Anyone building agents in production today has run into the same wall. The model itself is rarely the limiting factor as frontier models are capable of the reasoning most jobs require. What breaks is everything before the reasoning step. The agent gets a task, decides it needs information, searches, retrieves, evaluates results, decides it needs more, searches again, reads, fragments together a partial picture, and loops. By the time the model is in a position to produce an answer, most of the token and latency budget is already gone.
This is the gap that defines agent infrastructure right now. The discipline that's emerged around this problem is context engineering: shaping data into knowledge the model can use, instead of asking the agent to reassemble it from raw data at query time.
Operationalizing these context pipelines is where teams get stuck, especially across a real company where the context needed for every domain (sales, legal, finance, support, R&D, ops) is shaped differently. Hand-building one context layer per domain doesn't scale past the first one or two.
We spent the last year working on this. The rest of this post is about why it's hard, what we built, and what we think comes next.
A concrete example: the market-intelligence agent
Let’s consider a market-intelligence agent at an investment firm looking over S&P 500 10-K filings. This question is an example of dozens the agent needs to answer:
For this agent to ship to production, the context layer needs to clear four requirements:
- Accuracy: Right answers, repeatable across runs. A flaky agent that's correct 70% of the time is non-functional in practice.
- Task latency: Query budgets in seconds, not tens of seconds or minutes.
- Token cost: Per-call cost is bounded; agent bills don't compound across the workflow.
- Governance: Field-level permission enforcement and grounded provenance so that answers can be traced back to their source.
However, satisfying all four simultaneously is harder than it sounds. When a team sets out to build a context layer for an agent workload like this, they typically dedicate a team and months of iteration to one of two patterns:
- Agentic RAG: Chunk the 10-K corpus, embed the chunks, and use hybrid retrieval. Let the agent loop: run the query, rerank, read the top chunks, and loop until it’s satisfied with the answer.
- Coding Agent in a sandbox: Give the agent access to file-list, page-read, grep, and full-doc-read tools and let it loop. It opens each 10-K, navigates to the capital returns section, parses the table and extracts the answer.
While both approaches may eventually get the right answer, it’s often far too slow and expensive to put into production. Both suffer from the same underlying challenge: they make the agent assemble knowledge for each task at query time. Agentic RAG hands the agent chunks and asks it to stitch the answer together. Agentic Sandbox hands the agent files and asks it to navigate to the answer through search, grep, and parsing. In these approaches, the vast majority of the work is spent retrieving raw data and assembling the right context instead of reasoning.
From Hand-Engineered Context to Compiled Knowledge
The solution for problems like this is well-known: don't make the consumer derive structure per query. Pre-shape the data into artifacts that already encode the structure consumers care about, and serve those.
This isn't new. Knowledge graphs, entity catalogs, and semantic layers have existed for decades. Every generation of data infrastructure has shipped some version of the same instinct: do the orientation work once, store the result, let downstream consumers read it directly. Context engineering is the latest version of that instinct, now applied to agents instead of dashboards.
Where it breaks: operationalizing per domain
What's hard though isn't the concept. It's operationalizing it.
Building a good artifact layer for one domain takes a sophisticated team and months of iteration, deciding which specific curation strategy, retrieval design, evaluation harness, and governance hooks to use. The complication is that a real company doesn't have one domain. It has dozens (e.g. sales, customer support, legal, finance, R&D) each with its own data shapes, schemas, dialects, and access patterns.
