How a Knowledge Engine Works: From Artifacts to Agent-Ready Answers
What is a knowledge engine?
Anyone shipping agents in production today has hit the same wall. The model isn't usually the problem. Frontier models reason just fine. What breaks is everything before the reasoning step: the agent gets a task, decides it needs information, searches, retrieves, evaluates, decides it needs more, searches again, fragments the picture together, loops. By the time the model is ready to answer, most of the token and latency budget is already gone.
Most of an agent's effort goes to orientation, not reasoning. The discipline that has emerged around closing this gap has a name now: context engineering. Shape data into knowledge the model can use, instead of asking the agent to reassemble it from raw data on every query.
The hard part isn't the concept. It's operationalizing context engineering across the dozens of domains a real company runs on. This article walks through what a knowledge engine is, the infrastructure category that makes context engineering work at scale: how one is built, how agents query it, and what changes when you stop bolting agents onto brute-force retrieval and start running them on infrastructure designed for the workload.
Walk into almost any SaaS company that's trying to put agents into production today, and the picture looks roughly the same. The data lives in a data warehouse, and also in Salesforce, Slack, Gong, Gmail, Jira, and Google Drive. Engineers know which fields matter and which are noise, which dashboards are trustworthy and which are abandoned, that the renewal team uses one definition of "active customer" and that product uses another. None of this is written down.
When the same company tries to give an agent access to that knowledge, the cracks show up fast. We'll use a hypothetical mid-market SaaS company called Riverbend as a recurring example. Riverbend is composite, not a real company, but if you've shipped agents anywhere in the last two years, you'll recognize it.
Riverbend's data falls into four rough categories. The structured stuff sits in Snowflake, DataBricks, Redshift, and BigQuery: hundreds of tables, weekly schema changes, hourly transformation jobs, tribal knowledge about what means what. The documents sit in Notion, wikis, and shared drives: sprawling, inconsistent, and often duplicated. Specs, runbooks, and policies that nobody is sure are still current. The operational systems are Zendesk, Jira, Salesforce, and HubSpot, holding customer history, account state, and open issues. And the conversations, where intent actually lives, are in Slack, Gong, and email. That's where decisions get made and commitments live. The data is all there. It just isn't in a form an agent can use.
The standard playbook for getting agents this knowledge looks clever in principle but is painful in practice: bolt on an MCP server, hand the agent CLIs and APIs to call, and let it loop. The agent retrieves, reads, realizes something's missing, retrieves more, synthesizes, hits a conflict, retrieves again. Repeat. This is brute force, and it's the default because it's the only thing most teams can ship without significant time from their AI, data, or software engineering teams.
The Cost of Brute Force
The brute-force pattern produces a recognizable failure profile. Retrieval can eat 80% or more of an agent's token budget. Task completion rates often sit in the 50 to 60% range. Completion times are unpredictable. Token costs run away.
Mapped to Riverbend, the four failure modes look like this:
| Failure mode | What it looks like at Riverbend |
|---|---|
| Slow responses | A "what's going on with Acme?" query takes minutes of tool calls before the agent has enough context to attempt an answer. |
| Token burn | Raw Salesforce records and Gong transcripts dumped into the context window. Cost scales with confusion, not with task. |
| Incomplete and unreliable | The same question asked twice produces different answers. Cross-document synthesis fails silently. |
| No governance | Permissions aren't respected at retrieval time. There's no audit trail back to source. Compliance has nothing to inspect. |
Each failure has a business consequence. Runaway tokens are cost. Failed tasks are risk. Slow loops are velocity. Lack of governance is risk and compliance exposure.
Web search already made the transition from a ranked list of links to direct answers. Knowledge infrastructure needs the same leap.
How to Tell If Your Agent Has a Knowledge Problem
Engineers shipping agents tend to start by blaming the model. That's almost never where the problem actually lives. Five failure patterns show up over and over in production. Each one has a different root cause and a different fix. If you can name the pattern you're seeing, you can match it to the right approach instead of cycling through model upgrades that don't help.
