“To make our newest Notion AI products available to tens of millions of users worldwide, we needed to support RAG over billions of documents while meeting strict performance, security, cost, and operational requirements. This simply wouldn’t be possible without Pinecone.” - Akshay Kothari, Co-Founder at Notion
We recently announced Pinecone serverless in public preview. With so much new content (including our announcement blog, a technical deep dive, and a study on RAG at scale), we wanted to break it down for you. This blog shares five reasons to start building with Pinecone serverless today.
Tl;dr: Pinecone serverless is a completely reinvented vector database that lets you easily build fast and accurate GenAI applications at up to 50x lower cost. Try it now with $100 in free usage credits.
1. Lower your costs im
Storing and searching through large amounts of vector data on-demand can be prohibitively expensive, even with a purpose-built vector database, and practically impossible using relational or NoSQL databases. Pinecone serverless solves this by letting you add practically unlimited knowledge to your GenAI applications at up to 50x lower cost compared to Pinecone pod-based indexes. This is driven by some of the key innovations behind our industry-first serverless architecture:
- Memory efficient retrieval: We designed our new serverless architecture to go beyond a scatter-gather query mechanism so only the necessary portions of the index are effectively loaded into memory from blob storage.
- Intelligent query-planning: Our retrieval algorithm scans only the relevant data segments needed for the query, not the entire index. (Quick tip: Reduce the data scanned by dividing your records into namespaces or indexes for faster, lower-cost queries.)
- Separation of storage and compute: Pricing is separated by reads (queries), writes, and storage. Separate pricing means 1) you don’t have to pay for compute resources when you’re not using them, and 2) you pay for exactly the storage used (i.e., the number of records you have), regardless of your query needs.
Whether you’re building an AI-powered chatbot or search application, Pinecone serverless can dramatically lower your costs. Many customers have already seen incredible savings from serverless, including Gong who has lowered their cost by 10x to power vector search over billions of embeddings.
The chart below (source) compares what it costs to query at high recall on the pod-based architecture vs Pinecone serverless across various datasets.
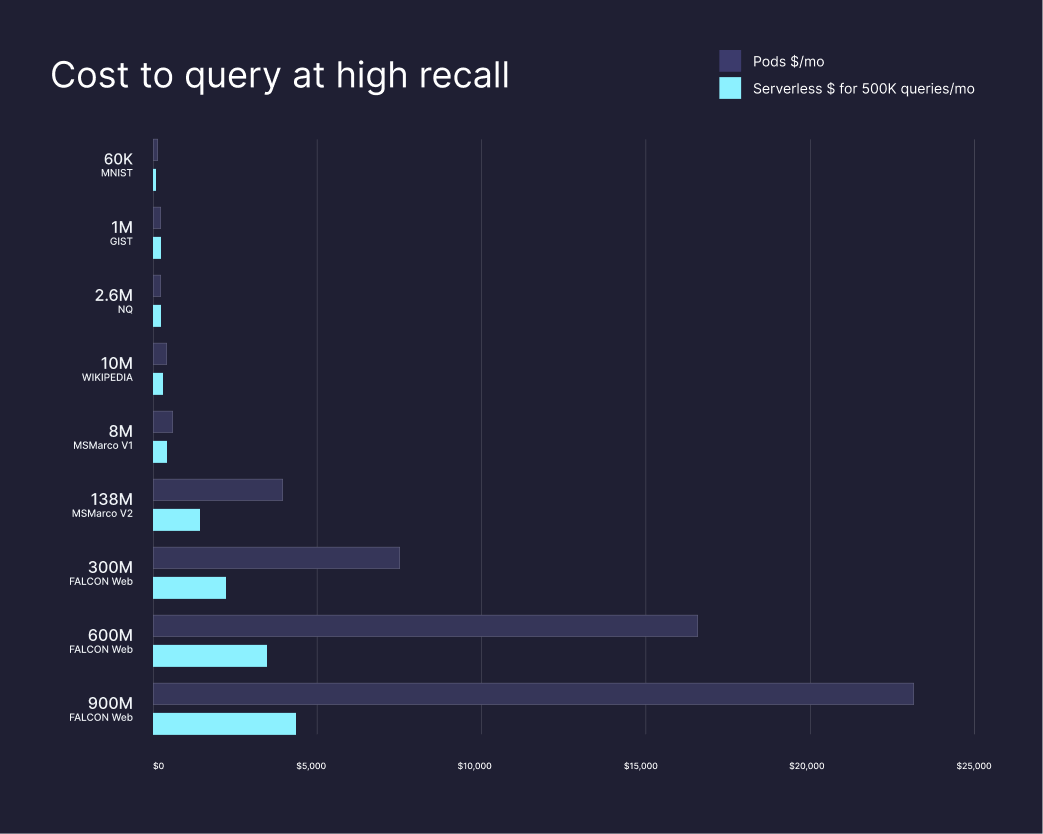
Learn more about our usage-based pricing, estimate your costs, and try serverless today to unlock $100 in credits. There is no minimum cost per index.
