Question-Answering (QA) has exploded as a subdomain of Natural Language Processing (NLP) in the last few years. QA is a widely applicable use case in NLP yet was out of reach until the introduction of transformer models in 2017.
Without transformer models, the level of language comprehension required to make something as complex as QA work simply was not possible.
Although QA is a complex topic, it comes from a simple idea. The automatic retrieval of information via a more human-like interaction. The task of information retrieval (IR) is performed by almost every organization in the world. Without other options, organizations rely on person-to-person IR and rigid keyword search tools. This haphazard approach to IR generates a lot of friction, particularly for larger organizations.
Consider that many large organizations contain thousands of employees, each producing pages upon pages of unstructured text data. That data quickly gets lost in the void of unused directories and email archives.
QA offers a solution to this problem. Rather than these documents being lost in an abyss, they can be stored within a space where an intelligent QA agent can access them. Unlike humans, our QA agent can scan millions of documents in seconds and return answers from these documents almost instantly.
To interact with a QA agent, we don’t need to know any fancy search logic or code. Instead, we just ask a question as we would ask another human being. Suppose we want to understand why process X exists. In that case, we can ask, “why do we follow process X?” and the relevant information will be returned within milliseconds.
QA capability is not a “nice to have”. It is a key that can unlock ~90% of your organization’s data. Without it, unstructured data is lost almost as soon as it is made, akin to searching in the dark.
With QA tools, employees can stop wasting time searching for snippets of information and focus on their real, value-adding tasks.
A small investment in QA is, for most organizations, a no-brainer.
Long-Form Question-Answering
There are two overarching approaches to QA, abstractive (/generative) and extractive. The difference between the two lies in how the answer is constructed.
For abstractive QA, an answer is generated by an NLP generator model, usually based on external documents. Extractive QA differs from this approach. Rather than generating answers, it uses a reader model to extract them directly from external documents, similar to cutting out snippets from a newspaper.
We are using external documents to inform our generator/reader models in both cases. We call this open-book QA as it emulates open-book exams where students (the models) can refer to a book (external documents) during the exam. In our case, the void of unstructured data becomes our open-book.
An open-book abstractive QA pipeline looks like this:
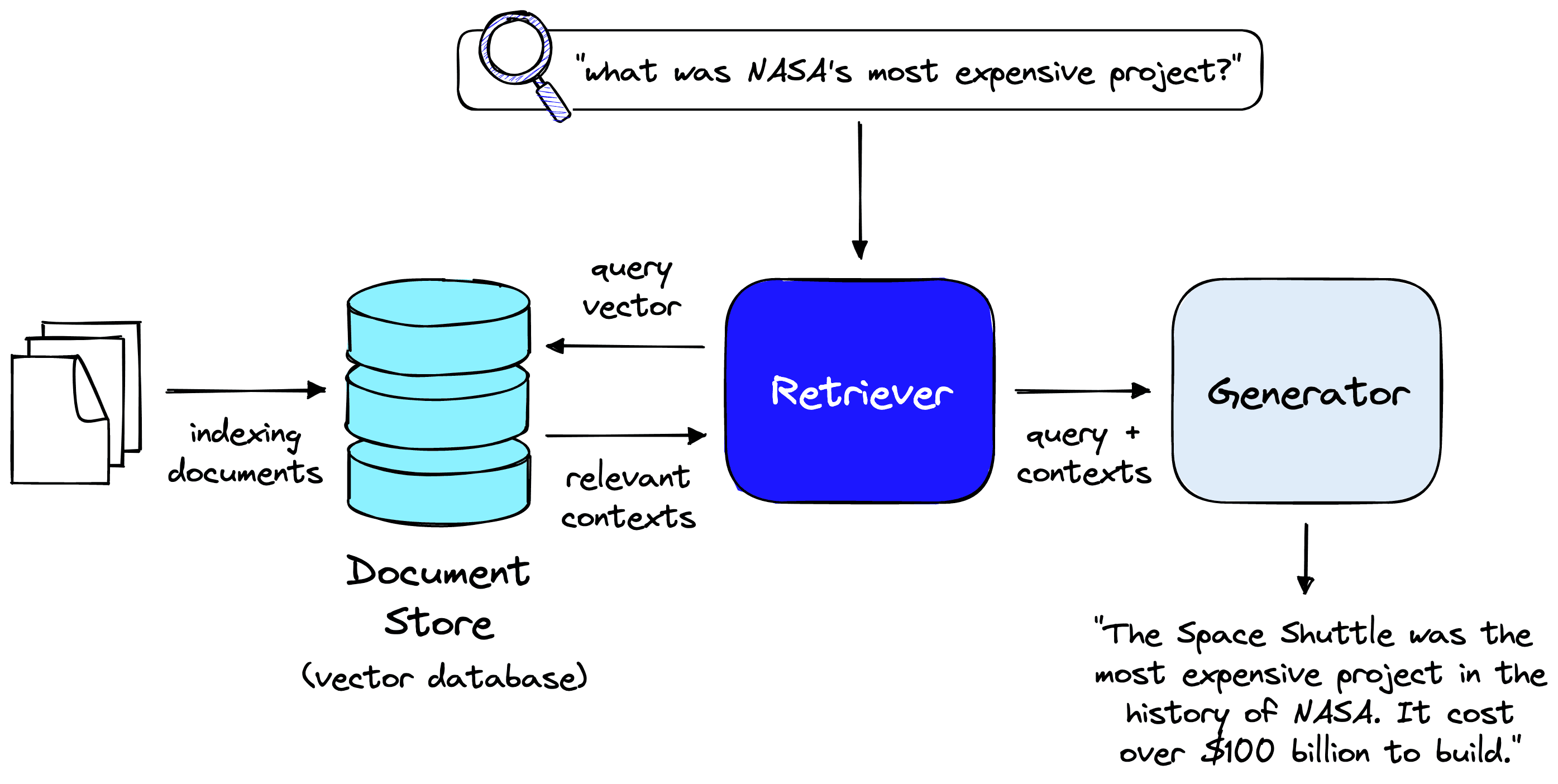
One form of open-book abstractive QA is Long-Form Question-Answering (LFQA). LFQA focuses on the generation of multi-sentence answers to open-ended questions.