1. Slow. First responses take minutes instead of seconds. The trace shows long stretches between tool calls, not actual model thinking time.
Root cause: too many retrieval round trips at runtime. Each tool call is a network hop and a re-parse cycle. The agent burns the latency budget assembling context before it can attempt an answer.
What addresses it: pre-compiling the structure agents need so the answer comes back in one or two calls instead of ten.
2. Expensive. Token bills compound fast. The agent pulls back chunks, stuffs them in the context window, decides it needs more, pulls more, stuffs again. Cost scales with confusion.
Root cause: unbounded retrieval depth combined with chunked context that doesn't carry the relations the agent needs.
What addresses it: structured artifacts shaped for the task, plus a query interface that lets the agent declare a budget instead of running until it gives up.
3. Unreliable. Same question, different answer across runs. Cross-document synthesis fails silently. The agent says "no information found" when the information is there, just not co-located in any single chunk.
Root cause: stochastic retrieval over fragmented data. The agent stitches a different subset together each time, which means each run is effectively a different prompt to the model.
What addresses it: deterministic, pre-built artifacts that consolidate cross-document facts at construction time. Same query, same artifact, same answer.
4. Multi-document reasoning fails. Single-document lookups work fine. As soon as the question requires combining facts from multiple sources, the agent loses the thread.
Root cause: chunks don't carry relations. The agent has the pieces but no connective tissue to join them.
What addresses it: artifacts that pre-compile cross-document relationships at build time. The agent receives a coherent object instead of a pile of fragments.
5. Ungoverned. Permissions aren't enforced at retrieval time. There's no audit trail back to source. Compliance has nothing to inspect, security teams can't sign off, and regulated workloads stay blocked from production.
Root cause: governance was bolted onto a retrieval system designed for a different consumer (humans clicking through results), not designed in for agents declaring queries programmatically.
What addresses it: a query interface that enforces permissions at the surface and returns provenance with every field, not as a separate audit pass.
A short self-test:
- Are you seeing more than one of these five patterns in production?
- Has fixing the model (better embeddings, larger context window, switching to a smarter LLM) made the problem better, or just more expensive?
- Would your agent still work if it had to answer five times the queries it answers today?
- Could a compliance auditor trace any answer the agent has produced back to its source data?
If you're seeing more than one pattern, model upgrades haven't stuck, scale is on the horizon, or governance is a sign-off blocker, you have a knowledge problem. The next instinct is usually to upgrade retrieval, which is the wrong fix.
Why This Is a Knowledge Problem, Not a Retrieval Problem
It's tempting to read the failure modes above and conclude that the team needs better retrieval. A vector database, better embedding model, better re-ranking, better chunking. That's not the diagnosis.
Agents aren't failing because retrieval is slightly off. They're failing because they can't express what they need, and the systems they're querying can't serve typed structured requests anyway.
Consider the three things an agent should be able to say but can't:
- Return the answer, not twenty chunks: the agent doesn't want a ranked list of passages it then has to re-parse. It wants a typed answer with the fields the calling code already expects. Without that contract, the agent burns tokens re-parsing every call.
- Cite which source, with confidence: the agent needs to know which fields came from a contract, which came from a Slack message, and how confident the system is in each. Without field-level grounding, the agent can't separate facts from guesses, and the answer can't be governed.
- Standard depth, under 500 milliseconds: the agent needs a budget envelope for cost and latency. Without one, every call runs however deep, however long, and however expensive.
These are language problems. The agent is missing the vocabulary. But even if the vocabulary existed, today's retrieval systems can't serve those requests. They're built to return passages, not typed answers with provenance and budget contracts. That's an engine problem.
A language alone is an aspirational spec. An engine alone is just another retrieval API. You need both.
The architecture is layered. Data sources at the bottom, a database that runs vectors, full-text, and metadata under one consistency model, the knowledge engine itself with two components inside (a context compiler and a composable retriever), a declarative query language above that, and the agents on top. The diagram below shows Pinecone Nexus, the example we'll use for the rest of the article.