2. Forget about configuring or managing your index
With Pinecone serverless, we’ve made it even easier to get started and scale. As a truly serverless architecture, you don’t have to think about managing or scaling the database. There are no more pods or replicas to configure, or resources to shard and provision. Simply name your index, load your data, and start querying through the API or the client.
from pinecone import Pinecone, ServerlessSpec
# Create a serverless index
# "dimension" needs to match the dimensions of the vectors you upsert
pc = Pinecone(api_key="YOUR_API_KEY")
pc.create_index(name="products", dimension=1536,
spec=ServerlessSpec(cloud='aws', region='us-west-2')
)
# Target the index
index = pc.Index("products")
# Mock vector and metadata objects (you would bring your own)
vector = [0.010, 2.34,...] # len(vector) = 1536
metadata = {"id": 3056, "description": "Networked neural adapter"}
# Upsert your vector(s)
index.upsert(
vectors=[
{"id": "some_id", "values": vector, "metadata": metadata}
]
) Customers like Frontier Medicines have been able to increase efficiencies to meet levels of demand and performance that weren’t feasible before serverless.
"The introduction of Pinecone serverless has led to amazing performance and efficiency improvements in our vector search capability. We will continue to push forward searching billions of vectors with Pinecone serverless at the center.” - Johannes Hermann, Ph.D., CTO, Frontier Medicines
The new API also serves as a single endpoint to control all index operations from across your environments. See our example notebooks or how to build a Wikipedia chatbot to get started faster.
3. Make your applications more knowledgeable
We know that more relevant results make for better applications. And to get more relevant results, you need more data or knowledge in your vector database. In fact, our research on the impact of Retrieval Augmented Generation (RAG) shows that the more data you can search over, the more "faithful" (or factually correct) the results. Even with a billion-scale dataset, scaling up to include all the data improves performance no matter what LLM you choose. (source).
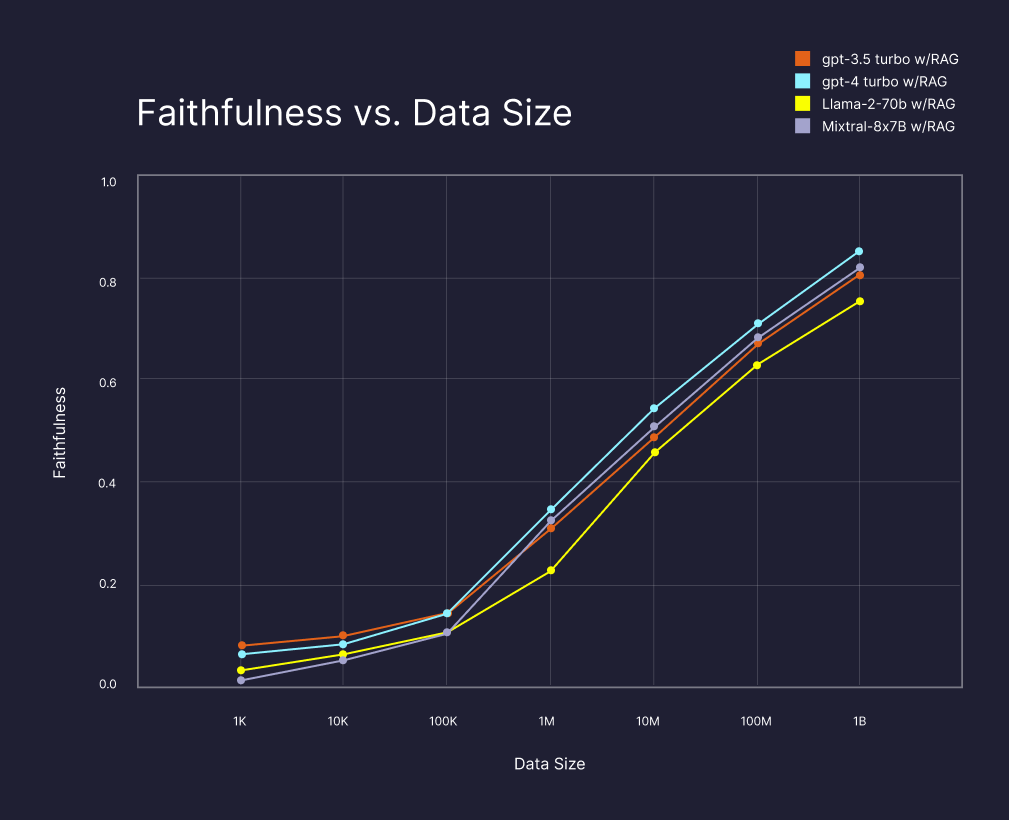
To build highly knowledgeable GenAI applications, developers need a vector database for searching through massive, ever-growing amounts of vector data, and Pinecone serverless provides just that. With serverless, companies can add practically unlimited knowledge to their applications.
