Introducing support for sparse-dense embeddings for better search result
Advancements in AI continue to up the ante for what end-users expect out of their search experience. To keep up with these growing expectations, engineers are turning to the latest advancements in Large Language Models (LLMs) to deliver the best results possible.
While semantic search aims to meet these expectations, there are still use cases (e.g. searching for names or industry-specific jargon) that rely on keyword-search. Hybrid search combines the power of both semantic and keyword search to provide more relevant results than either one alone.
This is why we announced a hybrid index in private preview last year. With the hybrid index, we enabled our users to achieve better search results through keyword-aware semantic search. Since then, progress continues to be made with alternative sparse models (e.g. SPLADE, uniCOIL), leading to even more relevant results than BM25.
Incorporating feedback from our private preview, we’ve made many improvements to our existing index to leverage the latest LLMs and support keyword-aware semantic search in a completely new way. Our index now supports sparse-dense embeddings regardless of the model used, data type they represent, or data distribution. More ways to build means engineers can focus more on building great search applications.
This first-of-its-kind support for sparse-dense embeddings is now available in public preview for all users. Continue reading to learn more, and start building today.
An index powering industry-leading results
Before providing an overview of our upgraded index, let’s recap what we mean by dense and sparse vector embeddings.
- A dense vector embedding is a vector of fixed dimensions, typically between 100-1000, where every entry is almost always non-zero. In text retrieval, for example, they may represent the learned semantic meaning of texts by ML models like SBERT.
- A sparse vector embedding is a vector of a very large dimension (e.g. 100,000) where only a small fraction of its entries are non-zero. In text retrieval, sparse vectors typically represent term-level importance for documents and queries.
Since launching the private preview, our approach to supporting sparse-dense embeddings has evolved to set a new standard in sparse-dense support. The upgraded index is:
- Flexible: Send data - sparse or dense - to any index regardless of model or data type used. Support for more advanced use cases including multimodal search, boosting, and any other vector that has arbitrarily distributed, real-valued dense and sparse parts. Upon query, optionally weight dense and sparse components as you see fit.
- Simple: Get started quickly with an easy-to-use REST API or Python SDK. No need to spin up or configure a separate index to support sparse-dense use cases (e.g. hybrid search).
- First-of-its-kind: Support for data from any dense or sparse model. Leverage the latest LLMs (and learned sparse models) to achieve the most relevant results.
*Note: Indexes are currently configured to support s1 and p1 pod types with metric=dotproduct. You will receive an error message if you query an index configured with p2 pods or if you are using a metric other than “dotproduct”.
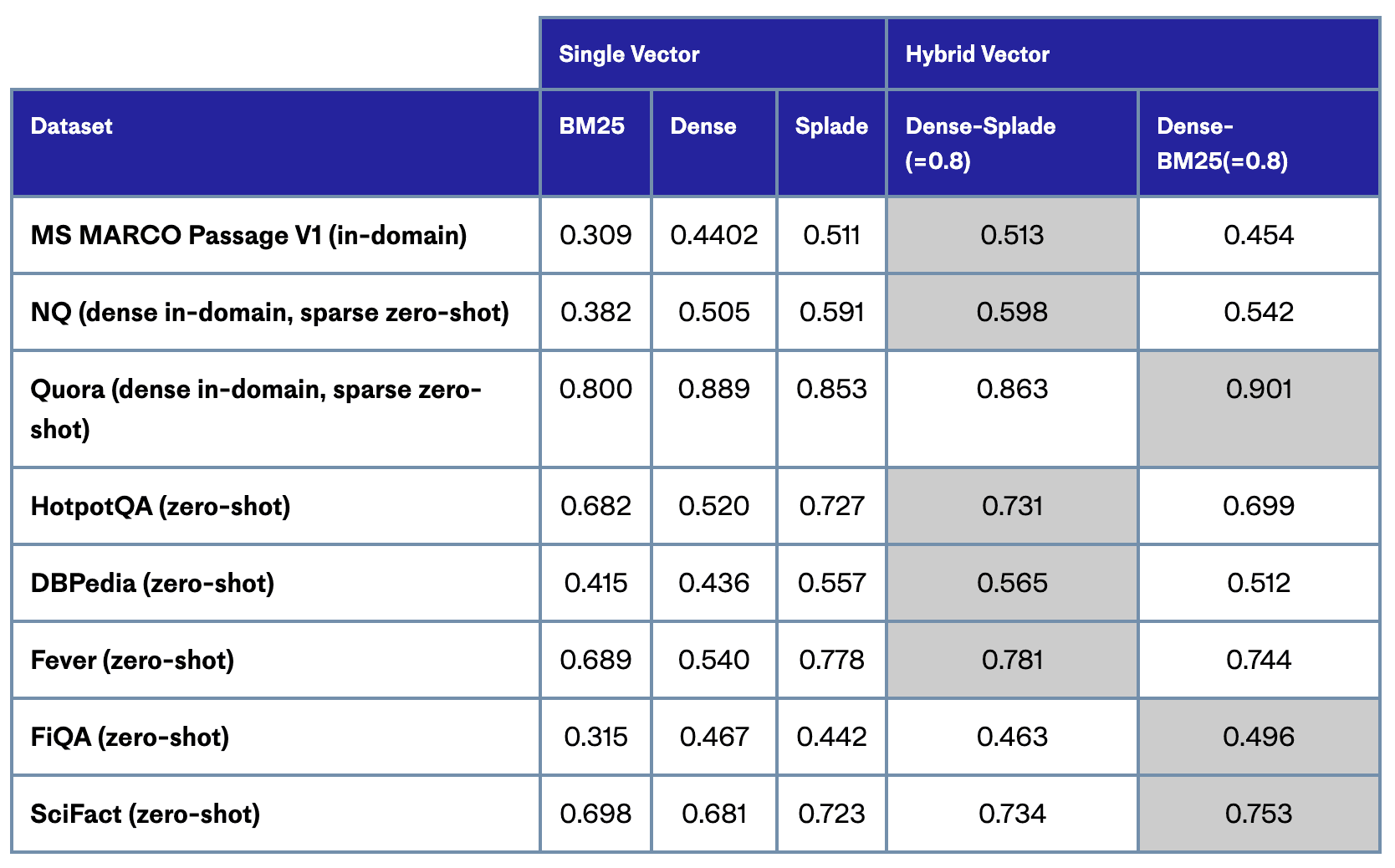
With sparse-dense index support, you are able to build a hybrid lexical-semantic text search engine and leverage new sparse methods like SPLADE. BM25 has long been the standard for ranking and relevance in text search applications, however, our research shows that learned sparse models like SPLADE generally perform better than either dense or fine-tuned BM25. In all cases, however, a hybrid, sparse-dense approach leads to better results than either approach alone - especially if using SPLADE over BM25 for sparse vectors.