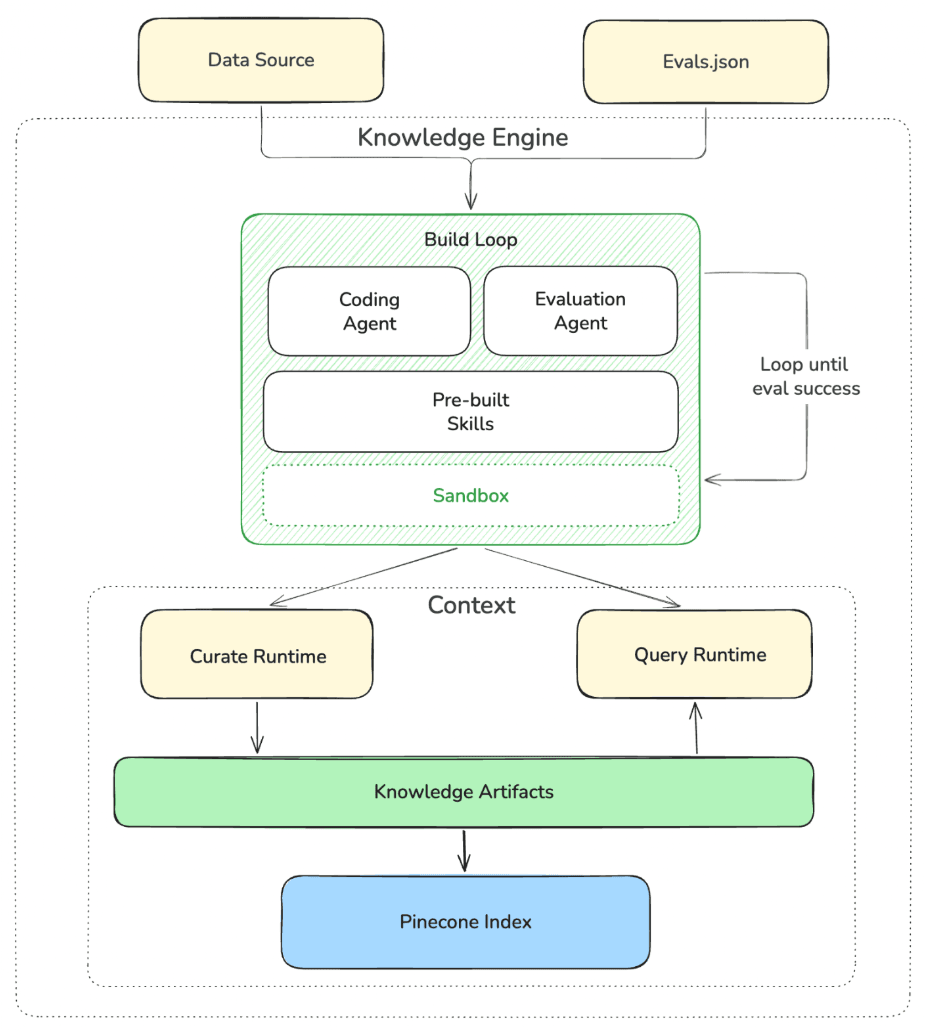
The rest of this article unpacks that summary, layer by layer.
The Four-Layer Hierarchy
A knowledge engine sits at the top of a four-layer composition. Each layer is built from the layer below, and each has its own active verb. Construction happens at the artifact level, where artifacts are built from raw data. Design happens at the context level, where contexts are curated from artifacts. Knowledge emerges from the collective body of contexts. And the engine ties it all together with an agent at its core, building and tuning contexts from the same underlying data.
The definitions:
Artifact. The concrete form of information an AI agent can act on, constructed for a specific task or outcome. Two agents working over the same data require different artifacts to be successful.