Multiply months-of-iteration by every domain that wants an agent and you’ll quickly run out of resources building these pipelines. In practice, what ends up happening is that the layer gets built for the one or two highest-value domains at most, or it doesn't get built at all.
This is the problem in the agentic era where every domain in a company will run agents and every agent needs context engineered to ship.
A new category of knowledge infrastructure
This problem points to the need for a new category of knowledge infrastructure: one where the context layer operates as infrastructure, automatic across domains, rather than hand-tuned and constructed per domain. The layer exists, you provision against it, you don't rebuild it from scratch every time you have a new use case.
We've spent the last year building one. It’s called Pinecone Nexus, a purpose-built Knowledge Engine for agents.
Inside a Knowledge Engine
A Knowledge Engine is built from four primitives, each a composition of the one below:
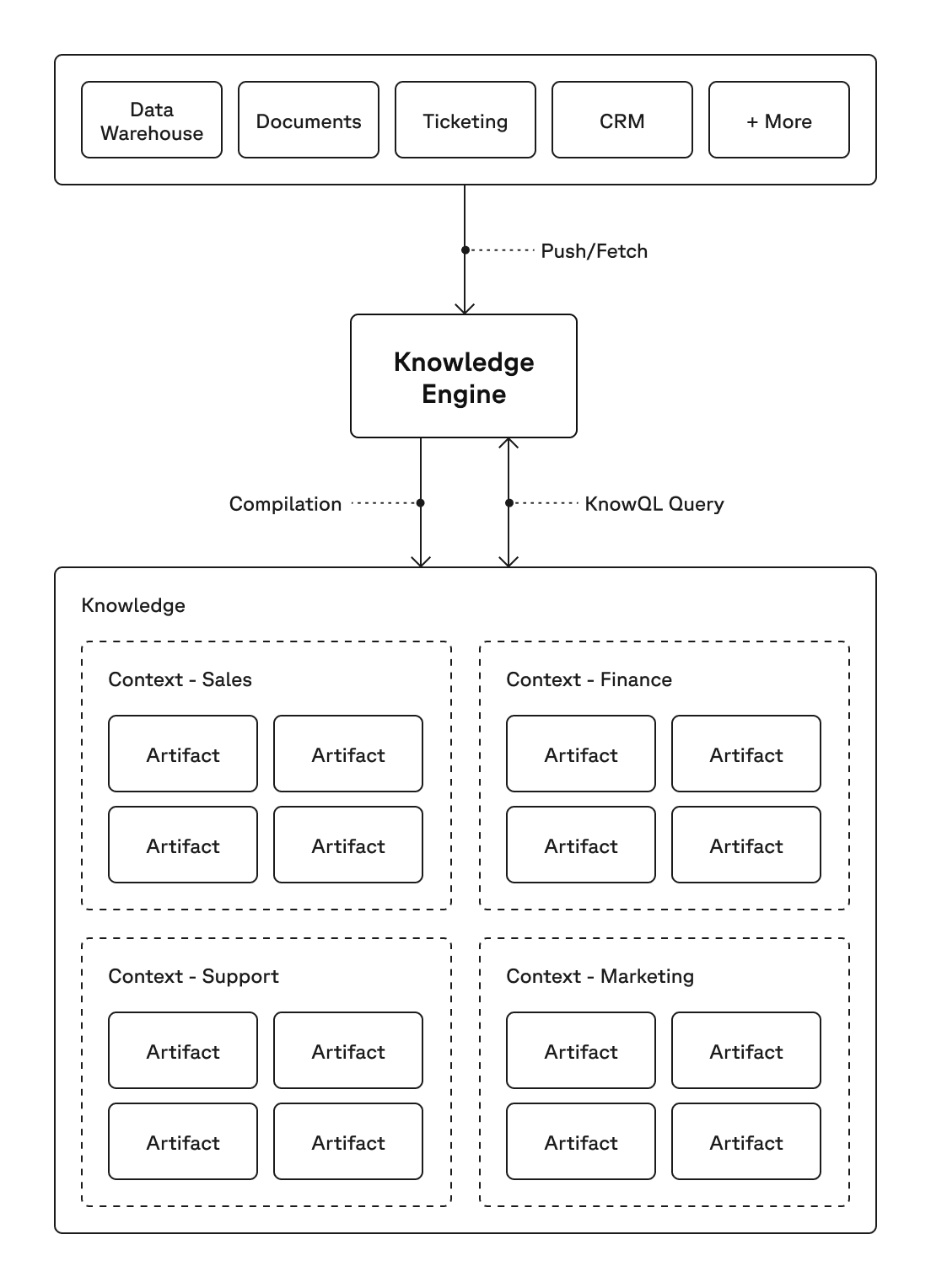
Artifact: A typed, governed piece of information constructed for a specific task or outcome. From the same 10-K data, a market-intelligence agent that wants financial metrics (e.g. revenue, capital gains) will get a different artifact than a compliance agent that wants risk-factor disclosures. Each shape is what makes the underlying representation efficient and tuned for each agent's job.
Context: A curated set of artifacts designed for a specific role, team, or workflow. We bundle the analyst's financial-metric artifacts together with the narrative sections their agent needs (MD&A, segment reporting), and that bundle is the analyst's context. The compliance team has its own.
Knowledge. The collective body of every context across the company, representing how the business is run across analyst, compliance, M&A, portfolio monitoring, and so on. A query against Knowledge can span as many contexts as it needs; the engine handles the routing.
Knowledge Engine. The system that builds and serves all of the above. The core of this is the Context Compiler, an autonomous coding agent that writes and tunes the curation and query code for each domain. Once the build loop completes, it constructs artifacts from raw data, composes them into contexts, and serves each agent's KnowQL query.
This is an example company-level artifact compiled using the 10k-SEC filings for the market-intelligence agent.
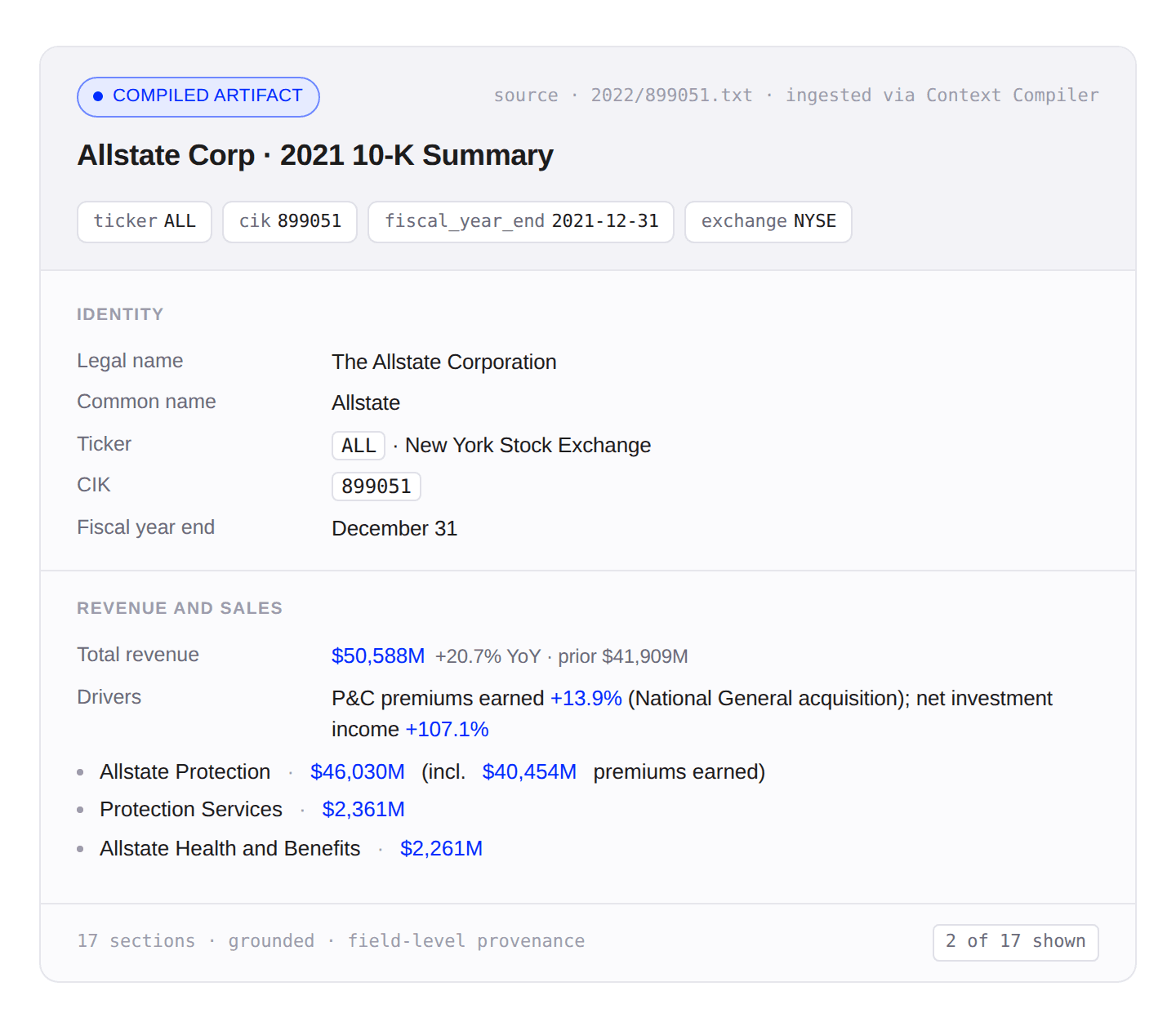
The Context Compiler
The Context Compiler is the autonomous coding agent at the core of the Knowledge Engine. It uses an agentic harness pattern to construct task-optimized Contexts by pairing a coding agent with three things:
- An eval set you define per domain (representative tasks with known right answers) with corresponding data sources
- A library of pre-vetted skills (e.g. document processing, entity extraction, chunking) the agent can compose into solutions.
- A feedback loop that scores each iteration against the eval signal.
With every iteration, the coding agent modifies two functions, curate() for artifact construction and query() for knowledge retrieval, runs the eval set, uses the failure signal to refine the code, and repeats until the evals pass. The output is a working, tuned Context for that domain.
With this approach, any domain expert (even without a retrieval background) can produce an agent-optimized Context since they don’t need to specify schemas, retrieval logic, or artifact shapes upfront. The Context Compiler automatically discovers the right artifact structure, granularity, and construction strategy based on the evals. Most new domains are served by recombining existing skills in new ways; when something genuinely doesn't fit, we add a new skill to the library.
