RAG makes LLMs better and equal
Abstract
This research investigates the impact of using Retrieval-Augmented Generation (RAG) to enhance Large Language Models (LLMs) with abundant data for GenAI applications. The study demonstrates that RAG significantly improves LLM performance, even on questions within their training domain. The positive effect grows as more data is made available for retrieval, tested with increasing sample sizes up to the scale of a billion documents.
Results show that simply making more data available for context retrieval makes LLMs provide significantly better results, even when increasing the data size to 1 billion, regardless of the chosen LLM. Compared with GPT-4 alone, GPT-4 with RAG and sufficient data improved the quality of the answers significantly by 13% (reduced the frequency of unhelpful answers from GPT-4 by 50%) for the "faithfulness" metric (reference: Es at el.), even on information that the LLM was trained on; the effect would be even more significant for questions related to private data, e.g., internal company data. Additionally, results showed the same level of performance (80% faithfulness) can be achieved with other LLMs, such as the open-source Llama 2 and Mixtral, as long as enough data is made available via a vector database.
Key points:
- RAG with more data significantly improves the results of GenAI applications.
- The more data you can search over, the more "faithful" (factually correct) the results. As tested with a 1B dataset, which scales logarithmically.
- RAG with massive data on-demand is better than GPT4 (without RAG), even with the data it was trained on.
- RAG, with a lot of data, provides SOTA performance no matter what LLM you choose. This insight unlocks using different LLMs (e.g., open-source or private LLMs).
Introduction
The advent of Large Language Models (LLMs) has marked a transformative era in artificial intelligence. These models have demonstrated remarkable abilities in understanding and generating human-like text, revolutionizing various generative AI applications. The methodology of In-Context Learning (ICL), where LLMs adapt their responses based on the context provided in the input, is a critical factor in their success. This methodology has significantly enhanced the flexibility and accuracy of LLMs, making them more adept at handling diverse and complex tasks.
Alongside in-context learning, Retrieval-Augmented Generation (RAG) working with LLMs has been a groundbreaking development. RAG enables these models to access and incorporate a massive amount of external information, significantly broadening their knowledge. In practice and research, RAG is superior to traditional training methods, such as fine-tuning, for embedding knowledge into LLMs (references: Kandpal et al., Ovadia et al., Mallen et al.). By enabling direct access to a wealth of information, RAG empowers these models to generate more accurate, reliable, and contextually relevant responses.
Despite these advancements, no one has yet explored the potential of RAG at a large scale. In this work, we push the boundaries by testing RAG with an unprecedented volume of data: one billion records. This research explores the effects of such extensive data integration on the performance of various LLMs, including GPT-4-turbo, GPT-3.5-turbo, Llama2-70B, and Mixtra-8x7B. This is particularly evident in the enhanced “faithfulness” (reference: Es at el.) of answers provided by the models, with a remarkable 13% improvement observed in GPT-4 when supplemented with RAG over the entire billion corpus. Our study not only underscores the scalability of RAG in enhancing LLMs but also demonstrates that with the application of RAG—LLMs of varied power and sizes can achieve almost equal high levels of accuracy and reliability— democratizing access to state-of-the-art capabilities of generative AI across different LLMs.
Experiments Setup
Dataset
To test RAG at scale, we leveraged the Falcon RefinedWeb dataset (reference: Penedo et al.) publicly available in Hugging Face. This dataset contains 980 million web pages from CommonCrawl. First, we filter out all outlier web pages that contain less than 20 tokens or more than 4k tokens. Then, we split them into chunks of 512 tokens using the standard recursive character splitter from Langchain. This process yields around 1.4 billion web chunks, from which we randomly sampled a billion.
Question Generation
To obtain a set of questions randomly spread across the dataset, we used GPT-4-turbo to generate a set of 1,000 open-ended factual questions. We provide additional details about this process in Section A in the appendix and made the set of questions publicly available.
Evaluation
Evaluating open-ended responses remains a challenging and ongoing area of research (references: Kamallo at el., Wang et al., Hanovich et al.). In our experiments, we rely on the RAGAS framework (reference: Es at el.), which offers various metrics for assessing the quality of open-ended questions for RAG. Our primary focus is on the "faithfulness" metric, which by default evaluates how factually consistent a model's response is with the information acquired during the retrieval process. We treat the document used to generate the question as the ground truth information to ensure this metric is relevant even when no external retrieval occurs and the response is solely based on the model's internal knowledge. In addition, as recommended by the RAGAS framework, we also used the "answer relevancy" as a complementary metric to faithfulness and reported the scores in Section C in the appendix.