At Riverbend: the customer-support bot's BigQuery query guide and the Sales agent's deal-stage map look nothing alike, because each is shaped for one job.
Context. A curated set of related artifacts, designed to serve a specific domain or agent use case (typically a team, role, or workflow).
At Riverbend: Sales has its context, built from deal artifacts, CRM artifacts, and Gong-derived competitive mentions. Customer Success has its own context, built from account health artifacts, ticket history, and product usage signals. RevOps has its own. Each is a deliberate grouping for the agents that team builds and runs.
Knowledge. The collective body of all an organization's contexts, representing the meaning, relationships, and operating logic that emerge across every team, role, and agent.
At Riverbend: knowledge is everything the four agent-teams (Sales, Finance, Marketing, CEO-staff) have curated, taken together. It's the picture of how Riverbend operates, made usable by every agent it deploys.
Knowledge Engine. A new category of data infrastructure purpose-built for the agentic era. It builds any number of contexts from the same underlying data through an agent that constructs and tunes each one to fit how a team actually works.
At Riverbend: one engine, one set of source connections, four contexts, four sets of artifacts compiled from the same underlying data.
What the Artifacts Actually Look Like
Take a single source, like a sales call recording. For a Sales agent, that recording becomes deal context: who pushed back on what, who's the champion, what the timeline looks like. For a Finance agent, the same recording becomes an expansion-signal indicator: hints about budget cycles, contract structure preferences, when to expect renewal motion. For a Marketing agent, it's a competitive-mention extraction. For a CEO-staff agent, it's one signal in a cross-functional roll-up of how the business is moving.
Same source. Different artifacts. Each shaped for the agent's task, not generic retrieval over the recording.
Other shapes show up in real deployments. Entity profiles compiled across hundreds of documents, where Acme Corp shows up as one coherent object instead of 40 scattered mentions. Dependency graphs that capture how modules depend on each other rather than a raw import list. Semantic layers for analytics that hold tables, columns, relationships, anti-patterns, and worked examples instead of dumping a dbt schema. Decision frameworks distilled from policy documents: the rules, not the PDF.
The hierarchy lands an old distinction in a new place. A system of record stores what happened to your data. A knowledge engine compiles that data into something each agent can act on directly, with the artifact shape varying by what each agent is trying to do.
How a Knowledge Engine Compiles Itself
There's a structural distinction underneath everything in this article that's worth naming directly.
Reasoning at retrieval (today's pattern).
Reasoning at compilation (the knowledge-engine pattern).
That shift is what unlocks the rest. Frontier models are freed to do what they were designed for: intelligent reasoning, not managing knowledge.
Compiled-artifact retrieval is not new in concept. The problem has always been labor. Every pipeline is artisanal. Domain schema, chunking, retrieval tuning, eval-driven iteration, ongoing maintenance. Well-funded AI-native teams can afford it. Most teams cannot, so they fall back to naive RAG because it's the only thing they can ship.
Riverbend has eight engineers and shipping deadlines. They can't live the artisanal-retrieval-pipeline lifestyle. They need the engine to do the work an artisan would otherwise do.
The build loop is what that automation looks like in practice. Given source data, a task spec, and an eval set, the loop composes ingestion and retrieval code from a vetted skill library that includes entity extraction, dimensional modeling, symbol-tree generation, and cross-document linking. It scores candidate strategies against a multi-objective function (accuracy, tokens, and latency, jointly), so that no single objective dominates. It diagnoses failures and iterates against the evals until the quality threshold is met. And it commits the winning code as a versioned, inspectable, forkable strategy: code the team can read, modify, and override.