In our work with early design partners, the compiler delivered Contexts for new domains in days rather than months. While we're still measuring across more domains and edge cases, the early signal has been promising and we believe this harness-based agentic approach is the foundation for the future of knowledge infrastructure.
KnowQL
Once the Context is created, the next step is ensuring the agent can use it effectively. If the agent has to issue a paragraph-level natural-language query and parse a blob of text back, the earlier failures come right back as the agent burns time and tokens re-orienting on every call. We wanted an interface where the agent declares what it needs and gets a precise, typed, cited response back. That's KnowQL (Knowledge Query Language).
The "declarative" part is the core design principle. In SQL, you describe what you want (ex. joins, filters, projections) and the engine picks the execution plan. KnowQL is the same idea applied to agentic knowledge retrieval: the agent specifies what answer it needs, in what shape, with what constraints. The Knowledge Engine decides which Contexts to search, which artifacts to read, and how to compose them.
A KnowQL query is a composition of four categories to ensure it meets the production requirements for agents:
- Intent: The question, the response shape, and the Contexts in scope. Note that this can be composed across multiple Contexts.
- Filter: Deterministic predicates and access-control policies enforced at the surface. The agent only sees what its caller is permitted to see.
- Provenance: Field-level citations returned by construction, not reconstructed after. Every value carries its source.
- Control: A budget envelope (depth and latency target). Cost declared in outcomes, not tokens.
For the earlier S&P 10-K question, the KnowQL query the agent issues looks like this:
{
"ask": "Among NVIDIA, Microsoft, and Walmart, compare fiscal 2022 share repurchases: amount repurchased, original program size, and remaining authorization.",
"ground": true,
"shape": {
"type": "object",
"properties": {
"companies": {
"type": "array",
"items": {
"type": "object",
"properties": {
"company_name": { "type": "string" },
"repurchased_usd_millions": { "type": "number" },
"program_size_usd_millions": { "type": "number" },
"remaining_usd_millions": { "type": "number" }
}
}
}
}
}
The Engine returns one typed response, and the agent's only reasoning step is comparing the typed response object as all the orientation work was done at build time.
Measuring the Impact of Knowledge Retrieval
To prove the value of Nexus, we needed to quantify the impact knowledge retrieval has on agent performance. Most existing retrieval benchmarks only measure recall in isolation and don't compare the impact of different retrieval strategies against the end-to-end multi-step agent loop.
We created KRAFTBench (Knowledge Retrieval Assessment Framework for Text) to address this gap. This harness measures the accuracy, latency, and token cost of responses generated from a consistent composer model () across different retrieval mechanisms. This way any difference in quality, latency, or token cost of the agent task is attributable to retrieval. The three retrieval mechanisms tested were:
- Coding agent: Provide with a small read-only file system toolkit (, , , ). No index provided.
- Agentic RAG: Chunk and embed files into a Pinecone vector index. Uses query expansion, RRF fusion, top-k retrieval, and loops until it determines completion.
- Pinecone Nexus: Artifacts generated using Context Compiler. Per-question shape derived by Claude, formatted as a KnowQL query and requests, optional follow-ups for multi-step questions.
The agents were tested against 493 free-form text 10-K filings (~500KB each, ~245MB total) from S&P 500 companies' 2022 SEC filings. Each agent was tasked to answer 150 hard questions spanning 9 sectors and 10 financial topics (headcount, revenue, capex, capital returns, R&D, acquisitions, segment breakdowns, etc.), tagged across three difficulty shapes: multi-fact (combine ≥2 facts about one entity), multi-company (compare across ≥2 entities), multi-step (retrieve fact A, then derive fact B from it).