Let’s work through an implementation of LFQA using the Haystack library.
LFQA in Haystack
Haystack is a popular Python library for building QA pipelines, allowing us to create an LFQA pipeline with just a few lines of code. You can find the full LFQA code here.
We start by installing the necessary libraries.
!pip install -U 'farm-haystack[pinecone]'>=1.3.0 pinecone-client datasetsData Preparation
Our first task is to find a dataset to emulate our “void” of unstructured data. For that, we will use the Wikipedia Snippets dataset. The full dataset contains over 17M passages from Wikipedia, but for this demo, we will restrict the dataset to ~50K passages. Feel free to use the whole dataset, but it will take some time to process.
from datasets import load_dataset
wiki_data = load_dataset(
'vblagoje/wikipedia_snippets_streamed',
split='train',
streaming=True
)We can find the dataset in Hugging Face’s Datasets library. The streaming=True parameter allows us to stream the dataset rather than download it. The full dataset is over 9GB, and we don’t need it all; streaming allows us to iteratively download records one at a time.
The dataset contains eight features, of which we are most interested in the passage_text and section_title.
# show the contents of a single document in the dataset
next(iter(wiki_data)){'wiki_id': 'Q7593707',
'start_paragraph': 2,
'start_character': 0,
'end_paragraph': 6,
'end_character': 511,
'article_title': "St John the Baptist's Church, Atherton",
'section_title': 'History',
'passage_text': "St John the Baptist's Church, Atherton History There have been three chapels or churches on the site of St John the Baptist parish church. The first chapel at Chowbent was built in 1645 by John Atherton as a chapel of ease of Leigh Parish Church. It was sometimes referred to as the Old Bent Chapel. It was not consecrated and used by the Presbyterians as well as the Vicar of Leigh. In 1721 Lord of the manor Richard Atherton expelled the dissenters who subsequently built Chowbent Chapel. The first chapel was consecrated in 1723 by the Bishop of Sodor and"}As we are limiting our dataset to ~50K passages, We will tighten the scope of topics and only extract records where the section_title feature is History.
# filter only documents with History as section_title
history = wiki_data.filter(
lambda d: d['section_title'].startswith('History')
)Our dataset is now prepared. We can move on to initializing the various components in our LFQA pipeline.
Document Store
The document store is (not surprisingly) where we store our documents. Haystack allows us to use various document stores, each with its pros and cons. A key consideration is whether we want to support a sparse keyword search or enable a full semantic search. Naturally, a human-like QA system requires full semantic search capability.
With that in mind, we must use a document store that supports dense vectors. If we’d like to scale to larger datasets, we must also use a document store that supports Approximate Nearest Neighbors (ANN) search.
