We are announcing Pinecone serverless, a completely reinvented vector database that lets you easily build fast and accurate GenAI applications. It’s available today in public preview.
Helping developers build remarkable AI applications
From the beginning, our mission has been to help engineers build better AI products. We created the vector database to put vector search in the hands of every developer so they could build AI-powered applications like semantic search, recommenders, data labeling, anomaly detectors, candidate generation, and many others.
With the rise of GenAI, our mission became more important and relevant than ever before. Using a vector database for Retrieval Augmented Generation (RAG) emerged as the way to improve GenAI quality and reduce hallucinations while retaining control over proprietary data. Because of our original focus on ease of use, reliability, and scalability, Pinecone became the most popular choice for developers building RAG applications. Hundreds of thousands of developers have used Pinecone, and over 5,000 customers are running Pinecone in pilots or production applications.
After a year of widespread experimentation with GenAI and vector databases, the bar for “remarkable” is higher, and so are the stakes. Developers and their companies are racing to build differentiated and commercially viable AI applications, and they need more than just access to LLMs and vector search to achieve that. But what, exactly?
Knowledge makes the difference
After working with thousands of engineering teams and conducting a study that measured the effect of RAG and data sizes on LLM quality, we found the answer: Knowledge. Give the AI application differentiated knowledge by giving it on-demand (and secure) access to your data. The more data it can search through semantically to find the right context, the better the application performs in terms of answer quality.
The chart below shows the qualitative improvements in RAG answer quality as a function of the amount of data made available to the LLM using Pinecone.
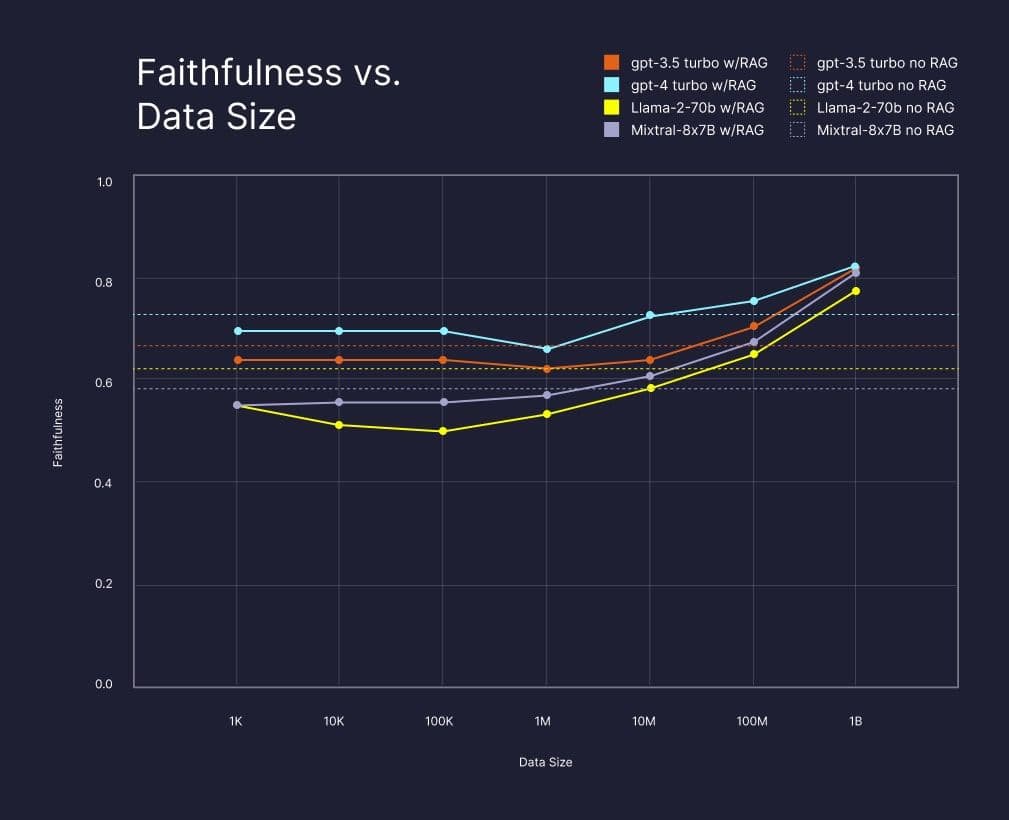
After a certain threshold, using the LLM with RAG led to more “faithful” — roughly speaking: more useful and accurate — answers than using the LLM alone, and it kept improving with larger index sizes. By the 1B mark, using RAG reduced unfaithful answers from GPT-4 by around 50%. The effect on other LLMs was even greater, actually making up for any original difference in quality between them and GPT-4.