Per the below results, having the flexibility to combine any sparse representation with dense embeddings means you can achieve the best results possible.
Table: Results of testing with NDCG@1000. Highlighted cells represent the best results per dataset.
Excited by these advancements, Daniel Vliegenthart, CTO at Parsel AI, shared:
Pinecone’s sparse-dense hybrid search technology allows us to offer a more comprehensive—and faster—search experience that efficiently balances search term occurrence with semantic nuances of user queries. This ultimately transforms how our users interrogate high-value information. We are confident that the adoption of the SPLADE model for sparse vector generation by Pinecone will continue to push the boundaries of intelligent search.
If you are wanting to get started or experiment with SPLADE, we have many resources including a notebook and a technical guide.
How it works
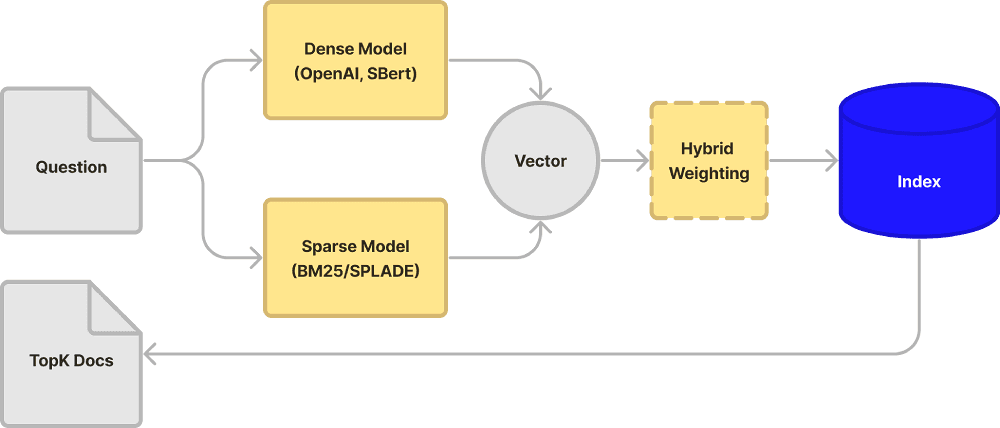
Get started by following the steps outlined below to upsert and query sparse-dense and dense vector embeddings. All indexes are pre-configured to store both sparse and dense data, but only indexes on s1 and p1 pods with metric=dotproduct can be queried with sparse-dense values. Refer to the documentation for more in-depth instructions.
- Create an index via the Python SDK or REST API. (Note: If you are already using the Python client, you must upgrade to version 2.2.1 or higher.)
# pip install pinecone-client
import pinecone
pinecone.init("YOUR API KEY", "YOUR ENVIRONMENT")
index = pinecone.create_index(pod_type="s1", metric="dotproduct")
- Generate vectors:
- For dense vectors, we recommend OpenAI’s text-embedding-ada-002 or SentenceTransformers. But any dense vector embedding will do.
- For sparse vectors, we recommend using SPLADE or BM25.
- For upsert, sparse and dense components must be combined into a single vector (note: sparse vectors can’t be stored without a dense vector).
- Query: Request TopK results from the index via query. Prior to query, you can optionally weight your vectors to be more sparse or dense.
upsert = {"vectors": [{
"id": "1",
"values": [0.1, 0.2, 0.3],
"sparse_values": {
"indices": [2, 4, 6],
"values": [0.1, 0.3, 0.5]
}
}]}See the full flow of operations - for upsert (top) and query (bottom) - in the below diagrams:
Storage capacity is a function of both the sparse and dense components. For the sparse component, capacity decreases as more elements (non-zero coordinates) are specified. The below capacity projections for s1 and p1 pods are based on SPLADE.
| Pod Type | Vector Type | Dense Dimensions | Sparse non-zero coordinates | Capacity (# of Vectors) |
|---|---|---|---|---|
| S1 | Sparse-Dense | 768 | 120 | 2.8M |
| P1 | Sparse-Dense | 768 | 120 | 900k |
| S1 | Dense | 768 | N/A | 5M |
| P1 | Dense | 768 | N/A | 1M |
As always, actual capacity and performance may vary based on use case and datasets, so we encourage you to experiment and contact us for help if needed. All index types in Pinecone come with metadata filtering, vertical and horizontal scaling, snapshots, expert support, and more.
Try it today
Support for the upgraded sparse-dense index is now in public preview. Read the docs to get started, and stay tuned for more updates and technical deep dives.
Was this article helpful?