To satisfy these requirements, we use the PineconeDocumentStore, which also supports:
- Single-stage metadata filtering, if using different
section_titledocuments, we could use metadata filtering to tighten the search scope. - Instant index updates, meaning we can add millions of new documents and immediately see these new documents reflected in new queries.
- Scalability to billions of documents.
- Free hosting for up to 1M documents.
We first need to sign up for a free API key. After signing up, API keys can be found by clicking on a project and navigating to API Keys. Next, we initialize the document store using:
from haystack.document_stores import PineconeDocumentStore
document_store = PineconeDocumentStore(
api_key='YOUR_API_KEY',
index='haystack-lfqa',
similarity="cosine",
embedding_dim=768
)INFO - haystack.modeling.model.optimization - apex not found, won't use it. See https://nvidia.github.io/apex/
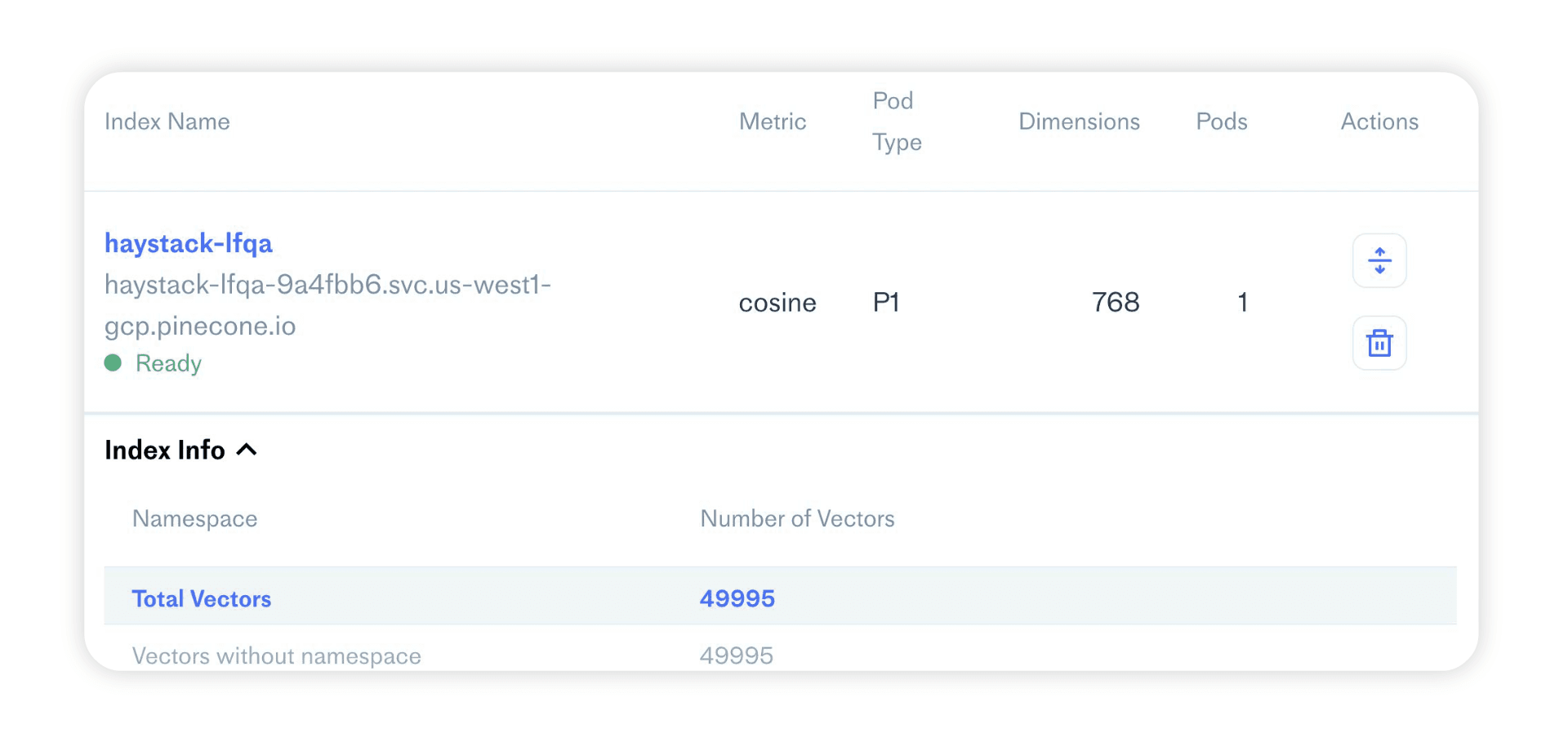
INFO - haystack.document_stores.pinecone - Index statistics: name: haystack-lfqa, embedding dimensions: 768, record count: 0
document_store.metric_type'cosine'Here we specify the name of the index where we will store our documents, the similarity metric, and the embedding dimension embedding_dim. The similarity metric and embedding dimension can change depending on the retriever model used. However, most retrievers use "cosine" and 768.
