How to fight misinformation in the digital era.
Times of crisis are perfect for controversial statements. Do you think COVID-19 was genetically engineered as a biological weapon? And that climate policies will hurt working families and ruin the economy? What about Bitcoin? Is it the latest economic revolution, or a massive fraudulent system? Hard to tell since we’re living in the era of fake news.
Fake news consists of deliberate misinformation under the guise of being authentic news, spread via some communication channel, and produced with a particular objective like generating revenue, promoting or discrediting a public figure, a political movement, an organization, etc.
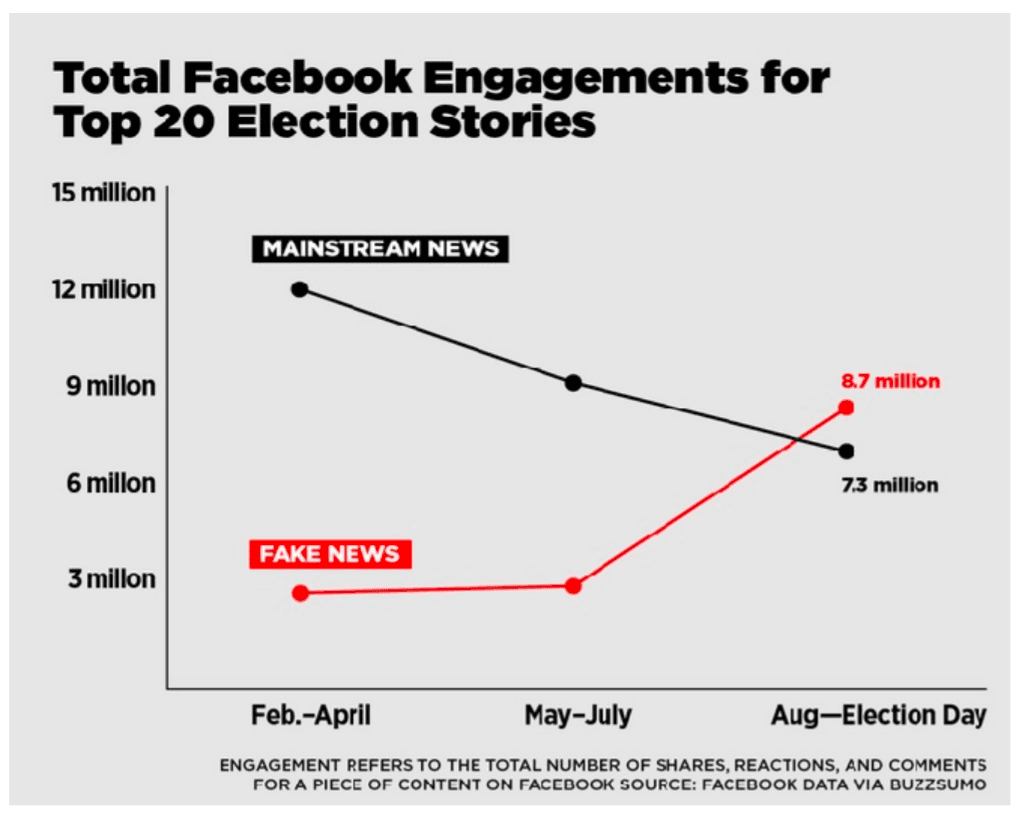
Fake news travels six times faster on Twitter and reaches significantly more people than actual news. And from the big universe of fake news, false political news travels farther, faster, deeper, and more broadly than any other type.
During the 2018 national elections in Brazil, WhatsApp was used to spread alarming amounts of misinformation, rumours and false news favouring Jair Bolsonaro. In 2019, the two main Indian political parties took these tactics to a new scale by trying to influence India’s 900 million eligible voters through creating content on Facebook and spreading it on WhatsApp.
But these tactics aren’t only applied in the political arena: They also involve activities from manipulating share prices to attacking commercial rivals with fake customer critics.
How can we deal with this problem? Are we supposed to just live with it? Fortunately we don’t have to, and we can use Machine Learning to identify fake news. Let’s see how.
