Unsupervised Training for Sentence Transformers
Language represents a way for us to communicate abstract ideas and concepts. It has evolved as a human-only form of interaction for the best part of the past 100 million years. Translating that into something a machine can understand is (unsurprisingly) difficult.
Modern(ish) computers appeared during and around WW2. The first application of natural language processing (NLP) came soon after with the Georgetown machine translation (MT) experiment in 1954. In the first decade of research, many expected MT to be solvable within a few short years [1] — they were slightly too optimistic.
MT is still not ‘solved’, but that and the field of NLP have become heavily researched in the past few years, and there have been many breakthroughs. We now have some incredible language models for a stunning array of use-cases.
Much of this recent success is thanks to dense vector representations of words and sentences. These vectors are produced by language models that translate the semantic meaning of language into a numerical vector space that a computer can understand and process.
As is the trend with ML models, we need a lot of data and a lot of compute to build these models.
Sentence transformers are the current-best models for producing information-rich representations of sentences and paragraphs. The training process to create this type of model varies but begins with the unsupervised pretraining of a transformer model using methods like masked-language modeling (MLM).
To adapt a pretrained transformer to produce meaningful sentence vectors, we typically need a more supervised fine-tuning approach. We can use datasets like natural language inference (NLI) pairs, labeled semantic textual similarity (STS) data, or parallel data (pairs of translations).
For some domains and languages, such as finance and English, this data is fairly easy to find or gather. But many domains and many languages have very little labeled data. If you can find semantic similarity pairs for the agriculture industry, please let me know. There are many languages, such as Dhivehi, where unlabelled data is hard to find and labelled data practically non-existent.
This means you either spend a very long time gathering tens of thousands of labeled samples or you can try an unsupervised fine-tuning approach.
Unsupervised training methods for sentence transformers are not as effective as their supervised counterparts, but they do work. And if you have no other choice, why not?
In this article, we will introduce the concept of unsupervised fine-tuning for sentence transformers. We will learn to train these models using the unsupervised Transformer-based Sequential Denoising Auto-Encoder (TSDAE) approach.
Unsupervised Or Not?
The first thing we need to decipher is: “Do we really need to use unsupervised fine-tuning?" The answer depends on your use case and available data.
First, let’s look at a few supervised training approaches, their use cases, and required data.
Natural Language Inference
Natural language inference (NLI) is the most common approach to fine-tuning a generic monolingual sentence transformer. It uses optimization functions like softmax loss or multiple negatives ranking to learn how to distinguish between similar and dissimilar sentences [2] [3].
An NLI dataset contains sentence pairs labeled as either (1) entailing/inferring each other, being (2) neutral (e.g., they’re not necessarily related), and sometimes (3) contradictory.
Some methods like multiple negatives ranking only require positive entailment pairs but work better when we add ‘hard negatives’ (contradictory) pairs.
Suppose you have these ‘positive’ pairs of sentences. In that case, a good pretrained transformer can usually be fine-tuned to a reasonable performance with just 20,000 pairs. If you have less than this, you may still be able to successfully fine-tune — it depends on the complexity of your domain and language.
Semantic Textual Similarity
Semantic textual similarity (STS) is another common approach to fine-tuning generic sentence transformers. An STS dataset contains sentence pairs alongside their ‘semantic similarity’, given as a numeric value within a set range.
Optimization functions like cosine similarity loss can be used. The model will attempt to optimize the sentence vectors of each pair to be more-or-less similar according to a cosine similarity function.
Multilingual Parallel Data
When building multilingual sentence transformers, we take an already trained monolingual sentence transformer and use a fine-tuning process called multilingual knowledge distillation which distills the monolingual knowledge of the fine-tuned model and adapts it across multiple languages in a pretrained multilingual model.
To do this, you need:
- A pretrained multilingual model (it does not need to be a sentence transformer)
- A fine-tuned monolingual sentence transformer
- Parallel data, which are translation pairs from the monolingual model’s language, to your multilingual target language(s).