We can check the current document and embedding count of our document store like so:
document_store.get_document_count()0document_store.get_embedding_count()0If there is an existing index called haystack-lfqa, the above will connect to the existing index rather than initialize a new one. Existing indexes can be found and managed by visiting the active project in the Pinecone dashboard.
We can start adding documents to our document store. To do this, we first create Haystack Document objects, where we will store the text content alongside some metadata for each document. The indexing process will be done in batches of 10_000.
from haystack import Document
from tqdm.auto import tqdm # progress bar
total_doc_count = 50000
batch_size = 10000
counter = 0
docs = []
for d in tqdm(history, total=total_doc_count):
# create haystack document object with text content and doc metadata
doc = Document(
content=d["passage_text"],
meta={
"article_title": d["article_title"],
'section_title': d['section_title']
}
)
docs.append(doc)
counter += 1
if counter % batch_size == 0:
# writing docs everytime 10k docs are reached
document_store.write_documents(docs)
docs.clear()
if counter == total_doc_count:
breakNow, if we check the document count, we will see that ~50K documents have been added:
document_store.get_document_count()49995document_store.get_embedding_count()0When looking at the embedding count, we still see zero; this reflects the embedding count in the Pinecone dashboard. This is because we have not created any embeddings of our documents. That is another step that requires the retriever component.
Retriever
The QA pipeline relies on retrieving relevant information from our document store. In reality, this document store is what is called a vector database. Vector databases store vectors (surprise!), and each vector represents a single document’s text content (the context).
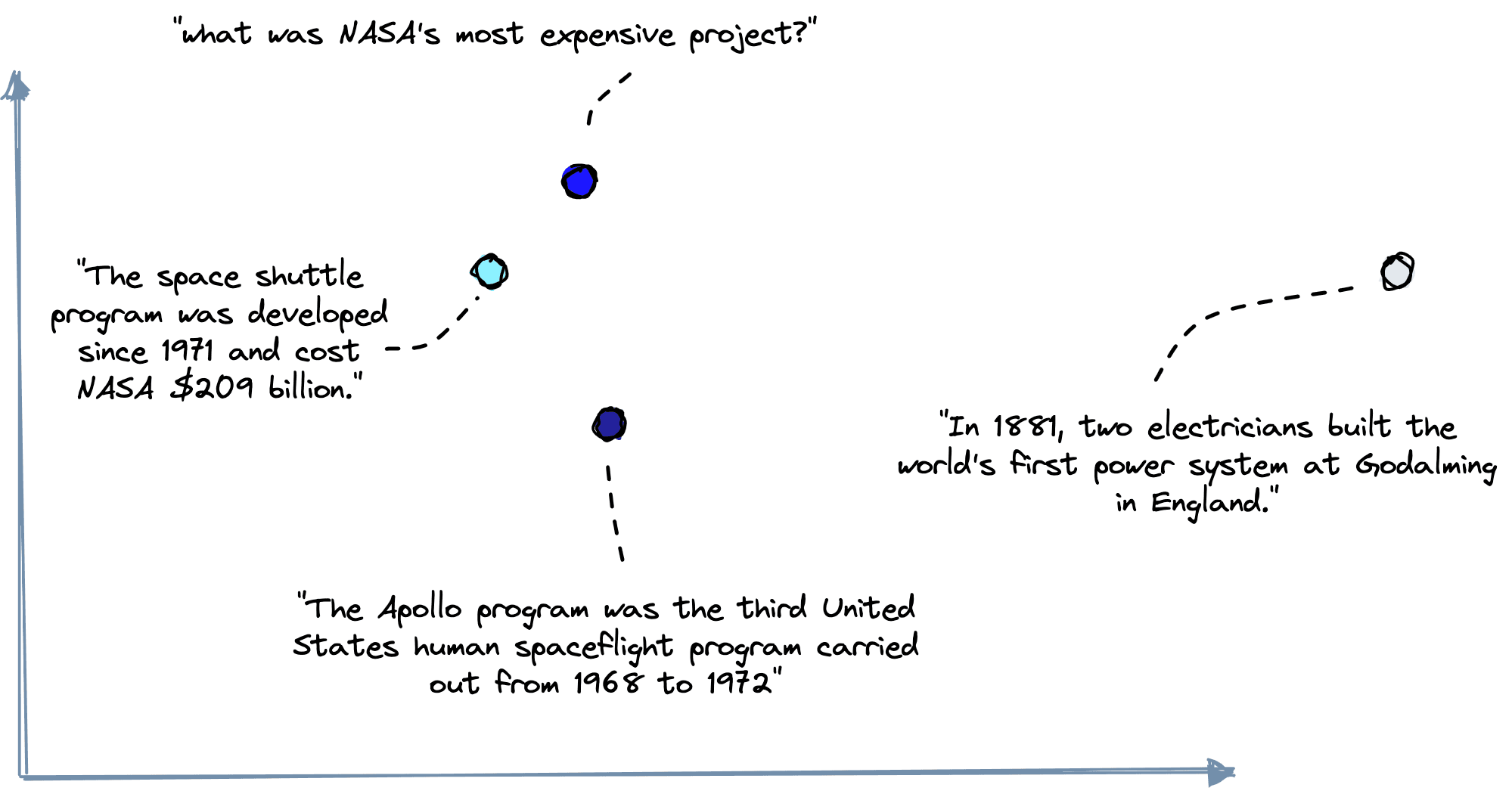
Using the retriever model, we can take text content and encode it into a vector embedding that numerically represents the text’s original “human” meaning.
The vector database is where we store these vectors. If we introduce a new query vector to an already populated vector database, we could use similarity metrics to measure its proximity to existing vectors. From there, we return the top k most similar vectors (e.g., the most semantically similar contexts).