(This test was done on a public dataset the models were already trained on. When using RAG for proprietary data, the threshold for RAG outperforming non-RAG would be lower and the quality improvement would be significantly greater.)
Read more details and findings from the study by our research team.
With this insight, the next step in our mission became clear: In order to build remarkable GenAI applications, developers need an even easier and cost-effective solution for searching through massive, ever-growing amounts of vector data. Helping them do that would require a complete reimagination of the vector database and everything inside it, from indexing algorithms to the storage architecture to the APIs and more. So that’s what we did.
Pinecone serverless: Add unlimited knowledge to your AI applications
Pinecone serverless is the next generation of our vector database. It is incredibly easy to use (without any pod configuration) and provides even better vector-search performance at any scale. All to let you ship GenAI applications easier and faster.
“To make our newest Notion AI products available to tens of millions of users worldwide we needed to support RAG over billions of documents while meeting strict performance, security, cost, and operational requirements. This simply wouldn’t be possible without Pinecone.”
— Akshay Kothari, Co-Founder of Notion.
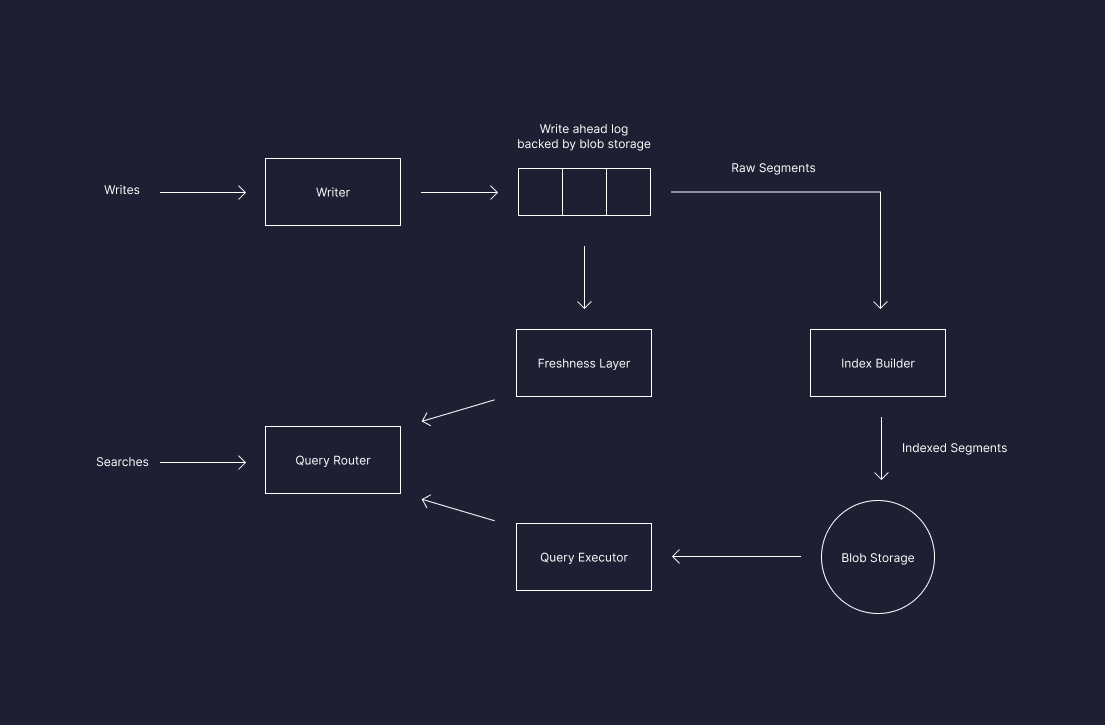
These are some of the new features of the purpose-built cloud database:
- Separation of reads, writes, and storage significantly reduces costs for all types and sizes of workloads.
- Industry-first architecture with vector clustering on top of blob storage provides low-latency, always-fresh vector search over a practically unlimited number of records at a low cost.
- Innovative indexing and retrieval algorithms built from scratch to enable fast and memory-efficient vector search from blob storage without sacrificing retrieval quality.
