Aligning GenAI use cases and User privacy concerns

GenAI creates personalized web experiences by combining proprietary data with the knowledge of individual users. How can we ensure this knowledge is handled safely per security compliance standards?
How can we provide our users with guarantees around the deletion of their Personal Identifiable Information (PII)?
In this post, we’ll examine tools and patterns you can use to ensure your Pinecone-backed applications are compliant with security and privacy standards.
Why RAG is the best architecture for ensuring data privacy
Retrieval Augmented Generation, the architecture that enriches GenAI responses with private data, is commonly deployed to solve Large Language Model shortcomings, including hallucinations and short context windows.
But RAG also helps us build privacy-aware AI systems that forget specific information about individuals on demand.
To comply with security standards, we need to ensure that user data is:
| Separated | Only visible to its owners, and not other users. |
|---|---|
| Private | Not given to LLMs via training or fine-tuning, but only at inference or generation time. |
| Deletable on demand | Users should be forgotten whenever they wish |
Retrieval Augmented Generation systems built with Pinecone satisfy these requirements while retaining high performance and accuracy:
Separation
Namespaces separate your users’ data and are suitable as a security primitive. For more information, see our Handling Multi-tenancy chapter.
Privacy
When using RAG, data is provided as context to an LLM only at generation time, but the data does not need to be used for training or fine-tuning AI models.
This means your user data is not stored in the models themselves as knowledge—it’s merely shown to GenAI models when we ask for generated content.
RAG enables personalization while maintaining strict control over any PII used to generate user-specific responses.
Proprietary data or PII is shared with the LLM on a per-request basis and can be quickly removed from the system, making the information unavailable for future requests.
Deletion on demand
When a user wants to be forgotten, deleting their data from the Pinecone index will result in the RAG system having no further knowledge of them.
LLMs won’t be able to answer questions about a given user or topic after the data is deleted. The retrieval phase will no longer provide any of that information to the LLM at generation time.
RAG provides more flexibility around managing user-specific data than training or fine-tuning because you can quickly remove data about one or more entities from a production system without impacting system performance for other users.
Safely handling customer data in Pinecone
Understanding different types of data
Designing your software to be privacy-aware requires understanding the risks associated with each type of customer data you store.
First, classify the types of data that you’ll need to store in your vector database. Specifically, identify which data is public, private and which contain Personally Identifiable Information (PII).

Imagine we’re building an e-commerce application that will store a combination of public, confidential and PII data:
- Public: Company name, profile picture and job title
- Private: API keys, organization IDs, purchase history
- PII: Full name, birthdate, account ID
Next, determine which data will be stored as vectors only and which must be stored in metadata to support filtering.
We aim to balance storing as little PII as possible and providing a rich application experience.

Filtering with metadata is powerful, but its simplest form requires storing private or PII data in plaintext, so we want to be mindful of which fields we expose.
With this understanding, we can consider each data type and apply the following techniques to handle it safely.
Segregate customer data across indexes
Use separate indexes for different purposes. If your application manages natural language descriptions of geographical locations and some personally identifiable user data, create two separate indexes, such as locations and users.
Name your indexes based on what they contain. Think of indexes as the high-level buckets for the data types you’re storing.
Segregate customer data across namespaces
As we wrote in our chapter on building multi-tenancy systems using Pinecone, namespaces are convenient and secure primitives for separating organizations or users within a single index.
Think of namespaces as entity-specific partitions within an index. If your Pinecone index is users, then each namespace could map to each user’s name. Each namespace would only store data relevant to its user.
Using namespaces also helps improve query performance by reducing the total space that needs to be searched when returning relevant results.
Use ID-prefixing to query segments of content
Pinecone supports ID-prefixing, a technique that attaches extra data to your vectors’ ID fields upon upsert so that you can later reference “segments” of content, such as all the docs from Page 1, Chunk 23, or all of the vectors from user A of Department Z.
ID-prefixing is ideal for associating a set of vectors with a particular user so that you can efficiently delete that user’s data whenever they ask you to.
For example, imagine an application that processes restaurant orders so users can find their purchases using natural language:
index = pc.Index("serverless-index")
index.upsert(
vectors=[
{"id": "order1#chunk1", "values": [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]},
{"id": "order1#chunk2", "values": [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]},
{"id": "order1#chunk3", "values": [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
{"id": "order1#chunk4", "values": [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]}
],
namespace="orders"
)The ID field can supply hierarchical tags of whatever composition makes sense in your application.