We will use Haystack’s EmbeddingRetriever component, which allows us to use any retriever model from the Sentence Transformers library hosted via the Hugging Face Model Hub.
First, we check that we are using the GPU, as this will make the retriever embedding process much faster.
import torch
# confirm GPU is available, outputs True if so
torch.cuda.is_available()The embedding step will still run if you do not have access to a CUDA-enabled GPU, but it may be slow. We initialize the EmbeddingRetriever component with the all_datasets_v3_mpnet-base model shown above.
from haystack.retriever.dense import EmbeddingRetriever
retriever = EmbeddingRetriever(
document_store=document_store,
embedding_model="flax-sentence-embeddings/all_datasets_v3_mpnet-base",
model_format="sentence_transformers"
)We call the document_store.update_embeddings method and pass in our new retriever to begin the embedding process.
document_store.update_embeddings(
retriever,
batch_size=128
)The batch_size parameter can be increased to reduce the embedding time. However, it is limited by GPU/CPU hardware and cannot be increased beyond those limits.
We can confirm that our document store now contains the embedded documents by calling document_store.get_embedding_count() or checking the embedding count in the Pinecone dashboard.
Before moving on to the next step, we can test our document retrieval:
from haystack.pipelines import DocumentSearchPipeline
from haystack.utils import print_documents
search_pipe = DocumentSearchPipeline(retriever)
result = search_pipe.run(
query="When was the first electric power system built?",
params={"Retriever": {"top_k": 2}}
)
print_documents(result)
Query: When was the first electric power system built?
{'content': 'Electric power system History In 1881, two electricians built '
"the world's first power system at Godalming in England. It was "
'...',
'name': None}
{'content': 'by a coal burning steam engine, and it started generating '
'electricity on September 4, 1882, serving an initial load of '
'...',
'name': None}
It looks like we’re returning good results. We now have the first two components of our LFQA pipeline: the document store and retriever. Let’s move on to the final component.
Generator
The generator is the component that builds our answer. Generators are sequence-to-sequence (Seq2Seq) models that take the query and retrieved contexts as input and use them to generate an output, the answer.