- Multi-tenant compute layer provides powerful and efficient retrieval for thousands of users, on demand. This enables a serverless experience in which developers don’t need to provision, manage, or even think about infrastructure, as well as usage-based billing that lets companies pay only for what they use.
Read the technical deep-dive from our VP of R&D, Ram Sriharsha, to learn a lot more about the design decisions, architecture, performance, and sample costs of Pinecone serverless.
Here’s what Pinecone serverless gives you:
1. Pay for what you use
Most users will see a lower cost with Pinecone serverless compared to Pinecone pod-based indexes for several reasons:
- Separated pricing for reads (queries) means you don’t have to pay for compute resources when you’re not using them.
- Separated pricing for storage means you can pay for exactly the number of records you have, regardless of your query needs.
- Usage-based pricing reduces cost for variable or unpredictable workloads. You will only pay for what you use, and not for peak capacity.
- Significantly more efficient indexing and searching that consumes far less memory and compute. We pass the savings to you.
- And finally, there is no minimum cost per index. Whether you have one index or ten thousand, you still only pay for total reads, writes, and storage.
Here’s a sample comparison of monthly costs between our serverless and pod-based indexes, assuming a typical volume of 500K monthly queries. There is no change in recall between the two index types.
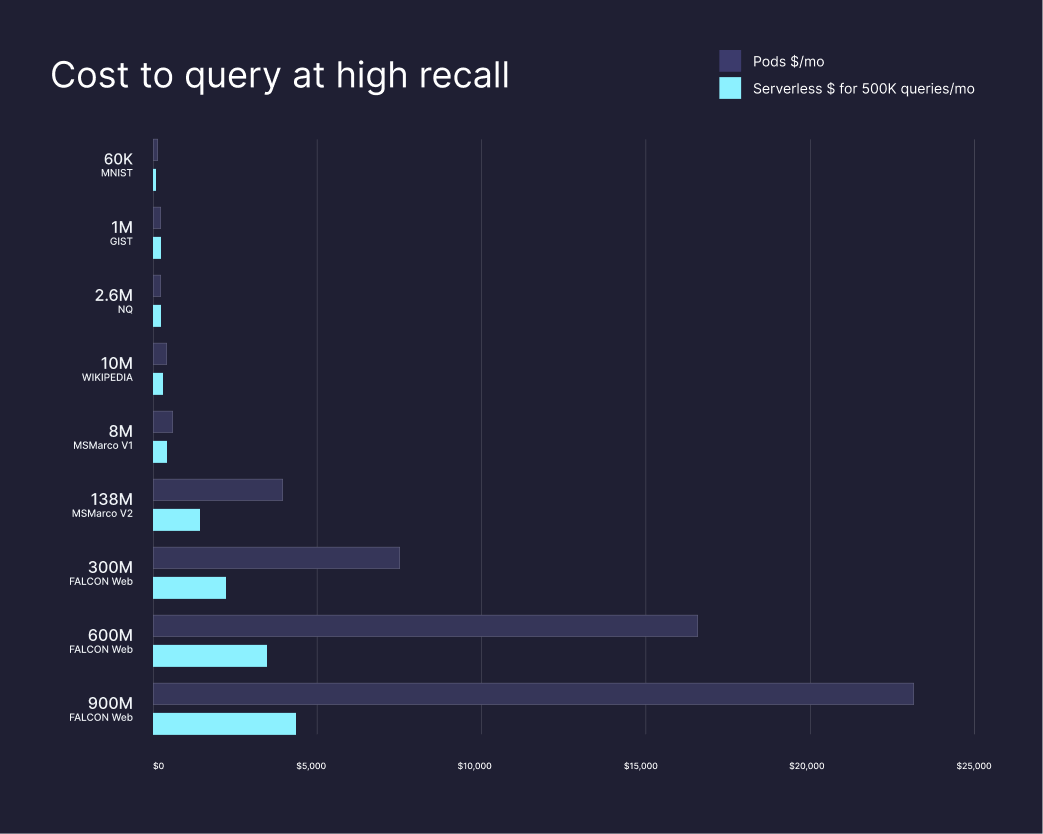
A word of caution about Public Preview pricing: The packaging and pricing during public preview is not yet optimized for high-throughput applications, such as recommender systems. We will introduce updated pricing for such use cases in the future. In the meantime, if you have a high-throughput application you may see reads throttled, and we recommend comparing the costs of both index types.
Your actual costs will vary depending on your exact workload. Test actual costs while building and monitor your spend in production.