Each question is given a constraint of 120 seconds and 1M tokens and each agent iterates until it can answer conclusively or exceeds the constraint. The final answer is then graded for accuracy by an LLM judge () against the eval-set's ground truth output.
Our Findings
To compare the three approaches, we plotted each agent's average latency (x-axis) against average accuracy (y-axis), with bubble size encoding completion rate. The goal is the top-left: fast and accurate. Nexus delivered the highest accuracy, completion rate, at the lowest latency and at a significantly lower token cost (~7x vs. RAG, ~80x vs. Coding Agent). Agentic RAG completes nearly every question but at lower accuracy and ~1.7× the latency. The Coding agent is the slowest and least reliable: moderate accuracy, ~4× the latency, and only 63% of questions completed before hitting a token-budget or wall-clock cap.
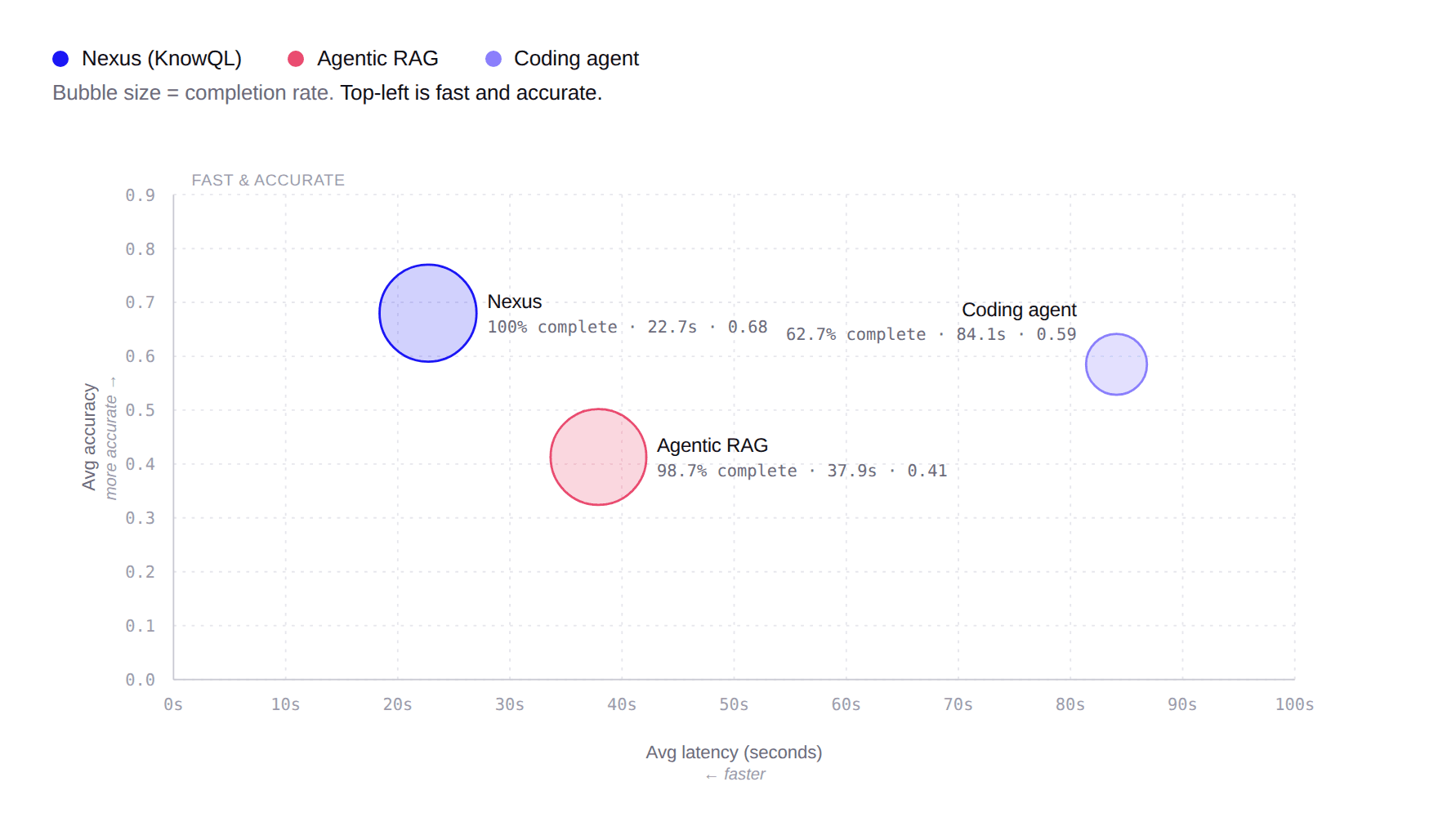
| Completion | Latency (avg) | Accuracy (avg) | Tokens (avg) | Steps (avg) | |
|---|---|---|---|---|---|
| Pinecone Nexus | 100% (150/150) | 22.7s | 0.680 | 6,733 | 1.69 |
| Agentic RAG | 98.7% (148/150) | 37.9s | 0.413 | 49,103 | 7.77 |
| Coding agent | 62.7% (94/150) | 84.1s | 0.585 | 528,301 | 14.77 |
The most challenging questions required multi-company comparisons or multi-step reasoning chains, and the failure mode for each agent shows up clearly in the traces:
- Pinecone Nexus compiled company-level “fact sheet” artifacts making multi-entity comparisons and multi-hop reasoning easier. It finds the relevant set of artifacts and composes the answer in one pass.
- Agentic RAG decomposes each question into multiple requests but each request either misses or returns partial information when only searching by semantic similarity.