This way, you can perform mass deletions and lists more easily:
# Iterate over all chunks from order #1
for ids in index.list(prefix='order1#', namespace='orders'):
print(ids)Using ID prefixes requires some upfront planning when designing your application, but it provides a convenient means of referencing all the vectors and metadata related to a particular entity.
Retrieval Augmented Generation is great for deleting knowledge, too
Retrieval Augmented Generation adds proprietary, private, or fast-changing data to LLM responses to ground them in truth and specific contexts.
But it’s also an ideal way to provide your end users with guarantees around their right to be forgotten. Let’s consider an e-commerce scenario where our users can use natural language to interact with a shop, retrieve old orders, purchase new products, etc.
In the following RAG workflow, the user’s natural language query is first converted to a query vector and then sent to the Pinecone vector database to retrieve orders that match the user’s parameters.
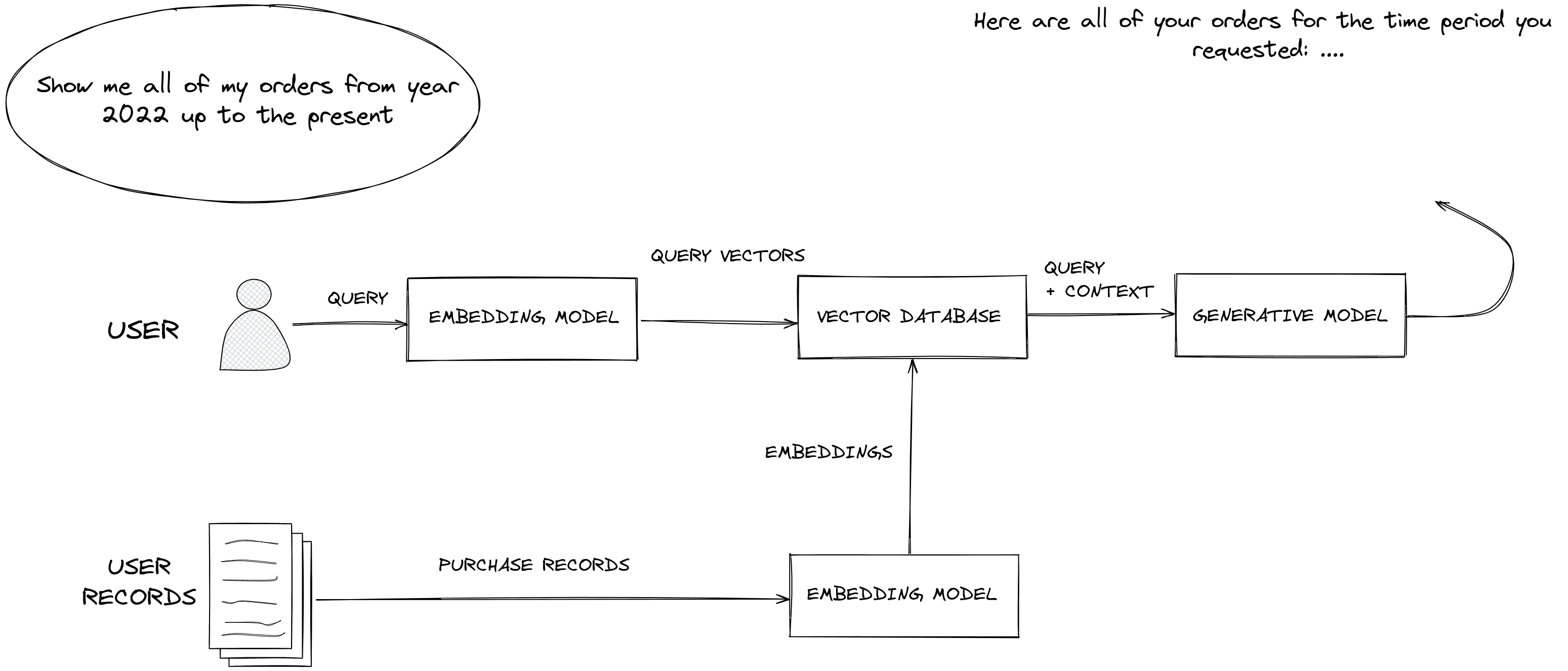
The user’s personal context ( their order history ) and some personally identifiable information are fetched and supplied to the generative model at inference time to satisfy their request.
RAG gives you control over which user data is presented to LLMs
What happens when you issue a batch delete using the ID prefix scheme?
for ids in index.list(prefix='order1#', namespace='orders'):
print(ids) # ['order1#chunk1', 'order1#chunk2', 'order1#chunk3']
index.delete(ids=ids, namespace=namespace)You’ve deleted all of the system’s user-specific context so that subsequent retrieval queries will return no results - we’ve effectively deleted knowledge of our user from the LLM!