Unsupervised
If your data and use-case don’t seem to fit into any of the above, unsupervised fine-tuning may be the answer.
How TSDAE Works
There are different options for unsupervised fine-tuning of sentence transformers. One of the best performing is the Transformer(-based) and Sequential Denoising Auto-Encoder (TSDAE) pretraining method developed by Kexin Wang, Nils Reimers, and Iryna Gurevych in 2021 [4].
TSDAE introduces noise to input sequences by deleting or swapping tokens (e.g., words). These damaged sentences are encoded by the transformer model into sentence vectors. Another decoder network then attempts to reconstruct the original input from the damaged sentence encoding.
At first glance, this may seem similar to masked-language modeling (MLM). MLM is the most common pretraining approach for transformer models. A random number of tokens are masked using a ‘masking token’, and the transformer must try to guess what is missing, like a ‘fill in the blanks’ test in school.
Fill in the missing words: The miniature pet ________ became the envy of the neighborhood.
If you guessed elephant, you’re correct (and possibly unhinged).
TSDAE differs in that the decoder in MLM has access to full-length word embeddings for every single token. The TSDAE decoder only has access to the sentence vector produced by the encoder.
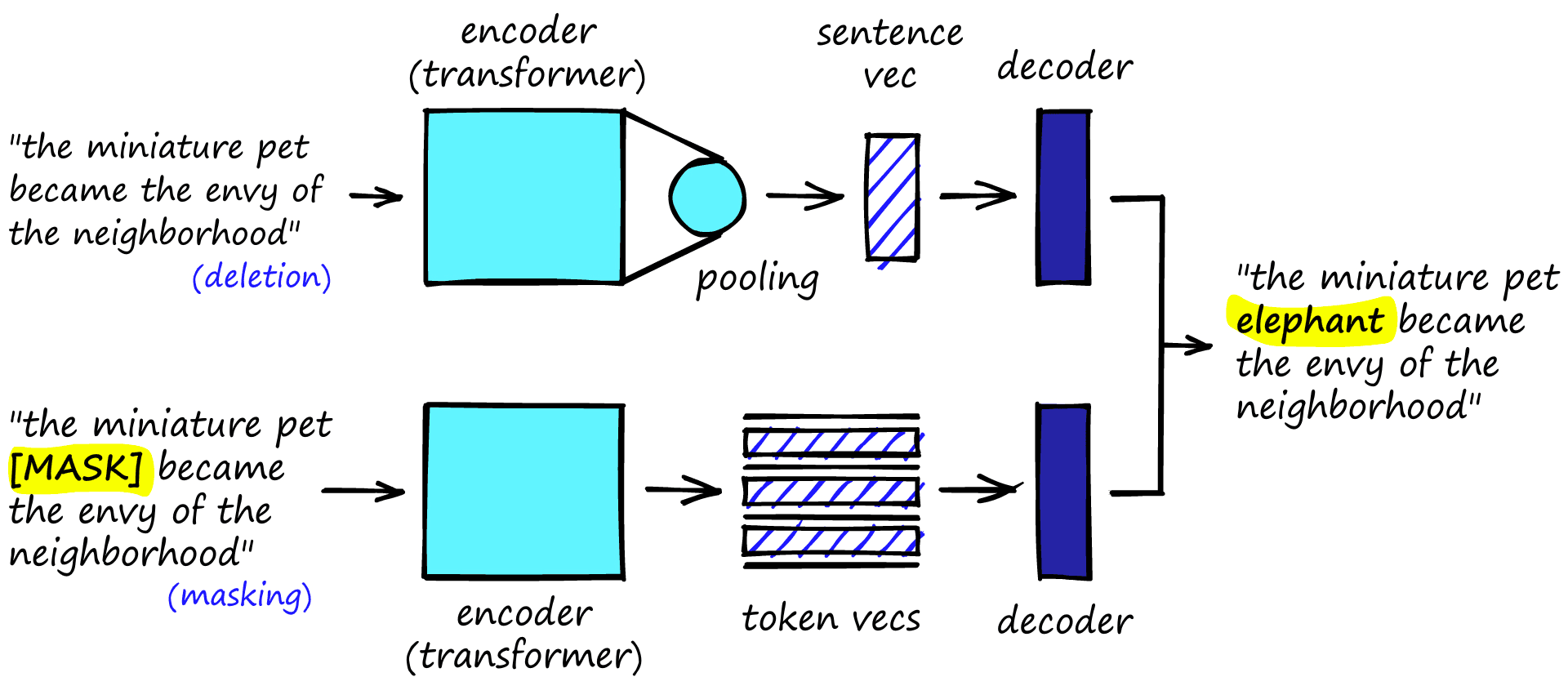
In the K. Wang, et al. (2021) paper, the best performing noise used deletion-only, with a deletion ratio of 0.6. To translate from token-level representation to sentence-level, the classifier token [CLS] embedding was used.