External Knowledge (RAG)
In all the experiments, we used Cohere’s “embed-english-v3.0” model to embed the chunks and indexed them in a Pinecone serverless index. In query time, we used the Canopy framework with default parameters where we first searched for top-1000 most relevant chunks using Pinecone and then applied a standard re-ranking step to obtain the top 10 chunks using Cohere’s “rerank-english-v2.0” model via an API.
Models
In all the experiments, we tested GPT-4-turbo, GPT-3.5-turbo via OpenAI API, Llama2-70B, and Mixtra-8x7B via Anyscale Endpoints. We provide the prompt used in Section B in the appendix.
Experiment I: How RAG Scales to a Billion
To evaluate how well RAG scales, we tested its effectiveness by increasing random sample sizes from the entire dataset. To generalize for a standard use case where the external knowledge is private and unavailable for the model during training, we instructed the model to use only the provided retrieved information (see full prompt in section B in the appendix). As shown in Figure 1, the performance of RAG is increasing with the sample size, reaching its peak at the dataset's total size of one billion. Interestingly, despite the variance in reasoning capabilities among different models, the difference in their performance is comparatively small. For example, GPT-4-turbo, the most powerful proprietary model, is only 3% more "Faithful" than the Mixtral open-source model, which costs 20X less per token. This insight suggests that RAG could enable smaller, less costly, or private models to