- Coding Agent uses grep to identify the keywords in the text but phrases can appear multiple times in each document and there’s no way to determine which mention is the right one. It ends up spending most of its tokens trying to disambiguate until it runs out of budget or time.
To demonstrate this more concretely, let’s trace the path of the original question we asked the finance agent:
Coding agent: The coding agent starts with a broad regex sweep looking at “share repurchase” or “Microsoft” or “Walmart” that returns hundreds of matches across all 10-Ks in the corpus. Refining that further by entity name returns more matches and quickly fills up the context window and ultimately hits the 1M token limit.
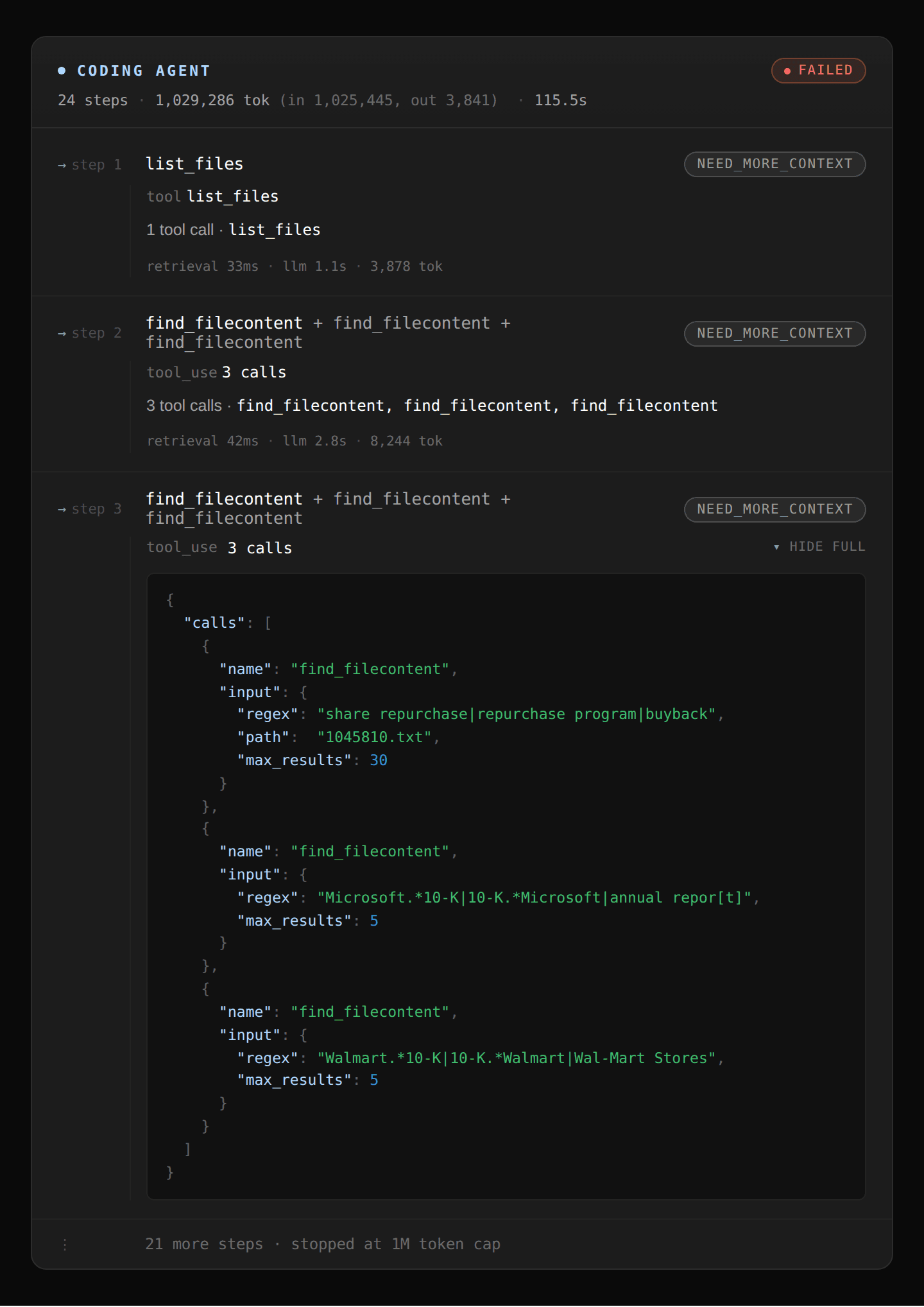
Agentic RAG: The agent first decomposes the query into 18 facts to find and evaluates the top k chunks returned for each fact. However, it failed to find the dollar amounts for Microsoft and Walmart since the dollar figure and chunks were not colocated in the document and incorrectly marked those figures as missing even though the data does exist.