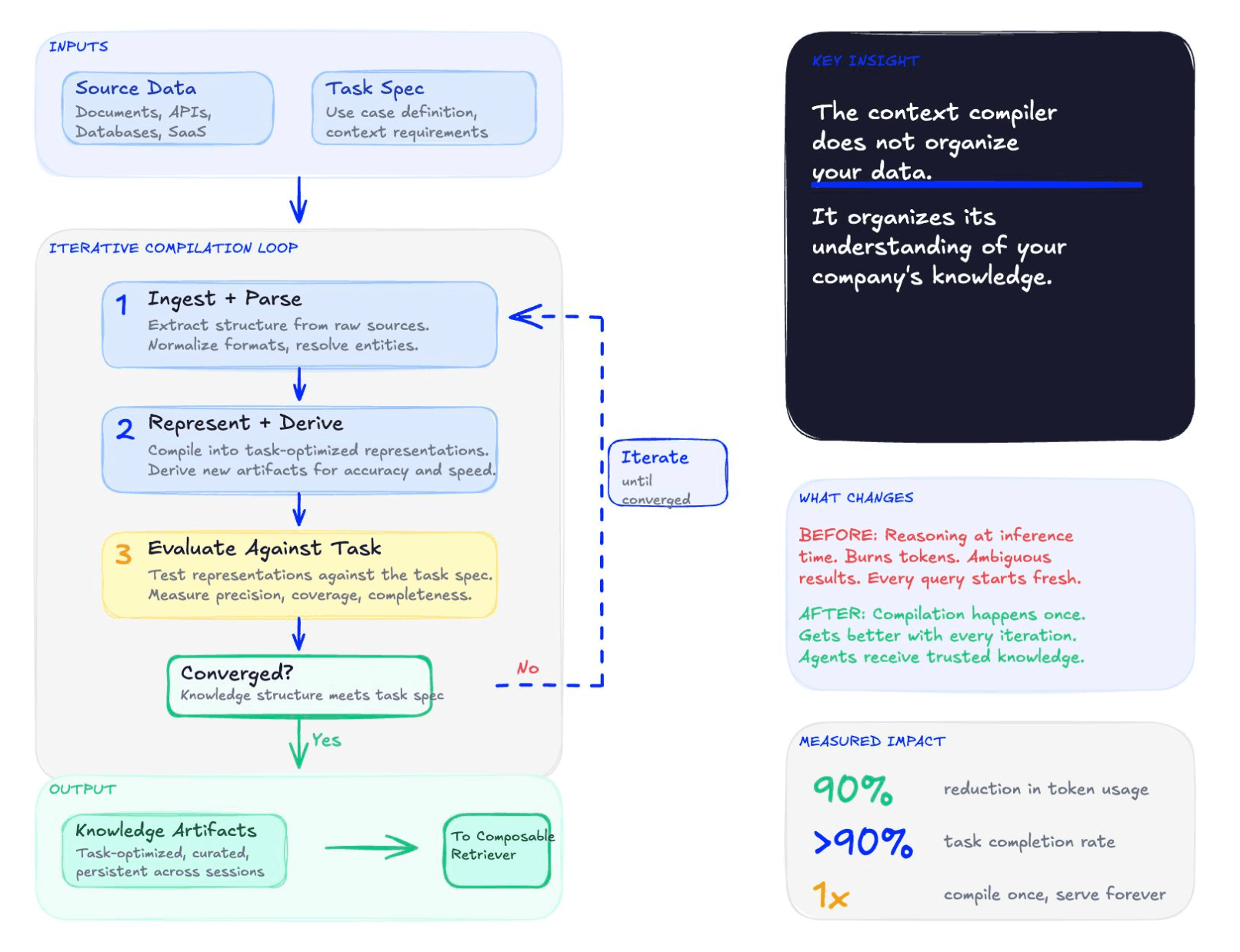
What's not obvious is why this works without compromising on any single objective. The trick is the joint scoring. Artifact shapes that raise accuracy also reduce the re-orientation an agent has to do at query time. Tighter token budgets force sharper representations, and sharper representations tend to be more accurate. Accuracy and efficiency pull in the same direction once the loop is set up correctly.
This is what "compile once, read many" means. The reasoning the model would have spent re-orienting at runtime is reasoning the engine spent once at compile time and serves cheaply thereafter.