The TSDAE paper described five tested approaches to noise in the input data and noise ratios tested from 0.1 to 0.9. Of those, it was deletion at a ratio of 0.6 that performed best.
If you’ve read our previous articles on sentence transformers, you will remember that we usually apply a mean pooling operation across transformer word embeddings to produce a single sentence embedding/vector.
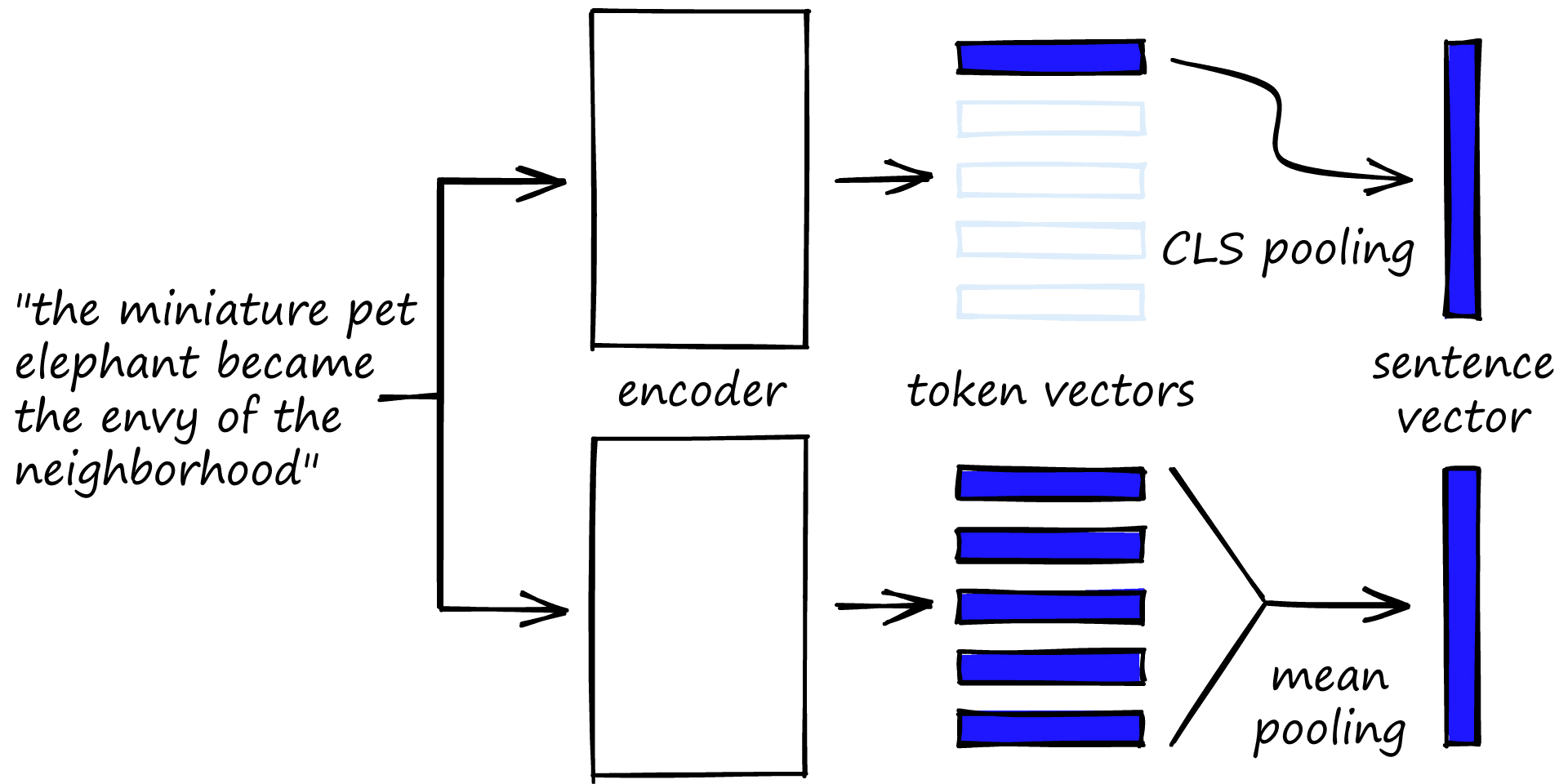
When fine-tuning with TSDAE, the performance difference between the two approaches is tiny.
| CLS | Mean | Max |
|---|---|---|
| 78.77 | 78.84 | 78.17 |
Rather than averaging vectors, we can take the [CLS] vector as is. Usually, this embedding is used to feed information into a classification head of a transformer, which, of course, classifies the whole input sequence. So we can see the [CLS] embedding as a representation of the whole sequence/sentence.
Fine-Tuning Walkthrough
Before we begin fine-tuning, there are a few things we need to set up:
- Training data
- A pretrained model prepared for producing sentence vectors
- Loss function
Let’s work through each of these.
Training Data
When fine-tuning a model for producing sentence vectors, TSDAE requires nothing more than text data. One handy source for text data (in many languages) is the OSCAR corpus. We will stick with English, for which OSCAR contains 1.8TB (after deduplication),so we have enough data.
We won’t be training on the entire dataset. Instead, we will gather just 100K (mostly) short sentences. To download OSCAR (not the whole thing), we will use HuggingFace’s datasets library.
import datasets # pip install datasets
oscar = datasets.load_dataset(