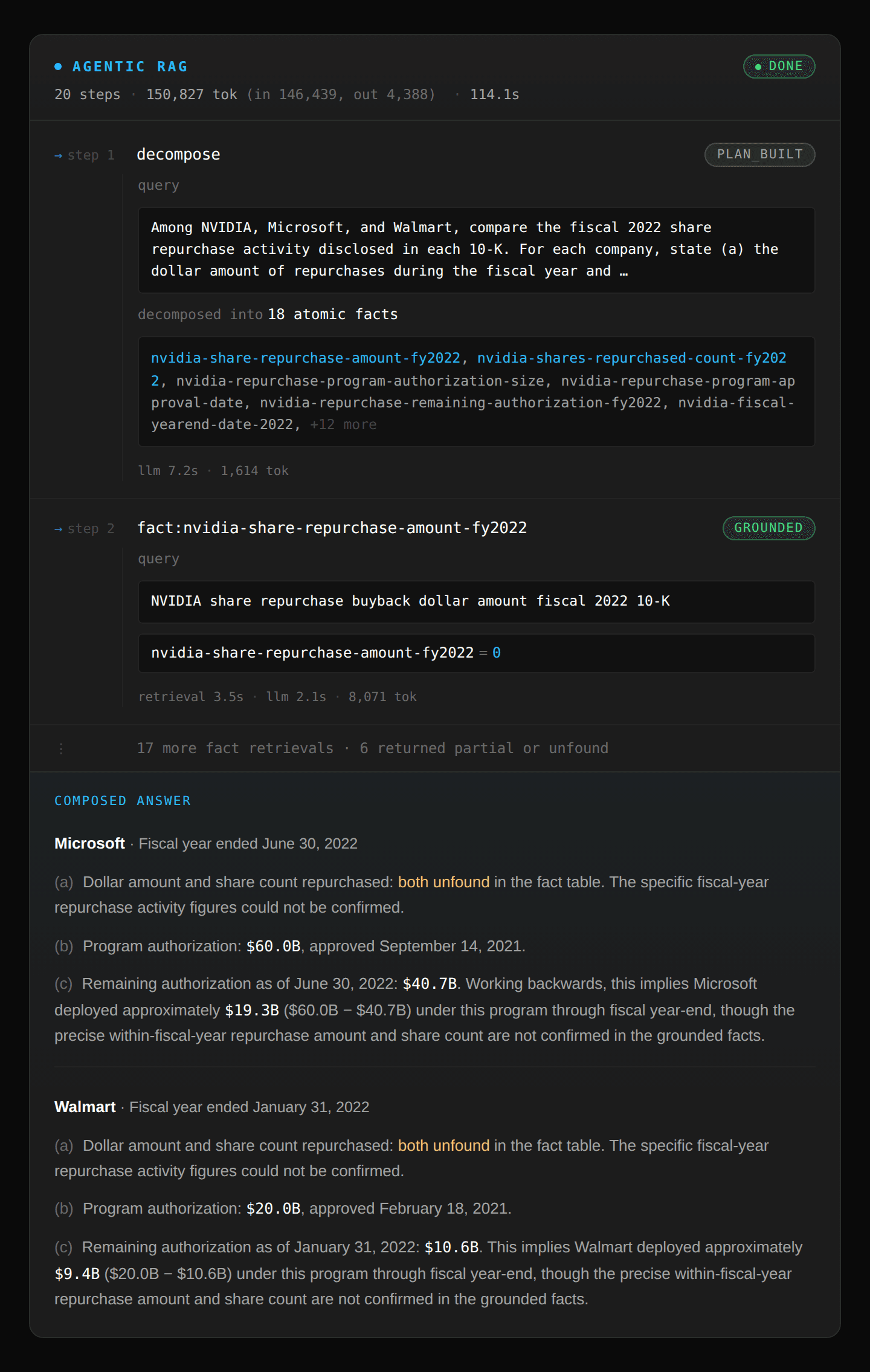
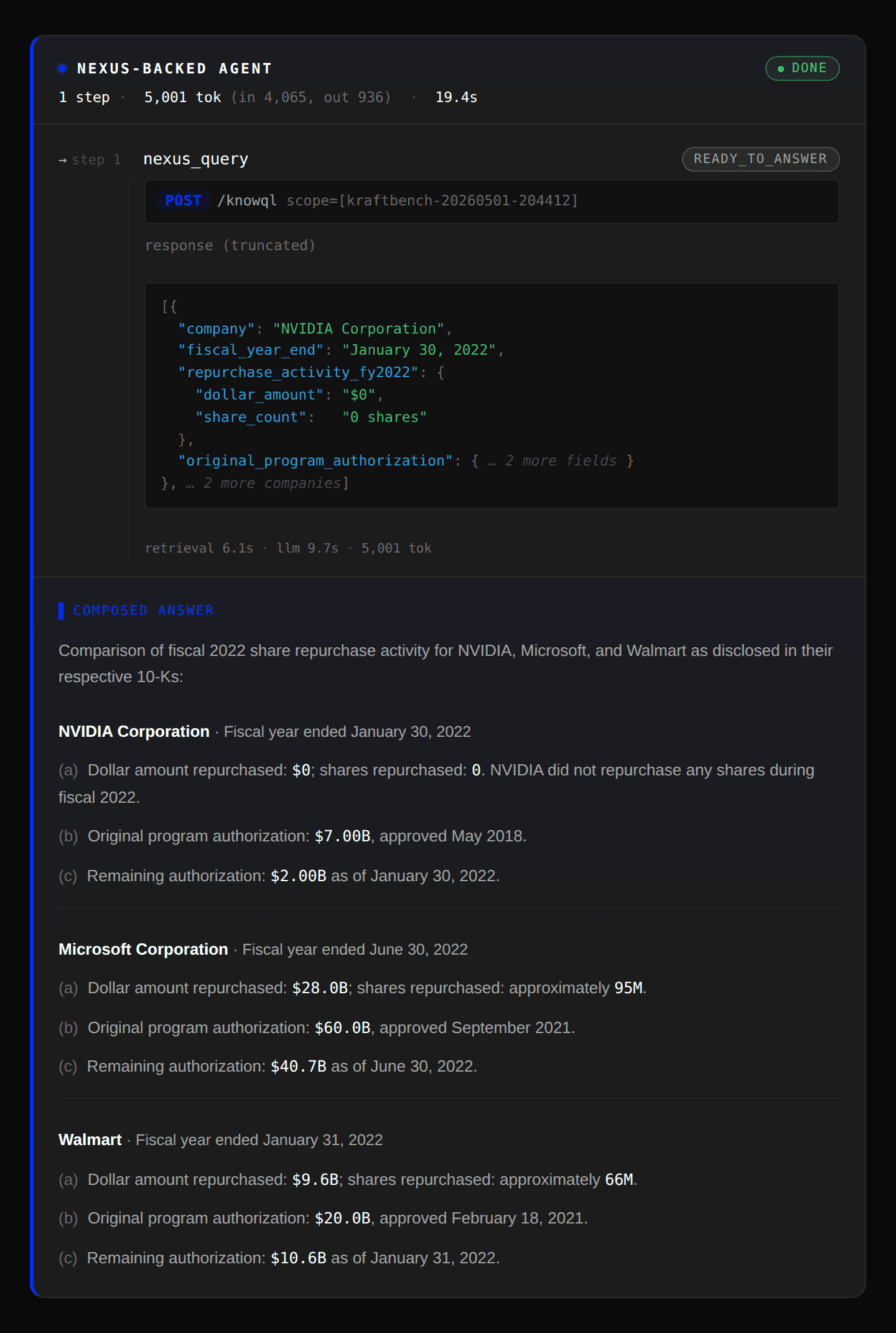
Pinecone Nexus: Takes the full question and a desired structured output shape and completes it in one shot because Nexus generated artifacts summarizing key statistics for each company. It also provided the structured output response as a JSON object to minimize token usage.
