. The queries it generates can be noisy with plenty of randomness and nonsensical queries. Because of that, GenQ is prone to poor performance where the synthetic data is too noisy [1].
We have what should be a very large dataset of (query, passage) pairs. With this data, we can move on to fine-tuning the bi-encoder model.
Fine-Tuning the Bi-Encoder
To fine-tune the bi-encoder (sentence transformer) we use Multiple Negatives Ranking (MNR) loss. MNR loss is ideal for training where our dataset consists of pairs of related sentences.
For example, when training a QA retriever model, we can train with MNR loss if we have sets of (question, answer) pairs. If we have a Natural Language Inference (NLI) dataset, we can use MNR loss to train on (anchor, positive) pairs. In this case, we fine-tune on (query, passage) pairs.
MNR loss works by placing all of these pairs into batches. For each batch, the model is optimized so that pair (Qi, Pj=i) has the highest similarity. Meaning that within a batch of 32, the similarity score between Qi=3 and Pj=3 must be higher than the similarity between Qi=3 and any other passage Pj≠3.
At the end of this training process, we have a new bi-encoder fine-tuned to a specific domain. The model’s performance can vary depending on the models being used, source and target domains, and many other variables. However, GenQ can sometimes achieve performances approaching models trained with supervised methods [1].
Let’s move on to the implementation of GenQ.
Implementation Walkthrough
First, we need a dataset to train on. We will take the context paragraphs from the Stanford Question and Answering Dataset (SQuAD) dataset, which we will download from HuggingFace Datasets.
from datasets import load_dataset
squad = load_dataset(
'squad',
split='train'
)
squad[0]{'id': '5733be284776f41900661182',
'title': 'University_of_Notre_Dame',
'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary...
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
'answers': {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]}}In this dataset, we already have query 'question' and passage 'context' pairs. However, we want to emulate the scenario in which we do not have queries. We will remove all but the 'context' data to do that.
passages = list(set(squad['context']))
len(passages)18891Now that we have our passages, we can begin generating queries. For this, we need a query generation model. We will use a T5 model fine-tuned for query generation as part of the BeIR project, named BeIR/query-gen-msmarco-t5-large-v1.
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('BeIR/query-gen-msmarco-t5-large-v1')
model = T5ForConditionalGeneration.from_pretrained('BeIR/query-gen-msmarco-t5-large-v1')
model.eval()Some layers in the model behave differently during training and inference. To ensure the model is running in “inference mode”, we call model.eval().
import torch
from tqdm.auto import tqdm
pairs = []
file_count = 0
# set to no_grad as we don't need to calculate gradients for back prop
with torch.no_grad():
# loop through each passage individually
for p in tqdm(passages):
p = p.replace('\t', ' ')
# create input tokens
input_ids = tokenizer.encode(p, return_tensors='pt')
# generate output tokens (query generation)
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=3
)
# decode output tokens to human-readable language
for output in outputs:
query = tokenizer.decode(output, skip_special_tokens=True)
# append (query, passage) pair to pairs list, separate by \t
pairs.append(query.replace('\t', ' ')+'\t'+p)
# once we have 1024 pairs write to file
if len(pairs) > 1024:
with open(f'data/pairs_{file_count}.tsv', 'w', encoding='utf-8') as fp:
fp.write('\n'.join(pairs))
file_count += 1
pairs = []
if pairs is not None:
# save the final, smaller than 1024 batch
with open(f'data/pairs_{file_count}.tsv', 'w', encoding='utf-8') as fp:
fp.write('\n'.join(pairs))With this, the model will generate three queries for each passage. In this case, we generate 56,673 pairs from 18,891 passages and save them as TSV files.
We can see that the queries are generally much smaller than the passages; this is where the asymmetric in asymmetric similarity search comes from.
print("Paragraph:")
print(para)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')Paragraph:
Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.
Generated Queries:
1: define python program
2: what is python used for
3: what is python program
The next step is to fine-tune a model using MNR loss. We do this easily with the sentence-transformers library.
We start by loading the pairs dataset we created into a list of InputExample objects.
from pathlib import Path
paths = [str(path) for path in Path('data').glob('*.tsv')]
paths[:5]['data\\pairs_0.tsv',
'data\\pairs_1.tsv',
'data\\pairs_10.tsv',
'data\\pairs_11.tsv',
'data\\pairs_12.tsv']from sentence_transformers import InputExample
from tqdm.auto import tqdm
pairs = []
for path in tqdm(paths):
with open(path, 'r', encoding='utf-8') as fp:
lines = fp.read().split('\n')
for line in lines:
if '\t' not in line:
continue
else:
q, p = line.split('\t')
pairs.append(InputExample(
texts=[q, p]
))100%|██████████| 56/56 [00:00<00:00, 176.00it/s]
Next, we load the pairs into a NoDuplicatesDataLoader. We use the no duplicates data loader to avoid placing duplicate passages in the same batch, as this will confuse the ranking mechanism of MNR loss.