Pinecone Nexus doesn't ship a retrieval strategy. It ships a coding agent that writes the retrieval strategy for your task, on your data, against your evals, and rewrites it when either changes.
The practical implication: a team like Riverbend doesn't have to staff a retrieval pipeline. They point the engine at their sources, declare a task spec for each agent, and let the loop produce the artifacts.
How Agents Query: KnowQL
The interface between agents and a knowledge engine is what determines whether the engine pays off in production. If the agent has to issue a paragraph-level natural-language query and parse a blob of text back, the failure modes from earlier all come back. The agent burns time and tokens re-orienting on every call.
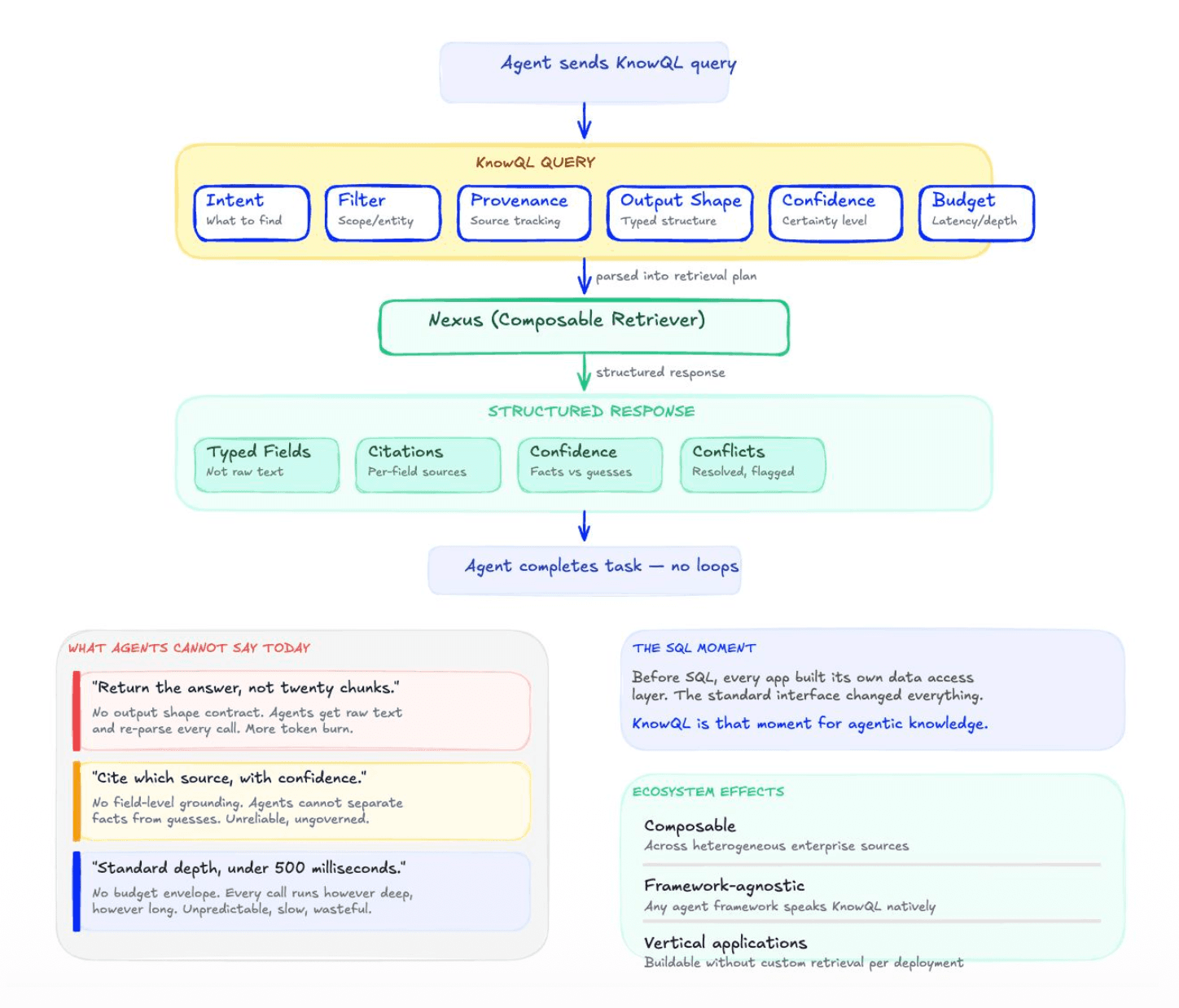
What agents need is an interface where they declare what they want and get a precise, typed, cited response back. That's KnowQL: a typed declarative query language for agentic knowledge retrieval. It composes four categories into a single declarative call:
- Intent: what the agent is asking, what shape it expects the answer in, and which contexts to search across.