Embeddings
Fake documents and articles contain attributes and linguistic signs that can be used to reveal patterns. Considering their textual components, features like author, context, and writing style can help in identifying fake news.
But before applying any Machine Learning technique to text, we need to format the input data into a numerical representation that can be understood by the model we’re building. Here’s where the problem begins: Traditional techniques like Term frequency–inverse document frequency (TF-IDF) result in high-dimensional representations of linguistic information, which lead to some negative effects like the Curse of Dimensionality, increasing the error of our model as the number of features increases.
One way to overcome these problems is through word and sentence embeddings, which give us low dimensional, distributed representations of the data. Embeddings are representations of words or sentences in multidimensional spaces such that words or sentences with similar meanings have similar embeddings. It means that each word or sentence is mapped to the vector of real numbers that represents those words or sentences.
This is what an embedding for the word “king” looks like:

Embeddings not only convert the word or text to a numerical representation, but also identify and incorporate their semantic and syntax information.
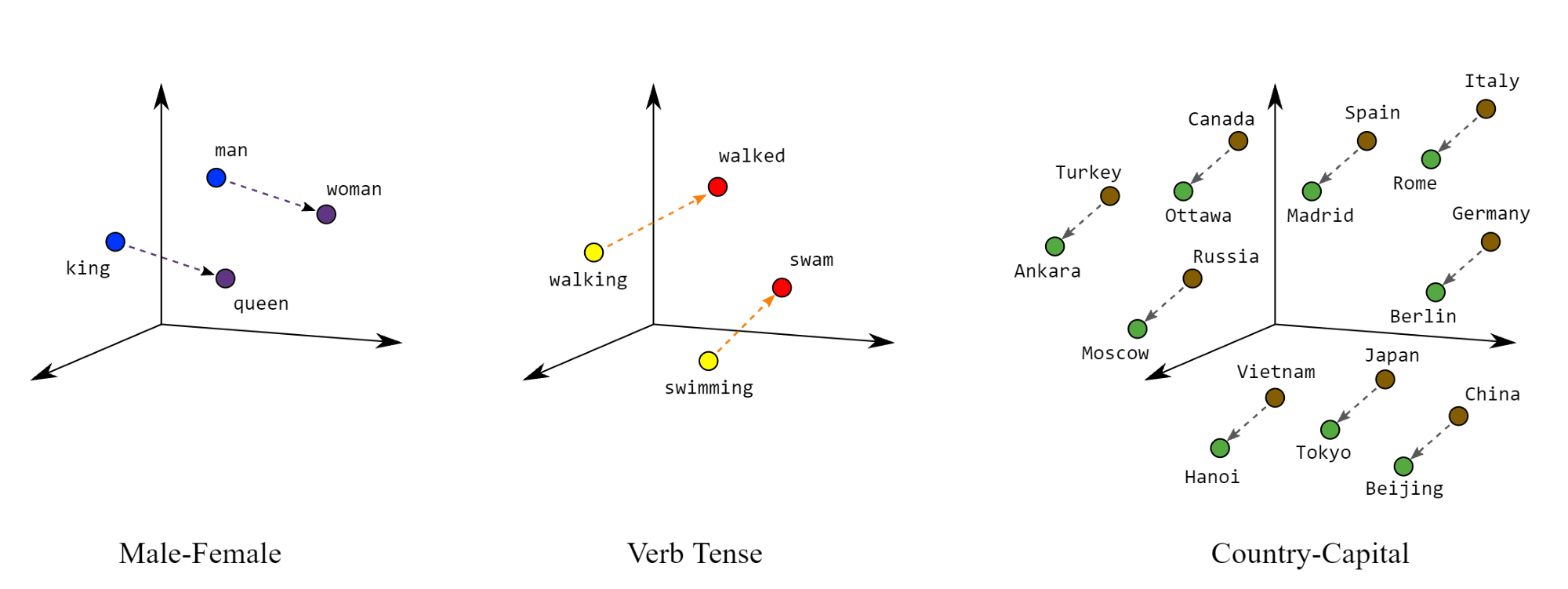
Embeddings are distributed representations of words and text in a continuous vector space and can facilitate tasks like semantic search, clustering, recommendation, sentiment analysis, question-answering, or deduplication.