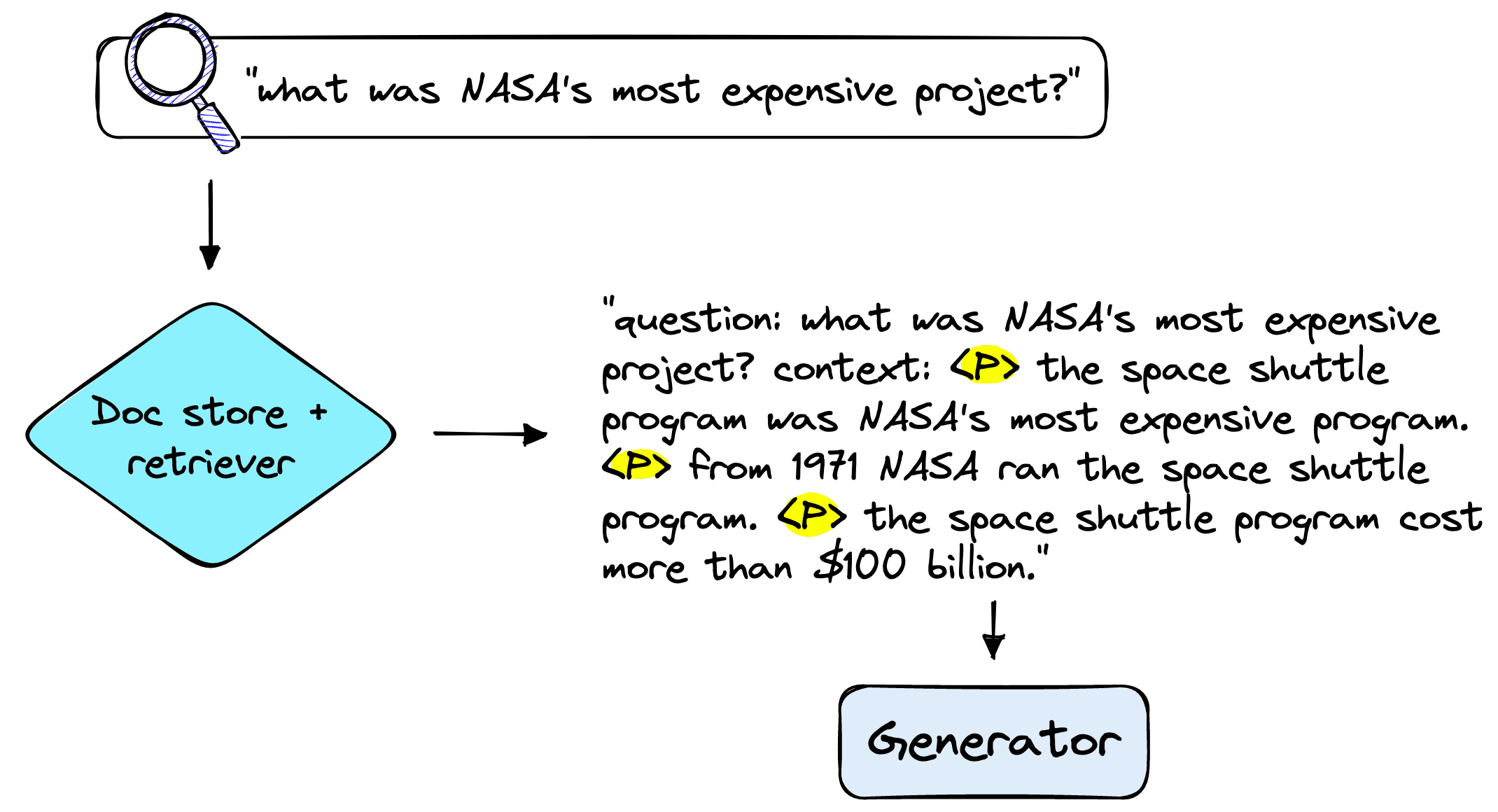
We initialize the generator using Haystack’s Seq2SeqGenerator with a model trained specifically for LFQA, for example, vblagoje/bart_lfqa or yjernite/bart_eli5 [1].
from haystack.generator.transformers import Seq2SeqGenerator
generator = Seq2SeqGenerator(model_name_or_path="vblagoje/bart_lfqa")Now we can initialize the entire abstractive QA pipeline using Haystack’s GenerativeQAPipeline object. This pipeline combines all three components, with the document store included as part of the retriever.
from haystack.pipelines import GenerativeQAPipeline
pipe = GenerativeQAPipeline(generator, retriever)With that, our abstractive QA pipeline is ready, and we can move on to making some queries.