2. Effortless starting and scaling
There are no pods, shards, replicas, sizes, or storage limits to think about or manage. Simply name your index, load your data, and start querying through the API or the client. There’s nothing more to it. So, you can get back to focusing on the rest of your application. See example notebooks.
3. Fast, fresh, filtered, and relevant vector search results
You might think that cost savings come at the expense of functionality, accuracy, or performance. It does not.
Just like the pod-based indexes, Pinecone serverless supports live index updates, metadata filtering, hybrid search, and namespaces to let you have the most control of your data.
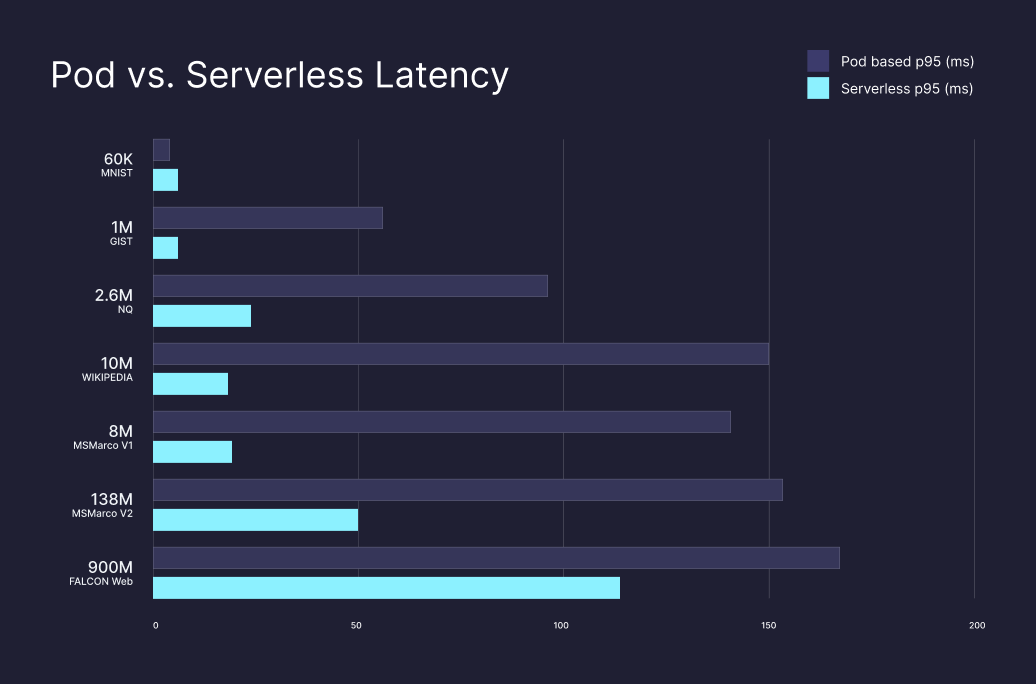
Performance is also preserved. In fact, for warm namespaces, serverless indexes provide significantly lower latencies compared to pod-based indexes, with roughly the same level of recall. Warm namespaces are namespaces that receive queries regularly and, as a result, are cached locally in the multi-tenant workers. Cold-start queries will have higher latencies.
Start building knowledgeable AI with Pinecone serverless
Pinecone serverless is in public preview starting today.
Companies like Notion, Gong, CS Disco, and many others have already started using Pinecone serverless with billions of embeddings serving millions of users. And other parts of your AI stack already integrate with Pinecone serverless to make getting started even easier: Anyscale, Cohere, Confluent, LangChain, Pulumi, Vercel, and many more.
Try Pinecone serverless now (Also available through the AWS Marketplace.)
You can also talk to our sales team, get support, or post in our community forum with questions. We always value your feedback; if you find a bug, experience something confusing or difficult, or just have an idea on how to make Pinecone better, we’d love to hear from you.
During the public preview period:
- Pod-based indexes continue to be fully supported.
- Serverless indexes are only available in AWS regions; availability in GCP and Azure regions is coming soon.
- The free plan is not fully migrated to the new architecture. To experience Pinecone serverless, you must upgrade to a paid account.
- We have you covered: All users on paid accounts receive $100 in free usage for Pinecone serverless to try it before incurring charges.
- A migration mechanism to help you move data from pod-based indexes to serverless indexes is in development.
- Performance may fluctuate. We recommend testing thoroughly before using in production.
Was this article helpful?