deliver high-quality results in tasks requiring simple factual reasoning. Moreover, this finding indicates that RAG, specifically with Pinecone, can scale effectively to handle vast amounts of data and is exceptionally adept at isolating specific, relevant information, even at large scale.
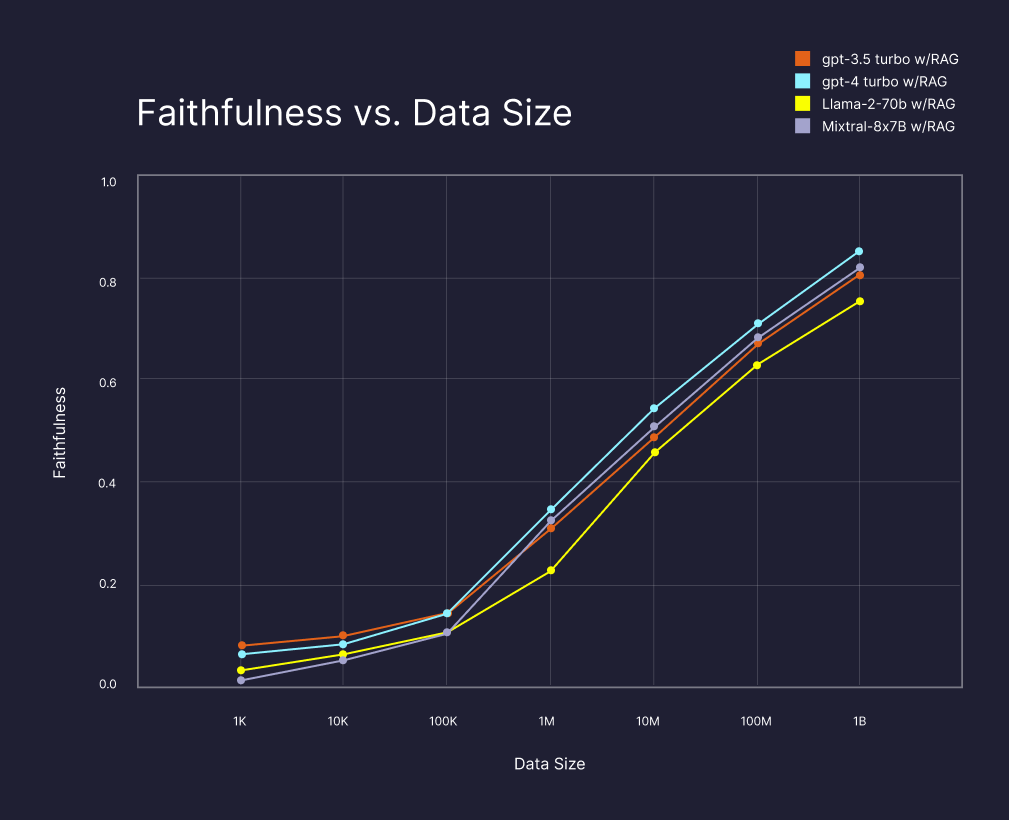
Experiment II: Comparing RAG to Internal Knowledge
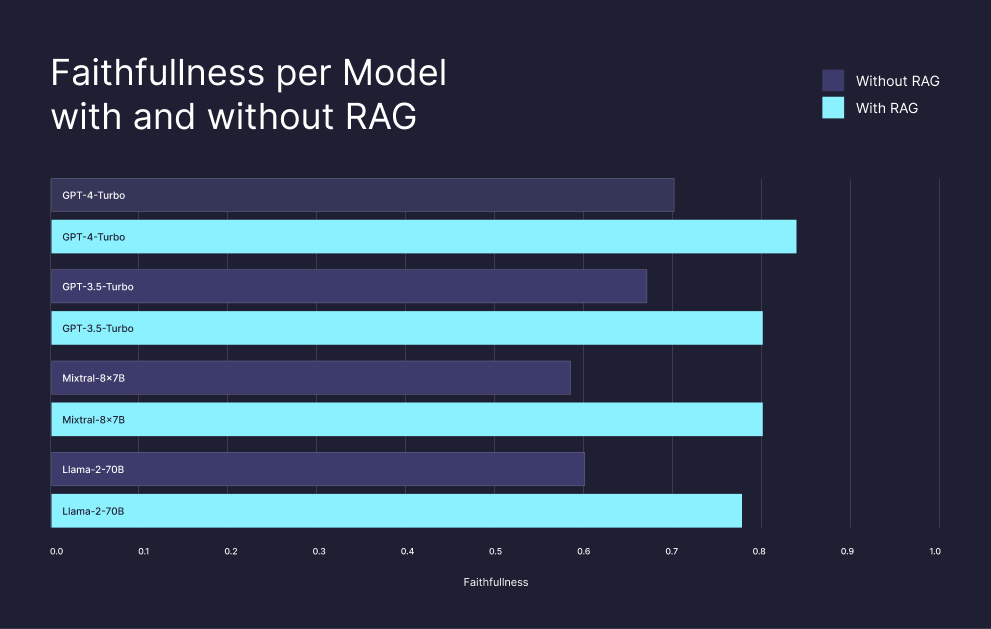
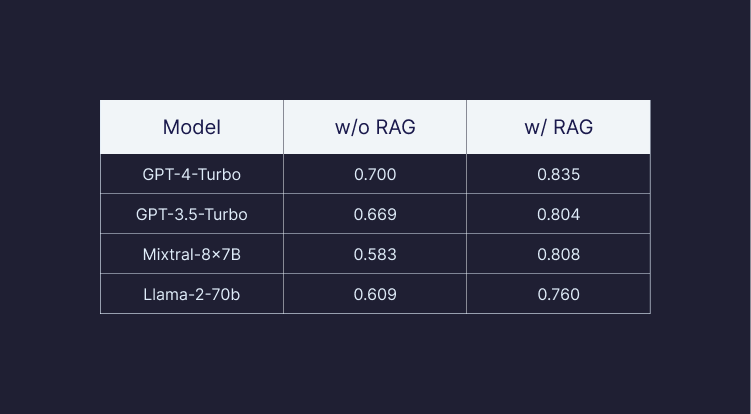
Considering that the models' training involves data from CommonCrawl, it is reasonable to assume that the training data of the models included information from the web pages in the RefinedWeb dataset. To compare RAG performance to the ability of the model to pull out information from its training data or "internal knowledge", we compared the performance of RAG with the entire dataset, as described in Experiment I, to the answers of the models where they instructed to use only their internal knowledge (see the full prompt in Section B in the appendix). As shown in Figure 2 and Table 1, across all models, RAG significantly outperforms the models' internal knowledge, even in the challenging task of pulling out information from a billion-scale corpus. For example, RAG increased GPT-4-turbo faithfulness by 13% and the Mixtral-8x-7B Faithfulness by 22%. As shown in many previous works (references: Kandpal et al., Ovadia et al., Mallen et al.), this suggests that RAG is the ultimate way to make LLMs knowledgeable as it is much cheaper and performant than fine-tuning for incorporating knowledge.