'oscar',
'unshuffled_deduplicated_en',
split='train',
streaming=True
)Note that we added streaming=True; this allows us to iteratively download samples from the OSCAR dataset rather than downloading the full 1.8TB.
for row in oscar:
break
row{'id': 0,
'text':
'Mtendere Village was inspired by the vision of Chief Napoleon Dzombe, which
he shared with John Blanchard during his first visit to Malawi. Chief Napoleon
conveyed the desperate need for a program to intervene and care for the orphans
and vulnerable children (OVC) in Malawi, and John committed to help.\n
Established in honor of John & Lindy’s son, Christopher Blanchard, this
particular program is very dear to the Blanchard family. Dana Blanchard, or
Mama Dana as she is more commonly referred to at Mtendere, lived on site during
the initial development, and she returns each summer to spend the season with
her Malawian family. The heart of the program is to be His hands and feet by
caring for the children at Mtendere, and meeting their spiritual, physical,
academic, and emotional needs.\nMtendere Village is home to 134 children,
living in 16 homes with a housemother and several brothers and sisters. This
family environment is one that many of the children have never previously
experienced. 100X has also built a library and multipurpose building on the
...
to the full extent allowable under IRS regulations.'}Each sample in OSCAR contains an id and text. The text can be very long, with several sentences and paragraphs. Ideally, we need to split each of these into single sentences. We can do this by using a regex function that covers both period and newline characters.
