Introducing the hybrid index to enable keyword-aware semantic search

New approach to hybrid search leads to more relevant results
Growing expectations around search (that our applications should automatically understand our intent) have led to important advancements — like semantic search — that go beyond keyword search capabilities. However, both keyword and semantic search have important tradeoffs to consider:
- Keyword search can miss important context. Keyword methods can struggle even with simple synonyms without manual tuning.
- Semantic search can miss important keywords. Semantic search may overlook details searching for certain keywords (such as names, industry-specific jargon, or rare words), providing related but not the best results.
In fact, for text-search use cases, a hybrid approach — combining keyword and semantic search — provides more relevant results than either one alone. But running two separate search solutions plus a third system for combining the results is an engineering nightmare.
That’s why we’re excited to announce the hybrid vector index, a first-of-its-kind solution that lets engineers easily build keyword-aware semantic search into their applications. Continue reading to learn more.
Level-up your search with keyword-aware semantic search, powered by the Pinecone hybrid vector index
Companies are turning to hybrid search techniques to help users get more relevant search results. The ability to search based on both what users say and what they mean leads to better results and happier users.
Our research shows the impact of hybrid search on relevance compared to standalone keyword and semantic search: Whether searching in-domain or out-of-domain from the original training data, the hybrid results are better across the board.
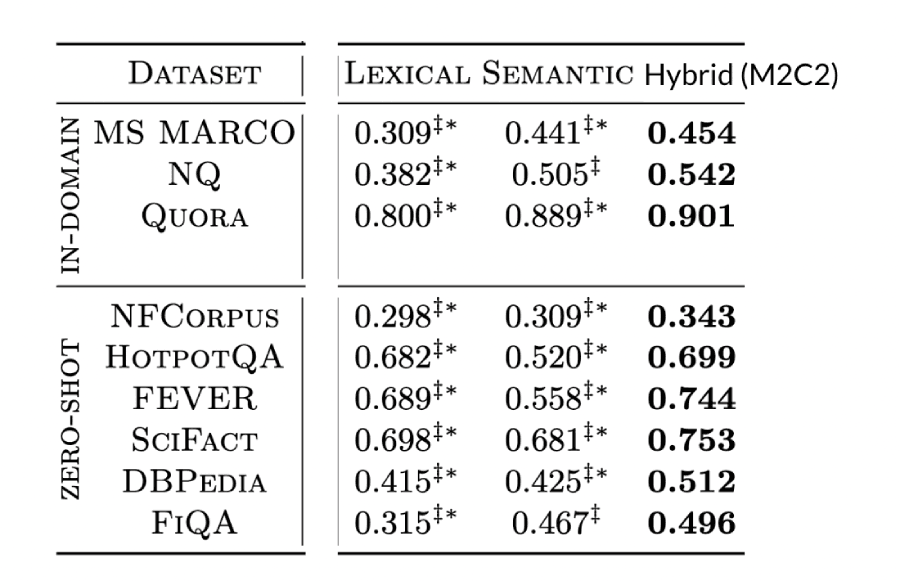
We also know there’s a growing area of research around using hybrid vectors for use cases outside of text (e.g. creating sparse vectors from a learned sparse model (like SPLADE) instead of BM25). However, existing solutions make doing this no easy feat. Not only do you need to run multiple solutions — keyword and vector search systems alongside a reranking system — but you also have to know which levers to pull in order to transform your vectors to work with these existing solutions.
With the new hybrid vector index, you don’t need to be an ML expert to build hybrid search for these use cases. We’ve designed it to be:
- Simple: No need to manage multiple solutions. It’s not a vector index, an inverted index, and a re-ranker duct-taped together. It’s one hybrid index.
- Flexible: A first-of-its-kind hybrid index to store and search across both dense and sparse representations of any kind of data, not just text.
- Scalable: Support for billions of vectors with low latency and zero-downtime scaling.
And since text is the predominant use case for hybrid search, we’re adding a hybrid endpoint to the Pinecone API. This endpoint accepts vector embeddings (dense vectors) and term frequencies (sparse vectors) for uploading or querying the hybrid index. This new, hybrid API endpoint provides:
- Convenience: Saves you time and pre-processing steps to normalize and combine vectors. Accepts dense vectors from any language model such as SentenceBERT (SBERT), and sparse vectors from any tokenization library such as Hugging Face Tokenizers.
- Consistency: Gives you the benefits of tried-and-true BM25 scoring for the keyword part of hybrid search.
- Control: Adjust the weight of keyword and semantic relevance when querying. Gives you control of importance for keyword vs. semantic.