from sentence_transformers import datasets
batch_size = 24
loader = datasets.NoDuplicatesDataLoader(
pairs, batch_size=batch_size
)Now we initialize the bi-encoder that we will be fine-tuning. We create the transformer-to-pooler architecture using modules.
from sentence_transformers import models, SentenceTransformer
mpnet = models.Transformer('microsoft/mpnet-base')
pooler = models.Pooling(
mpnet.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True
)
model = SentenceTransformer(modules=[mpnet, pooler])
modelSentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)Here we are initializing from a pretrained MPNet model, which by default outputs 512 embeddings. The second module is a mean pooling layer that takes the average activations across all of these embeddings to create a single sentence embedding.
With this, our bi-encoder is initialized. We now need to fine-tune the model, which we do using MNR loss.
from sentence_transformers import losses
loss = losses.MultipleNegativesRankingLoss(model)Everything is now in place, and we fine-tune the model by calling the fit method.
epochs = 3
warmup_steps = int(len(loader) * epochs * 0.1)
model.fit(
train_objectives=[(loader, loss)],
epochs=epochs,
warmup_steps=warmup_steps,
output_path='mpnet-genq-squad',
show_progress_bar=True
)Iteration: 100%|██████████| 2361/2361 [12:59<00:00, 3.03it/s]
Iteration: 100%|██████████| 2361/2361 [12:59<00:00, 3.03it/s]
Iteration: 100%|██████████| 2361/2361 [12:58<00:00, 3.03it/s]
Epoch: 100%|██████████| 3/3 [38:57<00:00, 779.11s/it]
We now have a fine-tuned bi-encoder that we can use for asymmetric semantic search. Let’s move on to setting up a search index and testing a few searches to see what we return.
Evaluation
For evaluation, we will work through a simple qualitative test. We take a few example questions from the SQuAD validation set, and we will (hopefully) see that we are returning relevant contexts.
We can use Pinecone as an ultra-fast way to store our vectors. All we need is an API key and to install the Pinecone client with pip install pinecone-client. To initialize our connection to Pinecone and create an index to store the vectors we write:
import pinecone
pinecone.init(
api_key='YOUR_API_KEY',
environment='YOUR_ENV' # find next to API key
)
# create a new genq index if does not already exist
if 'genq' not in pinecone.list_indexes():
pinecone.create_index(
'genq',
dimension=model.get_sentence_embedding_dimension()
)
# connect
index = pinecone.Index('genq')The vector database will store all encoded contexts from the SQuAD validation set, so let’s download, encode, and upsert our contexts.
To download, we use HuggingFace Datasets as before.
from datasets import load_dataset
squad = load_dataset('squad', split='validation')
squadDataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 10570
})We can now encode using our newly trained mpnet-genq-squad model.
# remove duplicate contexts
contexts = list(set(squad['context']))
len(contexts)2067embeds = []
for i in range(0, len(contexts), 32):
i_end = i + 32
i_end = len(contexts) if i_end > len(contexts) else i_end
# get the batch and encode
batch = contexts[i:i_end]
batch_embeds = model.encode(batch).tolist()
# add to our embeds list
embeds.extend(batch_embeds)
len(embeds)2067And finally upsert to Pinecone.
ids = [str(i) for i in range(len(contexts))]
meta = [{'context': context} for context in contexts]
to_upsert = list(zip(ids, embeds, meta))
# now upsert
for i in range(0, len(contexts), 32):
i_end = i + 32
i_end = len(contexts) if i_end > len(contexts) else i_end
# get batch
batch = to_upsert[i:i_end]
# upsert
index.upsert(vectors=batch)We’re now ready to begin querying; we can take a few example queries from SQuAD.
query = "Who are the Normans"
xq = model.encode([query]).tolist()
res = index.query(xq, top_k=5, include_metadata=True)res{'results': [{'matches': [{'id': '2036',
'metadata': {'context': 'The Normans (Norman: '
'Nourmands; French: '
'Normands; Latin: Normanni) '
'were the people who in the '
'10th and 11th centuries '
'gave their name to '
'Normandy, a region in '
'France...'},
'score': 0.817228794,
'values': []},
{'id': '382',
'metadata': {'context': 'The Normans thereafter '
'adopted the growing feudal '
'doctrines of the rest of '
'France, and worked them '
'into a functional '
'hierarchical system in '
'both Normandy and in '
'England...'},
'score': 0.737579226,
'values': []},
{'id': '1004',
'metadata': {'context': 'The Norman dynasty had a '
'major political, cultural '
'and military impact on '
'medieval Europe and even '
'the Near East...'},
'score': 0.737287879,
'values': []},
{'id': '1444',
'metadata': {'context': 'The English name "Normans" '
'comes from the French '
'words Normans/Normanz, '
'plural of Normant, modern '
'French normand, which is '
'itself borrowed from Old '
'Low Franconian...'},
'score': 0.734762728,
'values': []},
{'id': '693',
'metadata': {'context': 'Soon after the Normans '
'began to enter Italy, they '
'entered the Byzantine '
'Empire and then Armenia, '
'fighting against the '
'Pechenegs, the Bulgars, '
'and especially the Seljuk '
'Turks...'},
'score': 0.729910612,
'values': []}],
'namespace': ''}]}We immediately return the best possible answer as the highest rated passage. Let’s try with some more SQuAD queries.