In the coming weeks, we’ll publish a deep dive on KRAFTBench to provide a closer look at this methodology and results. If you’re interested in collaborating on this benchmark, please reach out to us.
From Source to Knowledge: Box → Unstructured → Pinecone Nexus
To use Nexus with real enterprise data, we've integrated with two ecosystem partners that own important parts of that stack: Box, where the source documents and their permissions are kept; and Unstructured, which normalizes the raw formats (PDFs, Word docs) into structured formats Nexus can consume directly.
Let’s take the example of a legal review agent looking over a set of CUAD dataset contracts stored in Box that wants to ask the following question:
Box (source): Contracts live in a designated Box folder (e.g. non-competes, commercial contracts, endorsements) with file metadata including access control lists to ensure permissions are respected. The legal team is responsible for maintaining and updating the contract files as needed.
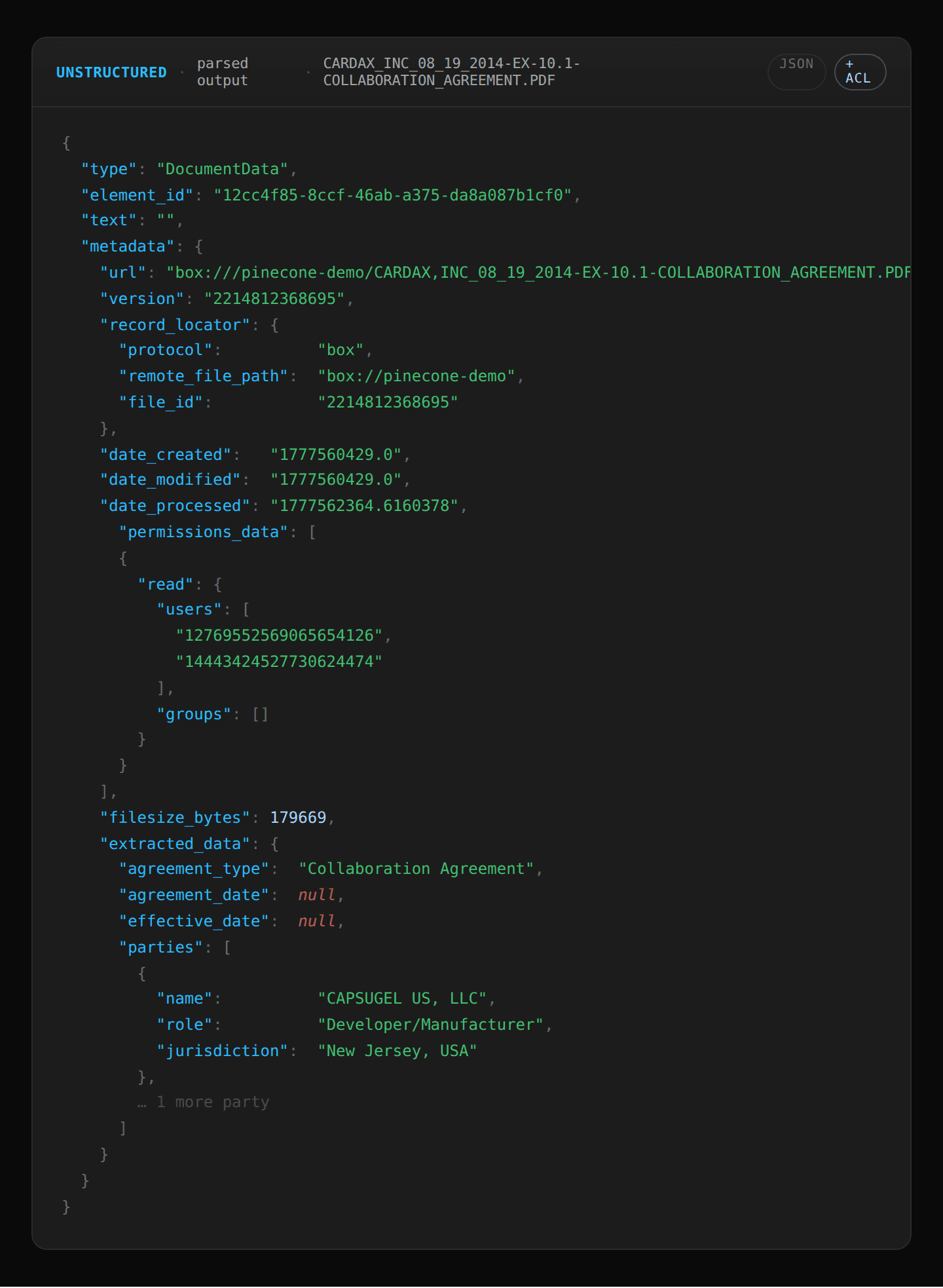
Unstructured (parsing): Unstructured connects through Box's APIs and captures each file’s content and file metadata (including ACLs). It extracts key document elements, tables, and entities from the legal contracts (, ) and passes file permission metadata () to ensure users can only see the contracts they have access to.