Hybrid search is a powerful capability that we believe should be accessible to all. As Nils Reimers, the creator of Sentence Transformers, put it:
Semantic search can largely improve search performance, but there are still some shortcomings, especially when it comes to keyword-specific queries. Combining semantic search capabilities with traditional BM25 solves many of these issues, but so far the available solutions are not practical to deploy as you need to use two different systems. This is why I am so excited that Pinecone is adding keyword semantic search functionality to their managed vector database. It will give even better search results for many use-cases.
How it works
Before diving into how our hybrid search solution works, let’s define some key terms:
- A dense vector is a vector of fixed dimensions, typically between 100-1000, where every entry is almost always non-zero. They represent the learned semantic meaning of texts by ML models like SBERT.
- A sparse vector is a vector of a very large dimension (e.g. 1,000,000), where only a small fraction of its entries are non-zero. They represent important keywords inside documents.
We designed our hybrid search to be easy to use and scale, which we’ll demonstrate with the following example.
Imagine you need to build a feature to let users browse and analyze employee survey responses. You want to support searches for both general concepts (e.g. company offsite in Greece) and company-specific terms (e.g. Pinecone).
Here’s how to do it with Pinecone’s hybrid index:
- Sign in to Pinecone to get an API key and create a hybrid index (
s1h).
headers = {"Api-Key": APIKEY}
config = {
"name": "my-index",
"dimension": 328,
"metric": "dotproduct",
"pods": 1,
"pod_type": "s1h",
}
requests.post('https://controller.<env>.pinecone.io/databases', headers=headers, json=config)
- Generate dense vectors for the survey responses through a dense embedding model such as SBERT. Use a tokenizer or analyzer tool (such as those from spaCy or HuggingFace) to generate sparse vectors (based on term frequency) for the same survey responses.
from sentence_transformers import SentenceTransformer
from transformers import AutoTokenizer
from collections import Counter
import requests
tokenizer = AutoTokenizer.from_pretrained('transfo-xl-wt103')
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
doc = "Visiting the parthenon during the Pinecone offsite was an awesome experience."
vector = model.encode([doc]).tolist() # [0.1, -0.1, 0.2, ...]
tokens = dict(Counter(tokenizer.encode(doc))) # {5:1, 10500:1, 7:1, ... }
- Upload both dense and sparse vectors into a Pinecone hybrid index using the hybrid API. Your sparse vectors will be automatically normalized and transformed to provide search results equivalent to BM25.
upsert = {
"vectors": [{
"id": "example-id-1",
"values": vector, # Dense Vector
"sparse_values": tokens, # Sparse Vector
"metadata": {'text': doc}
}],
}
requests.post('https://<index-name>-<project-id>.svc.<env>.pinecone.io/hybrid/vectors/upsert', json=payload, headers=headers)
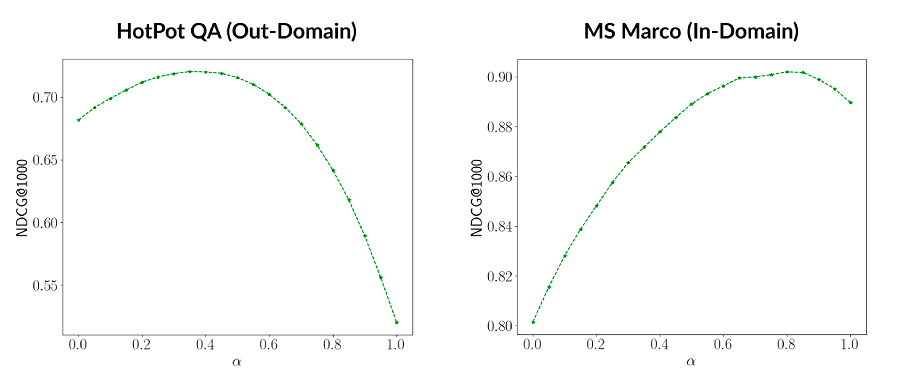
- Now you can query the index, providing the sparse and dense vectors (which are combined into sparse-dense hybrid vectors using linear-combination fusion) along with a weight for keyword relevance (“alpha”).
Alpha=1will provide a purely semantic-based search result andalpha=0will provide a purely keyword-based result equivalent to BM25. The default value is0.5.
question = "pinecone athens offsite"
query = {
"topK": 2,
"vector": model.encode([question]).tolist(),
"sparseVector": dict(Counter(tokenizer.encode(question))),
"alpha": 0.5 # Weight
}
resp = requests.post('https://<index-name>-<project-id>.svc.<env>.pinecone.io/hybrid/query', json=query, headers=headers)
- Query results are then retrieved (scored by max dot product), and you’re able to see the top results for survey responses related to “Greece offsite”, specifically those about “Pinecone”.
# Matches
resp.json()['matches']
[{'id': '3706692',
'score': 0.763926864,
'values': [],
'sparseValues': {},
'metadata': {'text': 'Visiting the parthenon during the Pinecone offsite was an awesome experience.'}},
{'id': '3393693',
'score': 0.582026243,
'values': [],
'sparseValues': {},
'metadata': {'context': “Last time i visited greece was on my own.”}}]
Just like that, you can build keyword-aware semantic search into your applications, and provide great results without tuning models or indexes, or managing multiple systems.