How to create embeddings
There are a number of ways to create embeddings and many techniques for capturing the important structure of a high dimensional space in a low dimensional space. Although methods like principal component analysis (PCA) have been used to create embedding, newer techniques have shown better performance. Let’s begin with word embeddings.
Word embeddings
Word embeddings are vectorized representations of words and perhaps one of the most important innovations in the Natural Language Processing (NLP) discipline. Let’s see look at of the main algorithms already in use:
Word2vec
Since its inception in 2013, Word2vec has become widely used both in research and commercial areas. The idea behind it is that it’s possible to predict a word based on its context (neighbouring words) under the assumption that the meaning of a word can be inferred by the company it keeps. Word2vec can use two architectures to produce a distributed representation of words: continuous bag-of-words or CBOW (where we predict the current word from a window of surrounding context words) and Skip-gram (where we try to predict the context words using the main word).
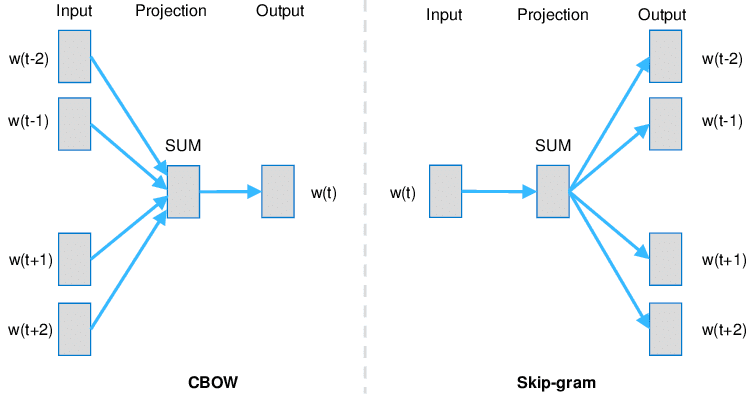
GloVe
Developed by Stanford, GloVe (Global Vectors for Word Representation) is another method to create word embeddings. Its advantage over Word2Vec is that it doesn’t rely just on local statistics (local context information of the words), but incorporates global statistics (word co-occurrence) from the whole text corpus.
GloVe uses co-occurrence (how frequently two words appear together) statistics at a global text level to model the vector representations of words. This is an important aspect since word-word co-occurrences may carry rich semantic information. For example, in a large corpus the word “solid” is more likely to co-occur with “ice” than with “steam”, but the word “gas” probably co-occurs with “steam” more frequently than with “ice”.
Fasttext
Fasttext was developed by Facebook with the idea to use the internal structure of words to improve vector representations (creating “sub-words” from words), which is a huge advantage over other models.
Both in Word2Vec and GloVe an embedding is created for each word, and, as such, they can’t handle any words they haven’t encountered during their training. Alternatively, Fasttext can derive word vectors for unknown words, creating embeddings for words that weren’t seen before.

Sentence embeddings
Word embeddings are highly effective for tasks that don’t require comparisons between sentences or documents. But using word embeddings over large pieces of text can limit our understanding if we need to compute the semantic similarity of different texts, analyse intention, sentiment, or cluster them.
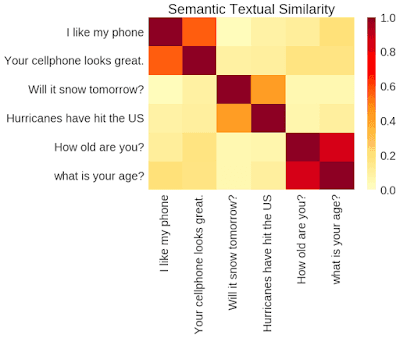
What if, instead of embedding individual words, we could embed sentences? Sentence embeddings are the extension of the key ideas behind word embeddings.