Experiment III: Combining Internal and External Knowledge
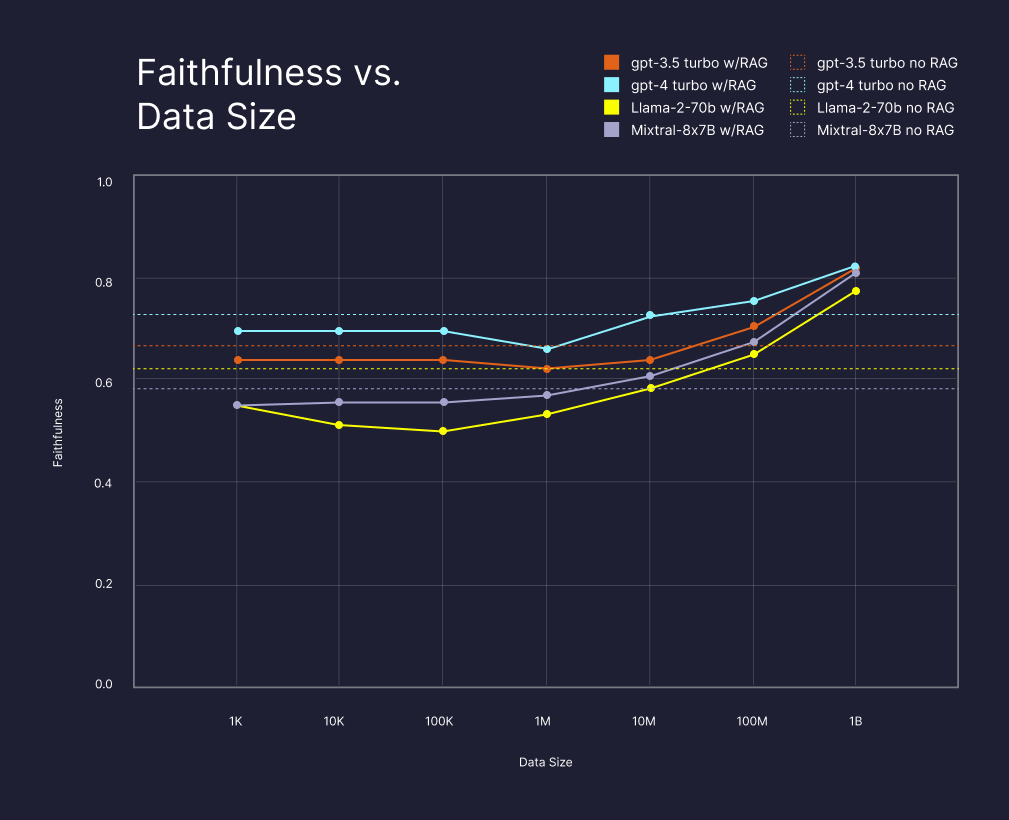
In our previous experiments, we instructed the models in the RAG system to rely solely on retrieved information for answering questions. To simulate a more realistic scenario where a system might leverage both external and internal knowledge, we adopted a methodology similar to (reference: Yoran et al.). This approach involved adding a classification step to determine whether to use answers derived from external knowledge or base them solely on the model's internal knowledge. We initially asked the model to provide an answer for each question using only external knowledge (RAG). Subsequently, we tasked the model with classifying whether this answer was consistent with the retrieved context. If the RAG-based answer was deemed consistent, it was selected as the final response. Otherwise, we instructed the model to generate an answer using its internal knowledge without any external knowledge. As demonstrated in Figure 3, this classification step effectively differentiates situations where external knowledge is lacking. Notably, when using the full dataset, the system predominantly relies on external knowledge, leading to better performance than internal knowledge alone. For example, Llama-270B and Mixtral-8x-7B classified their RAG-based answer as consistent for 99% and 91% of the questions, respectively. In addition, the fact that the performance on the small data samples was close to the performance of the models with only internal knowledge, although clearly, the small samples do not contain the relevant information for the questions, implies that a combined system could only benefit from incorporating RAG, even when some of the data is missing from the external knowledge base.
Conclusions
Our research shows that using abundant data can meaningfully improve the answer quality of Large Language Models using Retrieval Augmented Generation. This improvement occurs even at scales up to 1B data points. In addition, using RAG at this scale shows quality improvements across various LLMs, resulting in quality improvements that exceed the state-of-the-art base model across a range of models of size and complexity. By using RAG at scale, users building GenAI applications can create high-quality applications while maintaining the flexibility to choose a Large Language Model based on price, privacy, stability, or other considerations.
Appendix
A. Question Generation
In the creation of our dataset, we leveraged GPT to generate a set of 1,000 questions out of the billion documents dataset. Our process aimed to obtain questions that are 1) factual and 2) suitable to open domain QA. For example, the question “When was the author of the book mentioned in the document born?” is not suitable for open domain QA since it requires the context of a specific document to answer the question. Conversely, a question such as “When was the author of ‘Bad Blood’ born?” exemplifies a question that is both factual and appropriate for open domain QA. The final dataset used is publicly available.