- Filter: deterministic predicates and access-control policies enforced at the surface. The agent only sees what its caller is permitted to see.
- Provenance: field-level citations returned by construction, not reconstructed afterward. Every value carries its source.
- Control: a budget envelope. Cost declared in outcomes (depth, latency), not raw tokens.
The structural parallel is SQL and GraphQL. SQL gave relational data a universal interface, and an ecosystem of applications grew on top. GraphQL did the same structural job for connected APIs. KnowQL plays the same role for agentic AI knowledge.
Before and After: A Renewal Question
Riverbend's Sales agent needs to answer a renewal question: does Acme, one of Riverbend's customers, qualify for a renewal discount?
Before, the question goes to a brute-force agent as a natural-language prompt: "Does Acme qualify for a renewal discount based on their contracts, usage, and our pricing policy?" The agent gets ranked chunks back. It parses, synthesizes, re-retrieves what's missing, parses again. Multi-turn loop. Tokens scale with confusion.
After, the same question is a single KnowQL query:
{
"ask": "Does Acme qualify for a renewal discount?",
"shape": {
"qualifies": "bool",
"discount_pct": "number",
"applicable_rules": ["..."]
},
"ground": true
}A structured, cited answer. One call. The calling code expects a typed object and gets a typed object, or a typed null if the evidence is too weak, with the reason attached. The full primitive surface (scope, where, ground with per-field options, budget) is in the table above.
SQL for databases. GraphQL for APIs. KnowQL for agent knowledge.
For the database underneath KnowQL (and what makes serving structured knowledge at agent QPS practical), see the Slab Architecture deep-dive.
How Agent Retrieval Approaches Compare
Most teams shipping agents end up evaluating a small set of well-known retrieval patterns. Each one solves part of the problem and breaks somewhere else. Here are the seven you're most likely to weigh, what they do mechanically, and where each one fits.
| Approach | Mechanic | When it works / when it fails |
|---|---|---|
| Vanilla RAG | Embed chunks of source documents into a vector index, retrieve top-k by semantic similarity, stuff into context | Works for short single-document lookups against well-formatted text. Fails on multi-fact or multi-document reasoning, anything requiring structured output, anything requiring the agent to chain retrieval with logic. |
| Agentic RAG | Decompose the query, retrieve per sub-question, evaluate, retry until the agent decides it has enough | Handles richer queries than vanilla RAG. Expensive in tokens and time. Fails when the facts the agent needs aren't co-located in any chunk. |
| Coding agent in a sandbox | Give the agent file-system tools (list, read, grep) and let it navigate source files directly | Works for small corpora and deterministic file structures. Fails when the corpus exceeds the context budget. Very high token cost on anything non-trivial. |
| MCP + tool calling | Expose each data source as a tool and let the agent compose calls | Useful for prototypes and bounded surfaces. Fails as the tool count grows because there's no shared interface across tools, no shared retrieval vocabulary. |
| Knowledge graph | Manually curated entities and relations, queried with a graph language | Works when the ontology is stable and the curation team can keep up. Fails when data shifts faster than the curation can. Which is usually. |
| Semantic layer (BI/dbt-style) | Runtime joins over warehouse data, defined in a metric layer | Works for analytical queries to humans through a BI tool. Fails for agentic workloads that need structured outputs and field-level provenance, not aggregated rollups. |
| Knowledge engine | Compile data into task-specific artifacts at build time. Serve them through a declarative query language | Crosses domains via a single pattern, deterministic, auditable. Requires a build loop, an eval set per domain, and a skill library for the compiler to draw from. |
These patterns aren't strictly competing. Most production agent systems combine several of them. Vanilla RAG is fine for a single FAQ corpus. An agentic RAG loop can handle some richer questions. An MCP server can expose source-of-truth data the agent occasionally needs to read directly. The question isn't "which one is best?" but "which one is the right primary pattern for the workload?"