Doc2vec
Based on the Word2vec algorithm, Doc2vec represents pieces of texts (ranging from sentences to documents) as fixed-length, low dimensional embeddings. In this architecture, the two learning algorithms are Distributed Memory version of Paragraph Vector (PV-DM), and Distributed Bag of Words version of Paragraph Vector (PV-DBOW).
In PV-DM, a paragraph “id” is inserted as another word in an ordered sequence of words. PV-DM attempts to predict a word in the ordered sequence based on the other surrounding words in the sentence and the context provided by the paragraph “id”. On the other hand, PV-DBOW takes a given paragraph “id” and uses it to predict words in the window without any restriction on word order.
SentenceBERT
BERT is a word embedding algorithm (Transformer based) that can encode the context of words. This means that while standard word embedding algorithms would produce the same vector for “bank” whether it was “a grassy bank” or “the bank of England”, BERT would instead modify the encoding for “bank” based on the surrounding context.
This capability was extended from words to sentences through SentenceBERT (SBERT), which outputs sentence embeddings with an impressive speed performance. While finding the most similar sentence pair from 10K sentences took 65 hours with BERT, SBERT embeddings are created in around 5 seconds and compared with cosine similarity in around 0.01 seconds.
Universal Sentence Encoder (USE)
One technique that proved superior performance is the Universal Sentence Encoder (USE) developed by Google.
The idea is to design an embedding to solve multiple tasks and, based on the mistakes it makes on those, update the sentence embedding. Since the same embedding has to work on multiple generic tasks, it captures only the most informative features and discards noise. The intuition is that this will result in a generic embedding that transfers universally to a wide variety of NLP tasks such as relatedness, clustering, paraphrase detection and text classification.
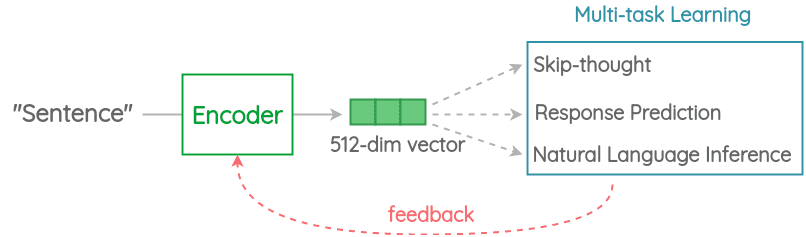
USE comes with two variations: one trained with Transformers and the other trained with Deep Averaging Network (DAN). While the one using Transformers has higher accuracy, it is computationally more intensive. Alternatively, the DAN variant aims at efficient inference despite a slightly reduced accuracy.
A classification problem
From a Machine Learning perspective, the challenge of identifying fake news can be translated into a classification problem: Given a text input, we want to classify it correctly as fake or not fake. Using embeddings in a classification task, we can classify the label of an unknown object (e.g. an unseen article) based on the labels of the most similar known objects (e.g. articles already labelled as “fake” or “not fake”).
Embedding models like Word2vec (for words) and Doc2vec (for sentences) can serve as feature extraction methods for the creation of various classifications tasks. After creating embeddings for our texts, we can train our model on these embeddings so it can learn to differentiate between misleading facts and real news. The classifier model is then evaluated and adjusted based on the results.