Procedure
- Document Sampling: From the 1 billion corpus, we randomly selected 50,000 documents uniformly.
- Ranking Documents: Each of the 50,000 documents was then processed through GPT-3.5-turbo. The purpose here was to rank each document on a scale from 1 to 5, based on the extent to which they contained factual information and were appropriate for open domain QA.
- Filtering Based on Rankings: Documents that scored below 4 were excluded from further consideration. This filtering criterion retained approximately 20% of the initial sample.
- Question and Answer Generation: Utilizing GPT-4-turbo, we then generated a pair of a question and its corresponding answer from each of the selected documents. The generation process was guided by two requirements: the questions had to be factual, and they had to fit the open domain QA criteria.
- Filtering Subjective Questions with Heuristics: Post-generation, we applied specific heuristics to further refine the quality of questions. We observed that questions with answers that are longer than 10 words (10% of the questions), or contain the word “purpose” (2%) are much more likely to be subjective and challenging for quality assessment. Therefore we filtered them out.
- Final Suitability Classification: The remaining questions were once again processed through GPT-4-turbo, this time to classify each question as either suitable or unsuitable for factual, open-domain QA. This step led to the exclusion of 80% of the questions, significantly enhancing the overall quality of the dataset.
- Random Sampling of Questions: The last stage involved uniformly sampling 1,000 questions from the remaining pool of 1,200.
B. Instruction Prompts
For all the experiments we provided the question as a user message at the end of the chat history.
RAG System Prompt
Use the following pieces of context to answer the user question. This context retrieved from a knowledge base and you should use only the facts from the context to answer.
Your answer must be based on the context. If the context not contain the answer, just say that 'I don't know', don't try to make up an answer, use the context.
Don't address the context directly, but use it to answer the user question like it's your own knowledge.
Answer in short, use up to 10 words.
Context:
{context}For the open-source models (Llama2-70B and Mixtral-8x-7B), we've discovered that it's extremely advantageous to emphasize in the user's message the importance of adhering to the context and refraining from relying on internal knowledge. Therefore, instead of using only the question as the user message we used the following message:
Your answer must be based on the context, don't use your own knowledge. Question: {question}Internal Knowledge System Prompt
answer the user question according to your knowledge. Answer with no more than 10 words. Don't make up information, if you don't know the answer just say 'I don't know'.Answer Classification Prompt (Experiment III)
You are a binary classifier. You can respond only with "Yes" or "No". Given a question, answer and a context, you should say "Yes" if the answer is fully supported by the context, and "No" otherwise.
Examples:
Context: [some snipptes talking about Michael Jordan, that mention that his hieght is 1.98m]
Question: What is the height of Michael Jordan?
Answer: 1.98m
Your response: "Yes"
Context: [some texts talking about France, without mentioning the capital city]
Question: What is the capital of France?
Answer: Paris
Your response: "No"
Don't explain your choice, respond only with "Yes" or "No".
Context: {context}
Question: {question}
Answer: {answer}
Your response:C. Answer Relevancy Scores
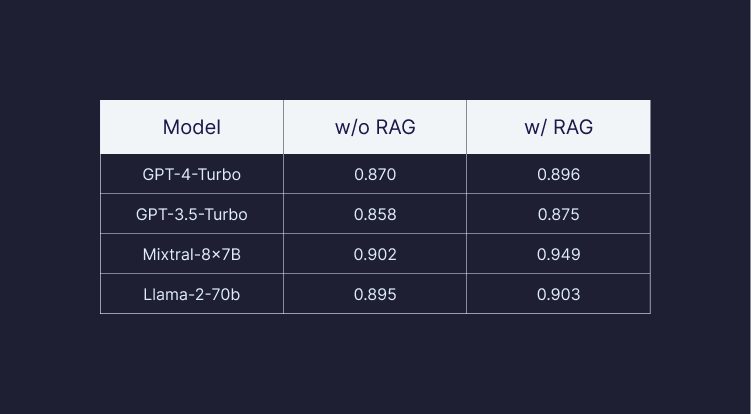
We provide answer relevancy scores as a complementary metric to faithfulness as suggested by RAGAS. Answer relevancy scores are generally high across all settings and models, so we provide here only the scores for Experiment II. As shown, while the scores are generally high, for all models the RAG based answers were more relevant. For instance, when employing RAG, the relevancy of GPT-4 answers improved by 3%, and that of Llama-2-70B increased by 5%. We suspect that Llama-2-70b performance is the highest for this metric because it tends more to provide an answer even for questions that it doesn't know the answer or not provided with relevant content when used with RAG.
Was this article helpful?