Pinecone serverless also supports namespaces, live index updates, metadata filtering, and hybrid search so you get the most relevant results regardless of the type or size of your workload. Learn more about how our groundbreaking new architecture maintains performance at scale.
4. Connect to your favorite tools
Pinecone partnered with best-in-class GenAI solutions to provide a serverless experience that is the easiest to use. See how these partners — Anyscale, Cohere, Confluent, Langchain, Pulumi, and Vercel — can help you or your engineering team get started on serverless:
- Generate embeddings at 10% of the cost of other popular offerings with Anyscale.
- Scale semantic search systems with Pinecone serverless and Cohere’s Embed Jobs.
- Make real-time, cost-effective GenAI a reality with Confluent’s Pinecone Sink Connector.
- Build and deploy a RAG app with Pinecone serverless along with Langchain’s LangServe and LangSmith solutions.
- Easily maintain, manage, and reproduce infrastructure as code with the Pinecone Provider for Pulumi.
- See how RAG chatbots use Pinecone serverless and Vercel's AI SDK to demonstrate a URL crawl, data chunking and embedding, and semantic questioning.
See our complete list of integrations to learn more about our growing number of data sources, models, and frameworks that seamlessly connect to Pinecone.

5. Build like the world’s leading companies
Because of our original focus on ease of use, reliability, and scalability, Pinecone became the most popular choice for developers building GenAI applications. With serverless, we’ve made it even easier to use and scale. Serverless has opened the door for companies to build remarkably better GenAI applications, as evidenced by leaders from Notion, Gong, and DISCO.
"Pinecone serverless opened up possibilities we hadn't considered before and allows us to invest even more in our long-term product capabilities." - Rick Vestal, Director of Engineering, DISCO
Thousands of engineers have already started using Pinecone serverless with billions of embeddings serving millions of users, for example:
- Notion can now support RAG over billions of documents for the millions of customers using their newest AI products.
- Gong is now powering vector search over billions of embeddings at 10x lower cost.
- Frontier Medicines increased efficiency in vector searches for tens of billions of molecule vectors.
- DISCO is using RAG to search across information from vast legal datasets more effectively and accurately.
Get started today
See why over 5,000 customers are running Pinecone in pilots or production applications and try serverless today.
Was this article helpful?