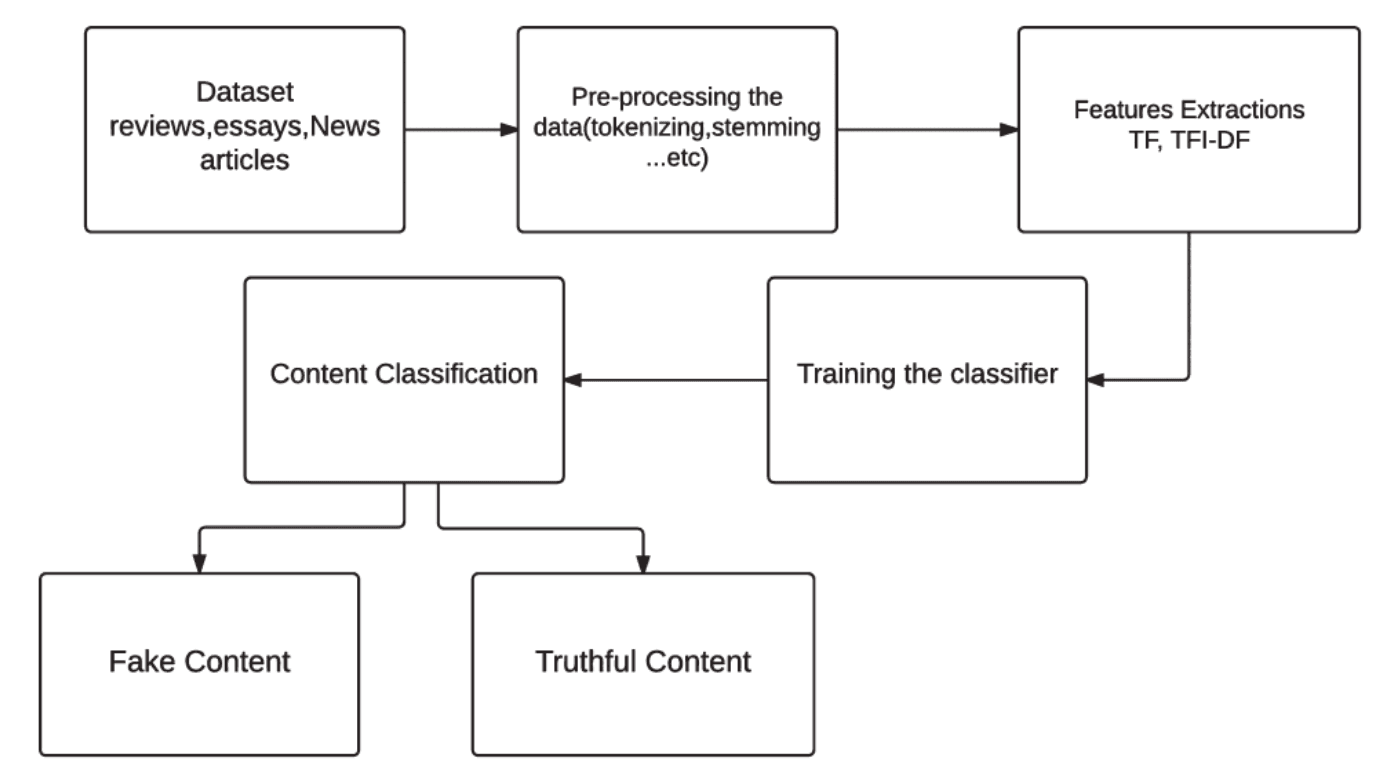
The process of converting text into embeddings results in fixed-length vector representations that attempt to encode each sentence key information. Next, we can compare the similarity (e.g. cosine similarity) between sentence embeddings in our dataset to identify potential references to fake news.
The future of misinformation
Today, machines are playing a key role in the fake news arena. Text-generation systems like GPT-3 have the ability to produce coherent text from minimal prompts: Feed it a title, and it will write a story. But can these systems also spot other model-generated outputs?
Machine language models like GPT-3 produce sentences by predicting the next word in a sequence of text. So, if they can predict most of the words in a given passage, it’s likely it was written by one of their own. This idea was tested using the Giant Language model Test Room (GLTR), where human-generated text showed a higher fraction of red and purple words (meaning a decreasing ease of predictability) in contrast to machine-generated text that showed a greater share of green and yellow words (meaning it was likely written by a language model).


But here’s the catch: a machine language model might be good at detecting its own output, but not necessarily the output of others.
With machines able to mass produce content, the future of fake news is a challenging one. But technology can also be used to solve this problem. Improving the way machines represent and process content can lead the way to new solutions. Specifically, embeddings can serve as an effective method to represent massive amounts of texts (or other types of content) in order to improve our understanding about fake news.
Was this article helpful?