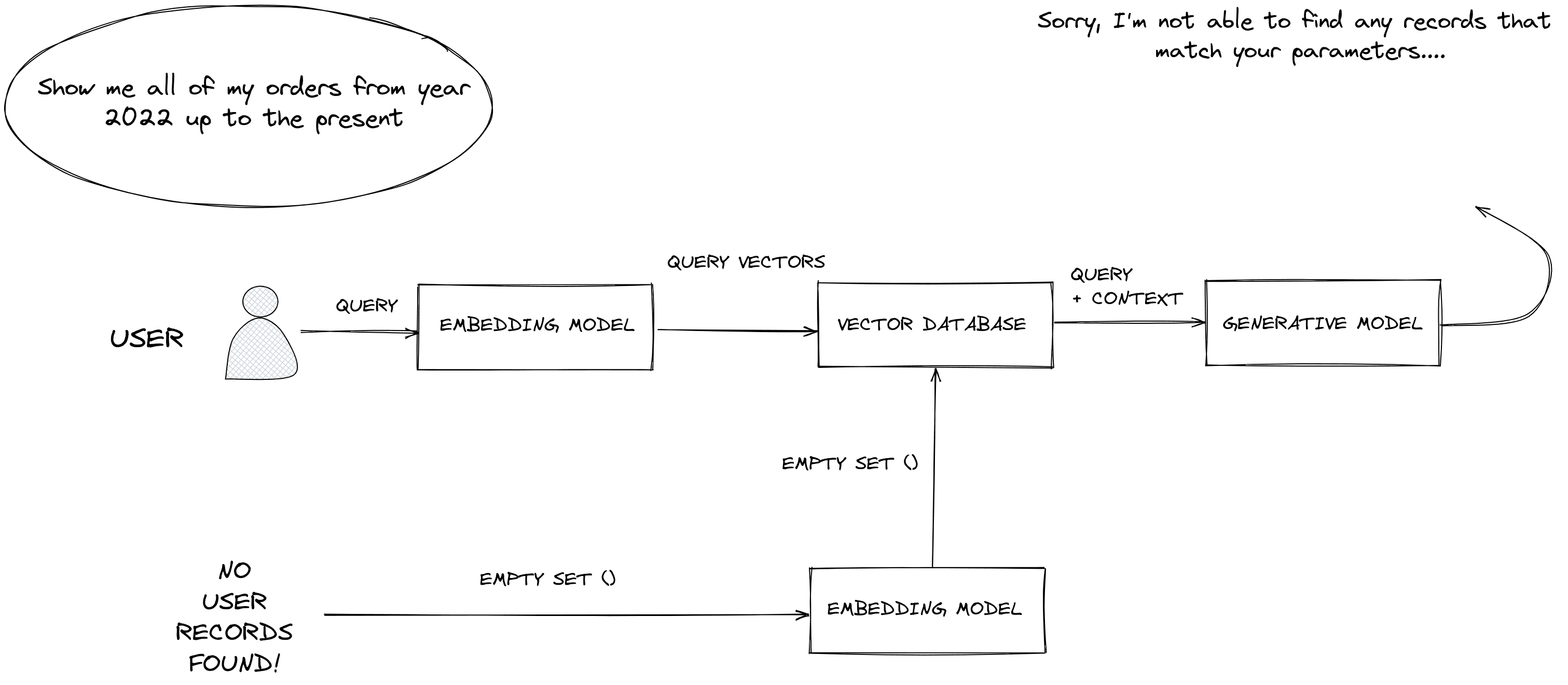
ID prefixing allows us to segregate, earmark and later list or delete data specific to an entity. This allows us to extend RAG into an architecture that provides guarantees around data deletion.
The most secure data is that which you do not store
Tokenization to obfuscate user data
You can often avoid storing Personally Identifiable Information entirely in Pinecone. Instead, you can keep your users safe by storing references or foreign keys to other systems, such as the ID of the row in your private database where the complete user record lives.
You can maintain the full user records in an encrypted and secure storage system on-premises or hosted by a cloud services provider. This reduces the total number of systems that see your user data.
This process is sometimes referred to as Tokenization, which is analogous to how models convert words in the prompts we send into the IDs of the words in a given vocabulary. You can use our interactive tokenization demo here to explore this concept.
Suppose your application can provide a lookup table or reversible tokenization process. In that case, you can write your foreign keys to the metadata you associate with your vectors during upsert to your vector database instead of plaintext values that make user data visible.
Foreign keys could be anything meaningful to your application: PostgreSQL row IDs, IDs in your relational database where you keep user records, URLs, or S3 bucket names that can be used to look up additional data.