For agent workloads where the same questions get asked repeatedly, where multi-document reasoning is the norm, where governance is non-negotiable, and where the cost of the agent has to forecast like a budget rather than a meter, the patterns that derive structure per query (RAG, coding agent, MCP) all share the same underlying problem: they push the orientation work to runtime, where it's slow, expensive, and brittle.
Knowledge graphs and semantic layers got the right instinct decades ago: pre-shape data into structures that downstream consumers can read directly. They struggled with the operational reality of keeping the curation current as data shifted underneath. A knowledge engine takes the same instinct and replaces the manual curation with an autonomous build loop, which is what makes it operationally viable across the dozens of domains a real company runs on.
What a Knowledge Engine Is Not
A new category gets compared to whatever's nearest. Knowledge engines get compared to a lot of things they're not. Here are seven distinctions worth holding in your head.
Not a vector database. A vector database sits underneath a knowledge engine. It's one of several stores the engine uses to compile and retrieve structured artifacts. The engine is the compiler and the query surface; the vector database is one of the storage primitives.
Not just RAG. A knowledge engine uses RAG as one of several techniques in its retrieval layer, alongside structured lookup, entity resolution, and cross-document composition. The compile step, the typed query interface, and field-level provenance sit on top of that. Vanilla RAG returns ranked passages. A knowledge engine returns the answer.
Not an agentic memory layer. A memory layer records what an agent has done. Past sessions, prior conversations, things it has seen before. A knowledge engine is the source of truth for what the agent needs to know about your business: contracts, policies, code, processes, customer state. Memory is the scratchpad. Knowledge is the substrate.
Not a knowledge management platform. Knowledge management platforms are built for humans browsing, searching, maintaining a taxonomy. A knowledge engine has none of that, because the consumer is never a human. It's infrastructure for agents to declare what they need and get back a structured, cited answer in one call.
Not enterprise search. Enterprise search returns documents to read; the user does the synthesis. A knowledge engine returns structured cited answers the agent can act on directly, no intermediate document-reading required.
Not a context engine. Context engines fetch and assemble at runtime: an agent asks, the engine pulls from sources it doesn't compile or own, hands back a bundle. The same work runs again on the next query. A knowledge engine moves that work to build time. The artifacts get compiled once and served thereafter, which makes the runtime fast, cheap, and predictable.
Not a semantic layer. BI-style semantic layers (the dbt and metrics-layer category) compose runtime joins over warehouse data so analysts can ask consistent questions through a BI tool. They serve humans asking analytical questions. A knowledge engine compiles task-specific artifacts at build time so agents can ask precise structured questions and get typed answers back. The instinct is the same (pre-shape data for the consumer), but the consumer, the output shape, and the runtime model are all different.
Make AI Knowledgeable
The model era is commoditizing. Prices are dropping; capabilities are converging. Choosing one frontier model over another rarely changes a company's competitive position for long.
The knowledge layer and the interface to it are where competitive position will be won or lost. Where the data comes from, how it gets compiled, how agents ask for it. That's the work a knowledge engine does, and it's the layer worth investing in if you're betting on agents in production.
Our mission is to make AI knowledgeable. If you're betting on agents in production, request Early Access to Pinecone Nexus.
Was this article helpful?