Querying
When querying, we can specify the number of contexts for our retriever to return and the number of answers for our generator to generate using the top_k parameters.
result = pipe.run(
query="what was the war of currents?",
params={
"Retriever": {"top_k": 3},
"Generator": {"top_k": 1}
})
result{'query': 'what was the war of currents?',
'answers': [<Answer {'answer':
"The War of Currents was the rivalry between Thomas Edison and
George Westinghouse's companies over which form of transmission
(direct or alternating current) was superior.",
'type': 'generative', 'score': None, 'context': None, ...}}>],
'documents': [<Document: {'content': 'consultant at the Westinghouse...',
'content_type': 'text', 'score': 0.5010574158160604,
'meta': {'article_title': 'Electric power system', 'section_title': 'History'}
...}>,
<Document: {'content': 'of the British administration...}>,
<Document: {'content': 'of migration began, this state...}>],
'root_node': 'Query',
'params': {'Retriever': {'top_k': 3}, 'Generator': {'top_k': 1}},
'node_id': 'Generator'}There’s a lot here, but we can see that we have 1 final answer, followed by the 3 retrieved contexts. It’s hard to understand what is happening here, so we can use Haystack’s print_answer util to clean up the output.
from haystack.utils import print_answers
result = pipe.run(
query="what was the war of currents?",
params={
"Retriever": {"top_k": 3},
"Generator": {"top_k": 1}
})
print_answers(result, details="minimum")
Query: what was the war of currents?
Answers:
[ { 'answer': 'The War of Currents was the rivalry between Thomas Edison '
"and George Westinghouse's companies over which form of "
'transmission (direct or alternating current) was superior.'}]
Our output is now much more readable. The answer looks good, but there is not much detail. When we find an answer is either not good or lacks detail, there can be two reasons for this:
- The generator model has not been trained on data that includes information about the “war on currents”, so it has not memorized this information within its model weights.
- We have not returned any contexts that contain the answer, so the generator has no reliable external sources of information.
If neither condition is satisfied, the generator cannot produce a factually correct answer. However, in our case, we are returning some good external context. We can try and return more detail by increasing the number of contexts retrieved.
result = pipe.run(
query="what was the war of currents?",
params={
"Retriever": {"top_k": 10},
"Generator": {"top_k": 1}
})
print_answers(result, details="minimum")
Query: what was the war of currents?
Answers:
[ { 'answer': 'The "War of Currents" was a rivalry between Edison and '
'George Westinghouse over the use of alternating current '
'(AC) in power transmission. In 1891, the first major power '
'system that was designed to drive a generator with '
'alternating current was installed in the United States. '
'This system was called the "Westinghouse Electric System" '
'(WES) and was the first to use alternating current to power '
'a generator. By the end of the 19th century, the WES system '
'had become the dominant form of power transmission in the '
'U.S. and the rest of the world. However, there was still a '
'lot of competition between the two power companies over '
'which form of transmission was better. In the early 1900s, '
'the two companies were still at odds over whether AC or DC '
'should be used to power the power grid. In 1902, the '
'Supreme Court ruled that DC was superior to AC, and in '
'1903, Congress passed the Emancipation Proclamation, which '
'prohibited'}]
Now we’re seeing much more information. The latter half does descend into nonscensical gibberish, most likely because the higher top_k value retrieved several irrelevant contexts. However, given a larger dataset we could likely avoid this. We can also compare these results to an answer generated without any context by querying the generator directly.
result = generator.predict(
query="what was the war of currents?",
documents=[Document(content="")],
top_k=1
)
print_answers(result, details="minimum")
Query: what was the war of currents?
Answers:
[{'answer': 'I\'m not sure what you mean by "war".'}]
Clearly, the retrieved contexts are important. Although this isn’t always the case, for example, if we ask about a more well-known fact:
result = generator.predict(
query="who was the first person on the moon?",
documents=[Document(content="")],
top_k=1
)
print_answers(result, details="minimum")
Query: who was the first person on the moon?
Answers:
[{'answer': 'The first man to walk on the moon was Neil Armstrong.'}]
For general knowledge queries, the generator model can often pull the answer directly from its own “memory” (the model weights optimized during training), where it may have seen training data containing the answer. Larger models have a larger memory and, in turn, are better at direct answer generation.
When we ask more specific questions, like our question about the war on currents, both smaller and larger generators rarely return good answers without an external data source.
We can ask a few more questions:
result = pipe.run(
query="when was the first electric power system built?",
params={
"Retriever": {"top_k": 3},
"Generator": {"top_k": 1}
})
print_answers(result, details="minimum")
Query: when was the first electric power system built?
