Make your search app get it.
We expect the search applications we interact with to provide us with relevant information and answer the questions we have. We expect this process to be fast, easy, and accurate. In fact, 71% of consumers expect personalized results, and 76% get frustrated when they don’t find it. 1
When searching with a keyword-based solution, applications will look for exact word or string matches. If your users aren’t sure what exactly to search for, searching by keywords won’t always get them the right answer. It can also be time-consuming for them to find the information they need, especially when there’s a large amount of unstructured data to search through. As a result, they won’t find the answers they’re looking for or they’ll get incomplete answers.
Turning to AI for better search results and user experience
Unlike keyword-based search, semantic search uses the meaning of the search query. It finds relevant results even if they don’t exactly match the query. This works by combining the power of Large Language Models (LLMs) to generate vector embeddings with the long-term memory of a vector database.
Once the embeddings are stored inside a vector database like Pinecone, they can be searched by semantic similarity to power applications for a variety of use cases.
Semantic search use cases
- Knowledge management: Save time and boost productivity for your internal teams by enabling them to self-serve and search through various internal data and documents to answer their questions. With semantic search, they can more quickly find what they are looking for. For example, a leading telecom company uses Pinecone to enable their customer service teams to search through their internal knowledge base to respond to customer inquiries quicker and with more accuracy.
- End-user applications: Gain a competitive advantage by building and providing a solution to increase relevance of search results for end-users. With semantic search, users will be able to increase productivity by finding answers to their questions faster. For example, a global ERP software company uses Pinecone to let their customers get insights from employee feedback using semantic search.
- Aggregated data services: Enable your end-users to make more informed, data-driven decisions by compiling various data sources and identifying valuable insights using semantic search. For example, an online-learning company uses Pinecone to power their core search and question-answering feature for millions of users.
Challenges when building AI-powered search
Companies are increasingly turning to AI to power their search applications, but self-managing the complex infrastructure — from the vector database to the LLMs needed to generate embeddings — can lead to challenges.
Without the necessary infrastructure or dedicated ML engineering and data science teams, companies self-hosting vector databases to power semantic search applications can face:
- High query latencies: Storing and searching through large numbers of embeddings on traditional databases is prohibitively slow or expensive.
- Less relevant results: Answers can be improved by fine-tuning the LLM, but that requires data science expertise and ML engineering. Search results may be less accurate without the necessary AI and ML resources.
- Capacity and freshness tradeoffs: While it’s important for a search solution to provide the most up to date information, running frequent batch jobs to maintain a fresh index leads to high compute and storage costs.
Search like you mean it with Pinecone
Providing fast, fresh, and filtered results, Pinecone customers don’t need to make tradeoffs between performance, scale, and query speed. Pinecone is a fully-managed vector database trusted by some of the world’s largest enterprises. We provide the necessary infrastructure to support your semantic search use cases reliably at scale.
Benefits of semantic search with Pinecone
- Ultra-low query latencies: Power search across billions of documents in milliseconds, combined with usage-based pricing for high-volume production applications. Partition indexes into namespaces to further reduce search scope and query latency.
- Better search results: With Pinecone, you can trust that you are searching the most up-to-date information with live index updates. Combine semantic search with metadata filters to increase relevance, and for hybrid search use cases, leverage our sparse-dense index support (using any LLM or sparse model) for the best results.
- Easy to use: Get started in no time with our free plan, and access Pinecone through the console, an easy-to-use REST API or one of our clients (Python, Node, Java, Go). Jumpstart your project by referencing our extensive documentation, example notebooks and applications, and many integrations.
- Fully-managed: Launch, use, and scale your search solution without needing to maintain infrastructure, monitor services, or troubleshoot algorithms. Pinecone supports both GCP and AWS — choose the provider and region that works best for you.
Incorporating Pinecone into your search stack:
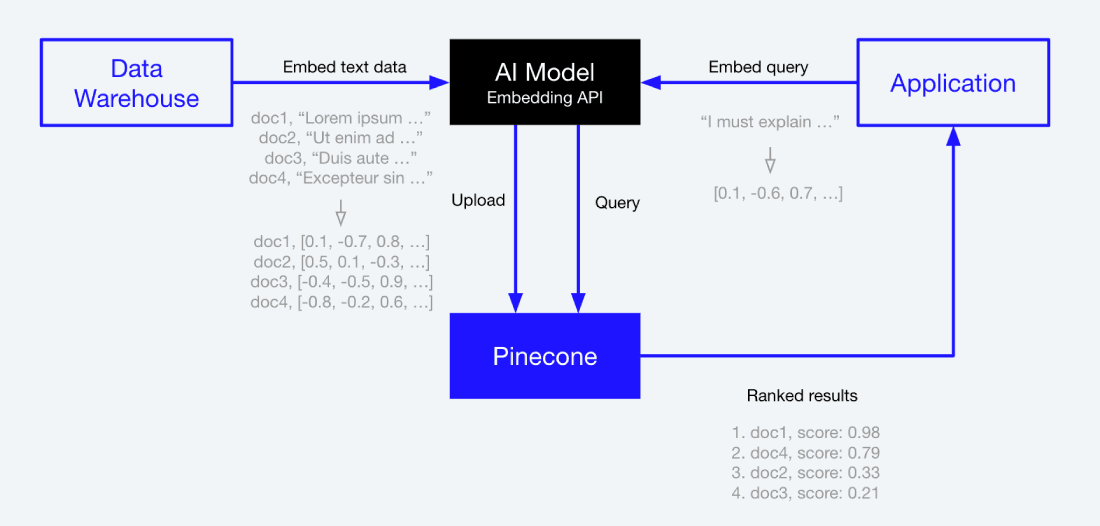
Adding semantic search to your search stack is easy with Pinecone. To get started, you need Pinecone plus the following components: data warehouse (or any source of truth for data), AI model, and your application. You can also refer to our example notebook and NLP for Semantic Search guide for more information.
Step 1: Take data from the data warehouse and generate vector embeddings using an AI model (e.g. sentence transformers or OpenAI’s embedding models).
Step 2: Save those embeddings in Pinecone.
Step 3: From your application, embed queries using the same AI model to create a “query vector.”
Step 4: Search through Pinecone using the query embedding, and receive ranked results based on semantic similarity.
Complete your search stack with our integrations:
Pinecone works with embeddings from any AI model or LLM. We recommend getting started with either OpenAI or Hugging Face. We also have integrations for LLM frameworks (e.g. LangChain) and data infrastructure (e.g. Databricks) to take your search applications to the next level.
Get started today
Ready to start building with Pinecone? Create an account today to get started or contact us to talk to an expert.
References
Was this article helpful?