query = "Besides Death Wish Coddee, how many other competitors participated in the contest?"
xq = model.encode([query]).tolist()
res = index.query(xq, top_k=5, include_metadata=True)res{'results': [{'matches': [{'id': '1294',
'metadata': {'context': 'QuickBooks sponsored a '
'"Small Business Big Game" '
'contest, in which Death '
'Wish Coffee had a '
'30-second commercial aired '
'free of charge courtesy of '
'QuickBooks...'},
'score': 0.411927342,
'values': []},
{'id': '444',
'metadata': {'context': 'It has won the Short Form '
'of the Hugo Award for Best '
'Dramatic Presentation, the '
'oldest science '
'fiction/fantasy award for '
'films and series, six '
'times (every year since '
'2006, except for 2009, '
'2013 and 2014)...'},
'score': 0.343265235,
'values': []},
{'id': '934',
'metadata': {'context': 'In honor of the 50th Super '
'Bowl, the pregame ceremony '
'featured the on-field '
'introduction of 39 of the '
'43 previous Super Bowl '
'Most Valuable Players...'},
'score': 0.337897182,
'values': []},
{'id': '231',
'metadata': {'context': 'In 1999, another special, '
'Doctor Who and the Curse '
'of Fatal Death, was made '
'for Comic Relief and later '
'released on VHS...'},
'score': 0.326049119,
'values': []},
{'id': '1330',
'metadata': {'context': 'For the third straight '
'season, the number one '
'seeds from both '
'conferences met in the '
'Super Bowl...'},
'score': 0.309723705,
'values': []}],
'namespace': ''}]}Another great result; let’s try one final query.
query = "How many full time teachers does Victoria have?"
xq = model.encode([query]).tolist()
res = index.query(xq, top_k=5, include_metadata=True)res{'results': [{'matches': [{'id': '645',
'metadata': {'context': 'As of August 2010, '
'Victoria had 1,548 public '
'schools, 489 Catholic '
'schools and 214 '
'independent schools...'},
'score': 0.76673764,
'values': []},
{'id': '633',
'metadata': {'context': 'Victorian schools are '
'either publicly or '
'privately funded. Public '
'schools, also known as '
'state or government '
'schools, are funded and '
'run directly by the '
'Victoria Department of '
'Education...'},
'score': 0.634226859,
'values': []},
{'id': '360',
'metadata': {'context': 'Many counties offer '
'alternative licensing '
'programs to attract people '
'into teaching, especially '
'for hard-to-fill '
'positions...'},
'score': 0.620759308,
'values': []},
{'id': '1913',
'metadata': {'context': 'Teaching in Canada '
'requires a post-secondary '
"degree Bachelor's Degree. "
'In most provinces a second '
"Bachelor's Degree such as "
'a Bachelor of Education is '
'required to become a '
'qualified teacher...'},
'score': 0.606571913,
'values': []},
{'id': '332',
'metadata': {'context': 'In the United States, each '
'state determines the '
'requirements for getting a '
'license to teach in public '
'schools...'},
'score': 0.574642718,
'values': []}],
'namespace': ''}]}All of these great results show that our model fine-tuned with GenQ has fit well to the SQuAD domain.
That’s it for this chapter covering the GenQ training method, a clearly powerful approach to fine-tuning models where we have limited datasets.
Using this approach, we can take passages of text, generate (query, passage) pairs, and use these pairs to train effective bi-encoder models ideal for asymmetric semantic search.
GenQ is an excellent, low-effort technique enabling projects that focus or rely on retrieving passages of text from natural language queries. Using GenQ you can begin fine-tuning models with limited data, unlocking previously inaccessible domains.
References
[1] J. Ma, et al., Zero-shot Neural Passage Retrieval via Domain-targeted Synthetic Question Generation (2021), ACL
[2] N. Reimers, GenQ Page, SBERT.net
[3] N. Reimers, et. al., Semantic Search Page, SBERT.net
[4] C. Raffel, et. al., Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (2020), JMLR
Was this article helpful?