The below diagram displays both the upsert and query paths.
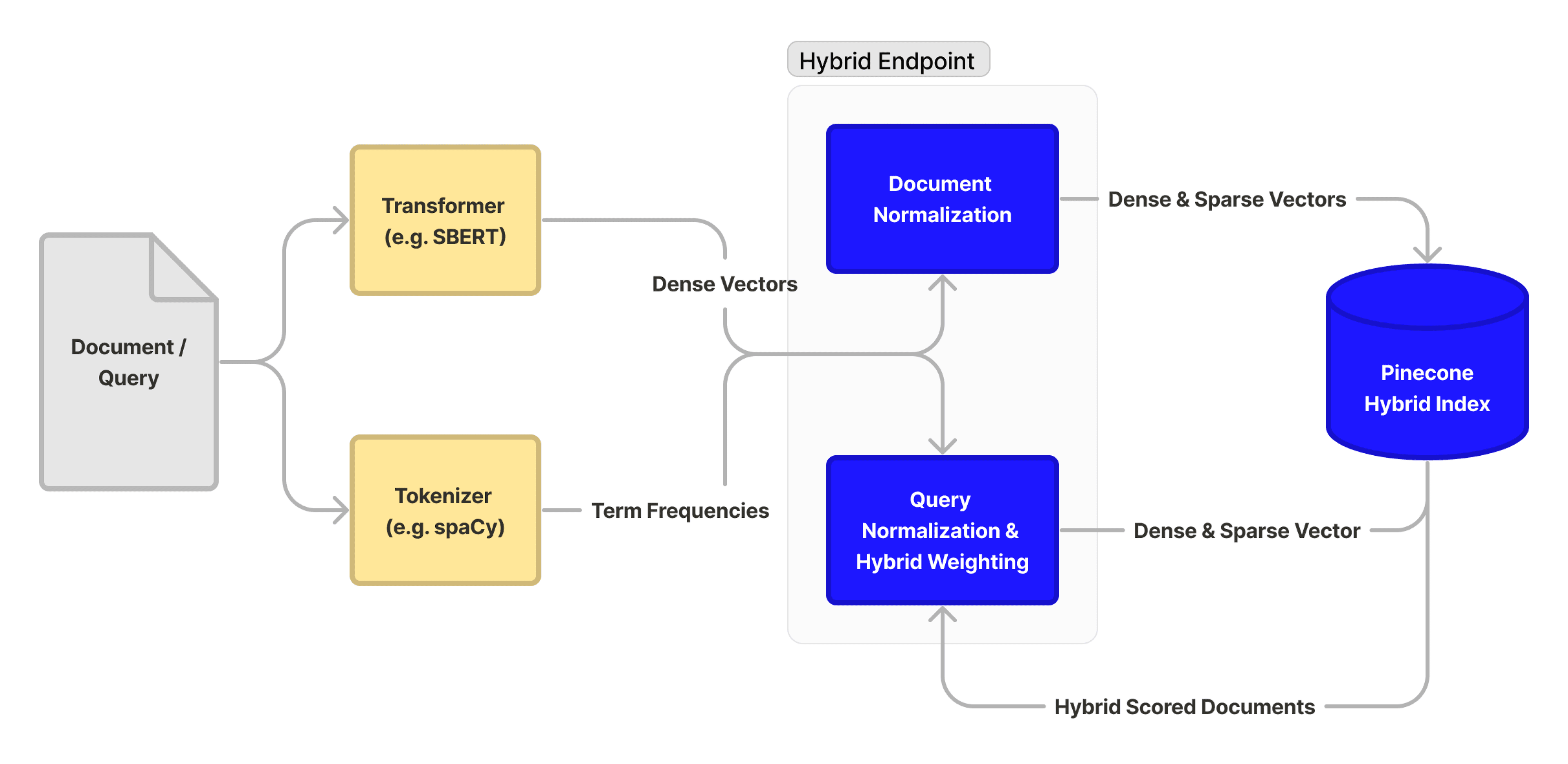
Pinecone is built for high-performance vector search at massive scale, and this new hybrid index is no exception. You can expect the same capacity (around 5 million 768-dimension vectors per pod), throughput, and latency as our storage-optimized s1 pods. As always, actual capacity and performance may vary based on use case and datasets, so we encourage you to experiment and contact us for help if needed. All index types in Pinecone come with metadata filtering, vertical and horizontal scaling, snapshots, expert support, and more.
Try it today
Read the docs, and stay tuned for more updates and technical deep dives (including how to get started with hybrid search).
Was this article helpful?