Answers:
[ { 'answer': 'The first steam powered power station was built in 1881 at '
'Godalming in England. It was powered by two waterwheels and '
'produced an alternating current that in turn supplied seven '
'Siemens arc lamps at 250 volts and 34 incandescent lamps at '
'40 volts. The power station initially powered around 3,000 '
'lamps for 59 customers. By 1888, the power companies had '
'built thousands of power systems (both direct and '
'alternating current) in the United States and Europe.'}]
To confirm that this answer is correct, we can check the contexts used to generate the answer.
for doc in result['documents']:
print(doc.content, end='\n---\n')Electric power system History In 1881, two electricians built the world's first power system at Godalming in England...
---
By 1888, the electric power industry was flourishing, and power companies had built thousands of power systems (both direct...
---
by a coal burning steam engine, and it started generating electricity on September 4, 1882, serving an initial load of 400...
---
In this case, the answer looks correct. If we ask a question and no relevant contexts are retrieved, the generator will typically return nonsensical or false answers, like with this question about COVID-19:
result = pipe.run(
query="where did COVID-19 originate?",
params={
"Retriever": {"top_k": 3},
"Generator": {"top_k": 1}
})
print_answers(result, details="minimum")
Query: where did COVID-19 originate?
Answers:
[ { 'answer': "COVID-19 isn't a virus, it's a bacterium. It's a virus that "
"infects bacteria. There's no way to know where it came "
'from.'}]
The issue with nonsensical or false answers is one drawback of the LFQA approach. However, it can be mitigated somewhat by implementing thresholds to filter our low confidence answers and referring to the sources behind generated answers.
Let’s finish with a final few questions.
result = pipe.run(
query="what was NASAs most expensive project?",
params={
"Retriever": {"top_k": 3},
"Generator": {"top_k": 1}
}
)
print_answers(result, details="minimum")
Query: what was NASAs most expensive project?
Answers:
[ { 'answer': 'The Space Shuttle was the most expensive project in the '
'history of NASA. It cost over $100 billion to build.'}]
result = pipe.run(
query="tell me something interesting about the history of Earth?",
params={
"Retriever": {"top_k": 3},
"Generator": {"top_k": 1}
})
print_answers(result, details="minimum")
Query: tell me something interesting about the history of Earth?
Answers:
[ { 'answer': "I don't know if this is what you're looking for, but I've "
"always been fascinated by the fact that the Earth's "
'magnetic field is so weak compared to the rest of the solar '
'system. The magnetic field of the Earth is about 1/10th the '
'strength of that of the strongest magnetic field in the '
'Solar System.'}]
result = pipe.run(
query="who created the Nobel prize and why?",
params={
"Retriever": {"top_k": 10},
"Generator": {"top_k": 1}
})
print_answers(result, details="minimum")
Query: who created the Nobel prize and why?
Answers:
[ { 'answer': 'Alfred Nobel was a Swedish industrialist and philanthropist '
'who died in 1896. His will specified that his fortune be '
'used to create a series of prizes for those who confer the '
'"greatest benefit on mankind" in physics, chemistry, '
'physiology or medicine, literature, and peace. The Nobel '
"Prize was funded by Alfred Nobel's personal fortune, 94% of "
'his fortune to the Nobel Foundation that now forms the '
'economic base of the Nobel Prize.'}]
result = pipe.run(
query="how is the nobel prize funded?",
params={
"Retriever": {"top_k": 10},
"Generator": {"top_k": 1}
})
print_answers(result, details="minimum")
Query: how is the nobel prize funded?
Answers:
[ { 'answer': 'The Nobel Prizes are awarded by the Swedish Academy of '
'Sciences, which is a non-profit organization that was '
'founded by Alfred Nobel in 1900. It is funded by his '
'personal fortune, which now forms the economic base of the '
'Nobel Prize.'}]
That’s it for this walkthrough of Long-Form Question-Answering with Haystack. As mentioned, there are many approaches to building a pipeline like this. Many different retriever and generator models can be tested by simply switching the model names for other retriever/generator models.
With the wide variety of off-the-shelf models, many use cases can be built with little more than what we have worked through here. All that is left is to find potential use cases and try implementing LFQA (or other QA pipelines) and reap the benefits of enhanced data visibility and workplace efficiency that come with it.
Resources
[1] A. Fan, et al., ELI5: Long Form Question Answering (2019)
Was this article helpful?