Pinecone Nexus (Knowledge Engine): The Unstructured parsed output is ingested as a source and the Context Compiler runs against the extracted data. One of the artifacts it produces is a table aggregating contract renewal terms across different contracts which allows Nexus to answer the question by fetching a single artifact rather than searching across multiple entities. When composing the query, it passes the file permission metadata as a filter to ensure that it only responds with contracts users have access to.
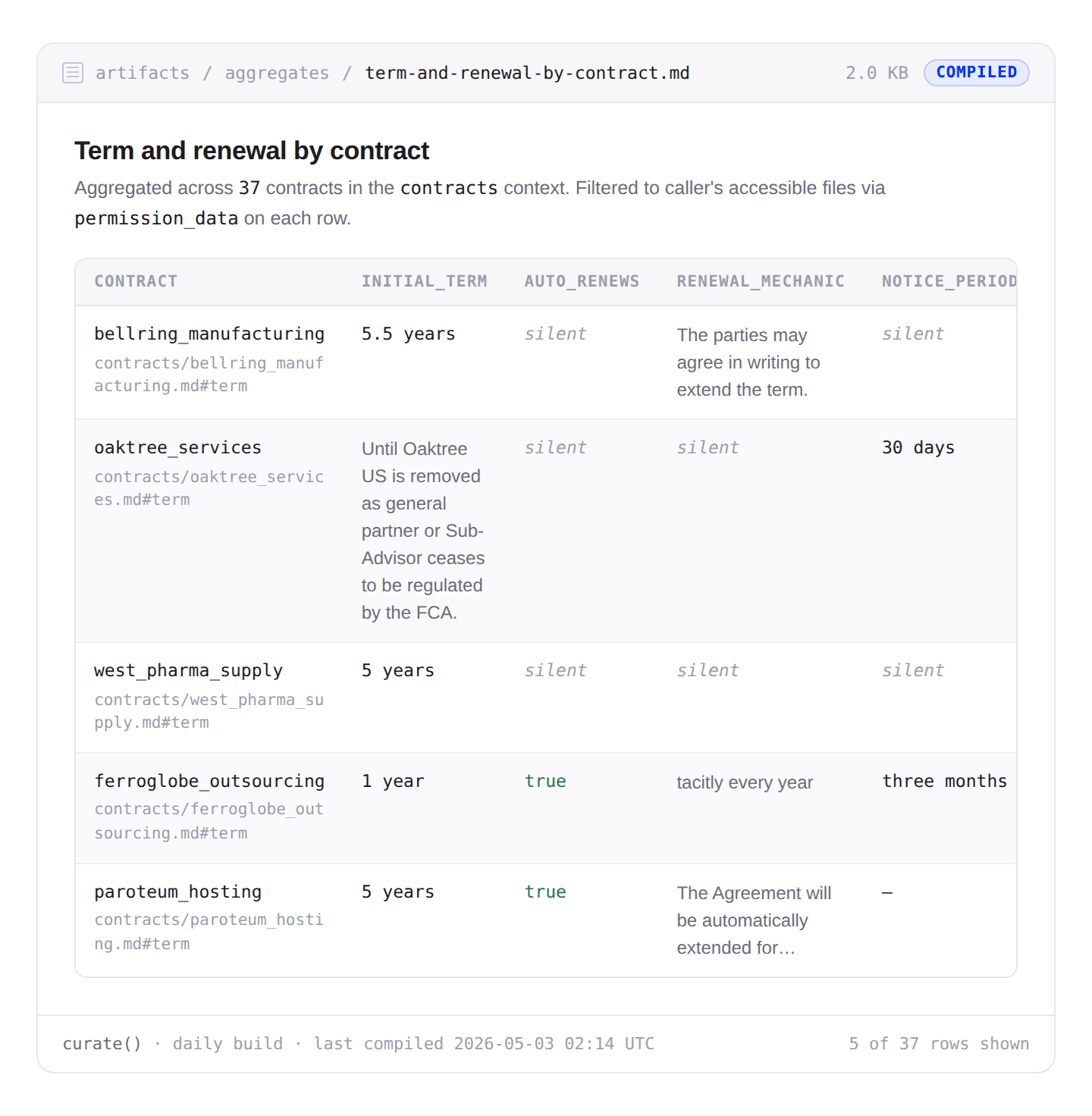
This simple example demonstrates how Nexus composes with existing data pipelines: Box owns the source-of-truth and the file permissions; Unstructured owns the parsing and extraction; Nexus owns the artifact layer and the query surface. The same contract Context can serve a contract-review agent for legal-ops, a renewal-risk agent for sales, and a compliance agent for the GC's office, all built from the same source content in Box.
A New Category, Not a Better Pipeline
We opened this post with the gap between capable models and the infrastructure supporting them: most of an agent's effort goes into orientation, not reasoning. That gap is what determines whether agents ship at scale, and it requires a new category of infrastructure to close.
That category is the Knowledge Engine. We're heading into a future where every domain in a company runs on agents and every one of those agents needs context engineered for it. Hand-building one context layer per domain doesn't scale and the only way to keep pace with that demand is for the infrastructure itself to be agentic. Nexus is our expression of that vision: an autonomous Context Compiler running on the retrieval substrate Pinecone has spent years building, co-designed for the accuracy, latency, and cost agents require.
We launched Pinecone with a singular mission: make AI knowledgeable. With Nexus, that mission gets concrete: every agent in your company, on every team, working from Knowledge compiled for it.
Pinecone Nexus Early Access
Nexus is available in early access today for a limited number of design partners. If you're interested in working with us to co-design the knowledge engine powering the next wave of agents, come apply for the Nexus Early Access.
Was this article helpful?