import re
splitter = re.compile(r'\.\s?\n?')splitter.split(row['text'])[:10]['Mtendere Village was inspired by the vision of Chief Napoleon Dzombe, which he shared with John Blanchard during his first visit to Malawi',
'Chief Napoleon conveyed the desperate need for a program to intervene and care for the orphans and vulnerable children (OVC) in Malawi, and John committed to help',
'Established in honor of John & Lindy’s son, Christopher Blanchard, this particular program is very dear to the Blanchard family',
'Dana Blanchard, or Mama Dana as she is more commonly referred to at Mtendere, lived on site during the initial development, and she returns each summer to spend the season with her Malawian family',
'The heart of the program is to be His hands and feet by caring for the children at Mtendere, and meeting their spiritual, physical, academic, and emotional needs',
'Mtendere Village is home to 134 children, living in 16 homes with a housemother and several brothers and sisters',
'This family environment is one that many of the children have never previously experienced',
'100X has also built a library and multipurpose building on the property—giving the children a place to gather together, learn and build community',
'The children attend a local primary school and receive afterschool tutoring at home in the afternoon',
'All of the school fees, uniforms, and supplies are paid for through our sponsorship program']We will use splitter to create a list of 100K sentences to feed into TSDAE fine-tuning.
num_sentences = 0
sentences = []
for row in oscar:
new_sentences = splitter.split(row['text'])
new_sentences = [line for line in new_sentences if len(line) > 10]
# we will need a list of sentences (remove too short ones above)
sentences.extend(new_sentences)
# the full OSCAR en corpus is huge, we don't need all that data
num_sentences += len(new_sentences)
if num_sentences > 100_000:
# Sentence transformers recommends 10-100K sentences for training
breakThe typical PyTorch process requires creating a Dataset object then passing it into a DataLoader. In PyTorch, we need to create a function to add noise to the data (usually within the Dataset class). Fortunately, sentence-transformers handles this for us via the DenoisingAutoEncoderDataset object.
from sentence_transformers.datasets import DenoisingAutoEncoderDataset
from torch.utils.data import DataLoader
# dataset class with noise functionality built-in
train_data = DenoisingAutoEncoderDataset(sentences)
# we use a dataloader as usual
loader = DataLoader(train_data, batch_size=8, shuffle=True, drop_last=True)By default, the DenoisingAutoEncoderDataset deletes tokens with a probability of 60% per token. Now that our training data is ready we can move on to the final pretraining phase.
Model and Training
As mentioned, we need a model to fine-tune. This model should already be pretrained, of which there are plenty of choices over at HuggingFace models.
Note that BERT seems to outperform other models after fine-tuning with TSDAE. This is possibly thanks to the next sentence prediction (NSP) pretraining task used for BERT, which learns sentence-level contexts [4]. With this in mind, we will go ahead and use bert-base-uncased.
from sentence_transformers import SentenceTransformer, models
bert = models.Transformer('bert-base-uncased')
pooling = models.Pooling(bert.get_word_embedding_dimension(), 'cls')
model = SentenceTransformer(modules=[bert, pooling])
modelSentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)Alongside the transformer model (BERT), we need a pooling layer to move from the usual output of 512 token vectors to a single sentence vector. The K. Wang, et al. (2021) paper recommends using the [CLS] token vector as the sentence vector, which we have used above. The two parts are then merged with SentenceTransformer.
After this, we define a loss function. Again, sentence-transformers handles this with the DenoisingAutoEncoderLoss class.
from sentence_transformers.losses import DenoisingAutoEncoderLoss
loss = DenoisingAutoEncoderLoss(model, tie_encoder_decoder=True)You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
The following encoder weights were not tied to the decoder ['bert/pooler']
We’re now ready to begin fine-tuning. We use an Adam optimizer with a constant learning rate (no warm-up) of 3e-5 and no weight decay.
model.fit(
train_objectives=[(loader, loss)],
epochs=1,
weight_decay=0,
scheduler='constantlr',
optimizer_params={'lr': 3e-5},
show_progress_bar=True
)
model.save('output/tsdae-bert-base-uncased')Iteration: 100%|██████████| 12505/12505 [21:20<00:00, 9.77it/s]
Epoch: 100%|██████████| 1/1 [21:20<00:00, 1280.51s/it]
*(note if you get an error to do with NLTK and/or Punkt, run the following)*
```
!pip install nltk
```
```python
import nltk
nltk.download('punkt')
```Fine-tuning should not take too long, after which we can move on to model evaluation.