When upserting your vectors, you can attach any metadata you wish:
index.upsert(
vectors=[
{
"id": "order1#chunk1",
"values": [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
"metadata": {"user_id": 3046, "url": "https://example.com"}
},
{
"id": "order2#chunk2",
"values": [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2],
"metadata": {"user_id": 201}
}
]
)Obfuscating user data with hashing
You can use hashing to obscure user data before writing it to metadata.
Hiding is not encryption. Obscuring user data does not provide the same protections as encrypting it, but it can make it harder for PII to be accidentally leaked.
Your application provides the logic to hash your user’s PII before attaching it to its associated vectors as metadata:
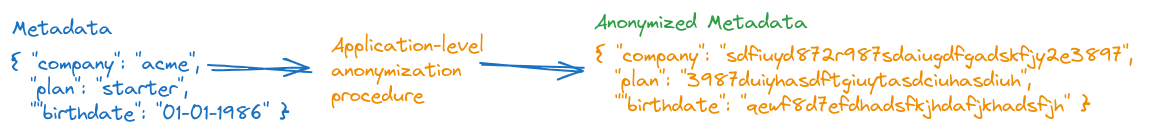
There are many types of hashing operations, but at a high level, they convert input data to a series of characters that do not make sense on their own but may be reversible or crackable by an attacker.
Your application can obfuscate user data in a variety of ways, including insecure message hashing or base64 encoding, before writing values to metadata:
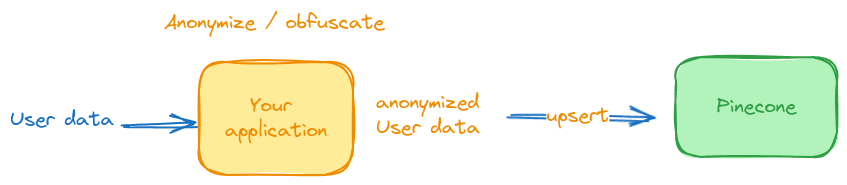
With your user data hashed and stored as metadata, your application runs queries through the same hashing logic to derive the metadata filter values.
Pinecone returns the results most relevant to your query as before.
Your application then de-obfuscates the user data before operating on or returning it to your end user:
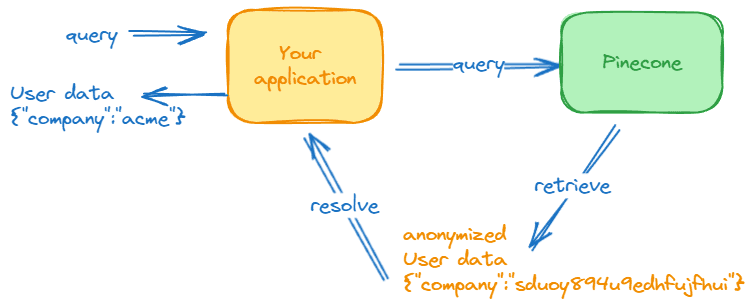
This approach provides additional defense in depth. Even if an attacker could access your Pinecone vector store, they’d still need to reverse your application-level hashing to get the plaintext values.
Encrypting and decrypting metadata
Obfuscating and hashing user data is better than storing it in plaintext but insufficient to protect against a skilled and motivated attacker.
Encrypting metadata before every upsert, re-encrypting query parameters to perform queries, and decrypting the final output for every request could introduce significant overhead to your system, but it’s the best way to ensure that your user data is secure and that your vector store has zero knowledge of the sensitive data it’s serving queries over.
Everything in engineering is a trade-off, and you’ll need to carefully balance the performance hit of constant encryption and decryption, plus the overhead of securely maintaining and rotating your private keys, with the risks of leaking sensitive customer data.
Data retention and deletion in Pinecone
If you follow the recommended convention of implementing multi-tenancy by maintaining separate namespaces, you can conveniently drop everything stored in that namespace with a single operation.
To delete all records from a namespace, specify the appropriate deleteAll parameter for your client and provide a namespace parameter like so:
index.delete(delete_all=True, namespace='example-namespace')Building Privacy-aware AI Software is achievable with upfront planning
Successfully building Privacy-aware AI software requires considering and classifying the data you plan to store upfront.
It requires leaving yourself thoughtful handles to segments of content, as we saw with ID-prefixing and metadata filtering, that you can use to efficiently delete knowledge of entire users or organizations from your system.
With Pinecone in your stack and some thoughtful upfront planning, you can build Generative AI systems that are equally responsive to users’ needs and respectful of their privacy.
Was this article helpful?