Does it Work?
The training process is undoubtedly easy to set up and run, but does it work? And, if so, how does it compare to other supervised fine-tuning methods?
To evaluate model performance, we will use the Semantic Textual Similarity benchmark (STSb) dataset. As before, we will use HuggingFace’s datasets to retrieve the data.
sts = datasets.load_dataset('glue', 'stsb', split='validation')
stsDataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1500
})The label feature contains a score from 0 -> 5 that describes how similar sentence1 and sentence2 are (higher is more similar). The evaluator we will be using requires scores from 0 -> 1, so we normalize then reformat the data to use sentence-transformers InputExample class.
# normalize the 0 -> 5 range
sts = sts.map(lambda x: {'label': x['label'] / 5.0})from sentence_transformers import InputExample
samples = []
for sample in sts:
# reformat to use InputExample
samples.append(InputExample(
texts=[sample['sentence1'], sample['sentence2']],
label=sample['label']
))During evaluation, we want to produce sentence vectors for sentence1-sentence2 pairs and calculate their similarity. If the similarity score is close to the label value, great! If not, that’s not as great. We can use the EmbeddingSimilarityEvaluator to do this.
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
evaluator = EmbeddingSimilarityEvaluator.from_input_examples(
samples, write_csv=False
)evaluator(model)0.730612981552636A score of 0.73 seems reasonable, but how does it compare to other models? Let’s compare it to an untrained bert-base-uncased.
bert = models.Transformer('bert-base-uncased')
pooling = models.Pooling(bert.get_word_embedding_dimension(), 'cls')
model = SentenceTransformer(modules=[bert, pooling])
evaluator(model)0.3173000994730588There’s clearly an improvement from untrained BERT to a TSDAE fine-tuned BERT, which is great to see. However, we know that an unsupervised approach is unlikely to compete with supervised methods.
The most popular approach (as mentioned earlier) for fine-tuning sentence transformers is with Natural Language Inference (NLI) data. The original SBERT bert-base-nli-mean-tokens was trained with this, and many of the highest performing models like flax-sentence-embeddings/all_datasets_v3_mpnet-base are too. Let’s see how these two perform.
# original SBERT
model = SentenceTransformer('bert-base-nli-mean-tokens')
evaluator(model)0.8078719671168788# more advanced model like MPNet
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v3_mpnet-base')
evaluator(model)0.8883349210786895We can see a big difference here. Fine-tuning with TSDAE simply cannot compete in terms of performance against supervised methods.
However, the point and value of TSDAE is that it allows us to fine-tune models for use-cases where we have no data. Specific domains with unique terminology or low resource languages.
For these use-cases, a score of 0.73 from a TSDAE-trained sentence transformer after just 20 minutes of training is incredible.
That’s it for this article on the unsupervised fine-tuning of sentence transformers using TSDAE. We’ve explained where not to use TSDAE and where to use it.
We worked through the logic being TSDAE and its parallels with MLM pretraining. After working through a TSDAE fine-tuning example, we evaluated the performance of a TSDAE-trained model against models trained using common supervised methods.
Despite TSDAE producing lower performing models than other supervised methods, it opens doors for many previously inaccessible domains and languages. With nothing more than unstructured text, we’re able to build effective sentence transformers. As increasingly effective unsupervised methods are developed, we may find that the future of sentence transformers needs nothing more than unstructured text.
References
[1] J. Hutchins, The History of Machine Translation in a Nutshell (2005)
[2] N. Reimers, I. Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019), EMNLP
[3] N. Reimers, NLI Fine-Tuning: MultipleNegativesRankingLoss, Sentence Transformers on GitHub
[4] K. Wang, et al., TSDAE: Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning (2021), EMNLP
Was this article helpful?