An (Opinionated) Checklist to Choose a Vector Database
We previously discussed why Retrieval Augmented Generation(RAG) is the most cost-effective and scalable option to address AI hallucination. And there is no RAG without vector databases.
Years ago, Edo Liberty, Pinecone’s founder and CEO, saw the tremendous power of combining AI models with vector search and launched Pinecone, creating the vector database (DB) category. In November 2022, the release of ChatGPT ushered in unprecedented interest in AI and a flurry of new vector DBs.
If your company has decided to fully embrace Generative AI and plans to use a vector database, the number of options out there can be daunting. Choosing a vector database is no simple feat, and we want to help. Being associated with Pinecone, this article will be a bit biased with Pinecone-only examples. But our criteria - from working with more than 4,000 engineering teams including large Fortune 500 enterprises and high-growth startups with 10B+ vector embeddings - apply to the broad industry.
You might just get started with building a small AI application, but think big. AI is estimated to deliver trillions of dollars across many use cases including customer operations, marketing and sales, software engineering, and R&D. In the near future, AI will be in the veins of all parts of your business. This means the scalability of a vector database is crucial for sustainable success because it will support all the AI use cases you will be developing.
To make a holistic evaluation, review these three categories: technology, developer experience, and enterprise readiness. Let’s take a closer look at each category and see what questions you need to ask for better decision-making.
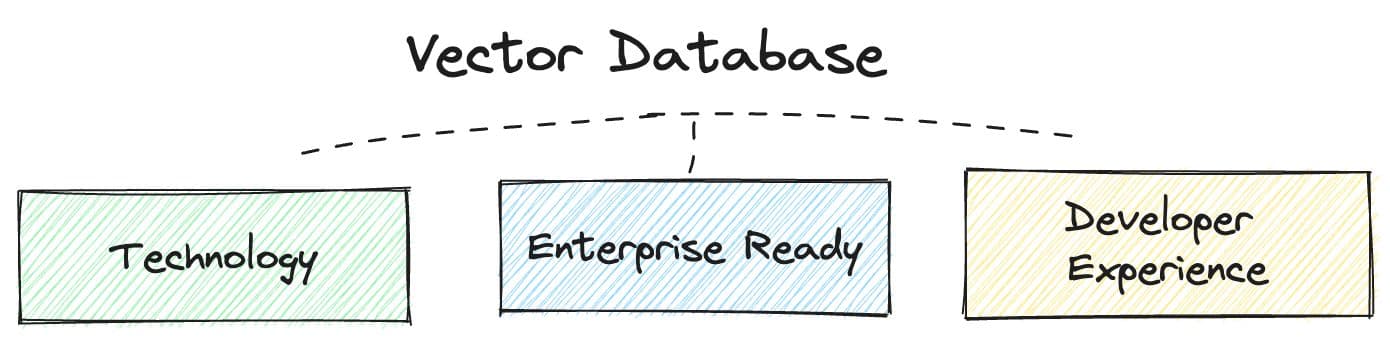
Technology
The technology at the core of any vector DB will affect its performance, scale, and cost.
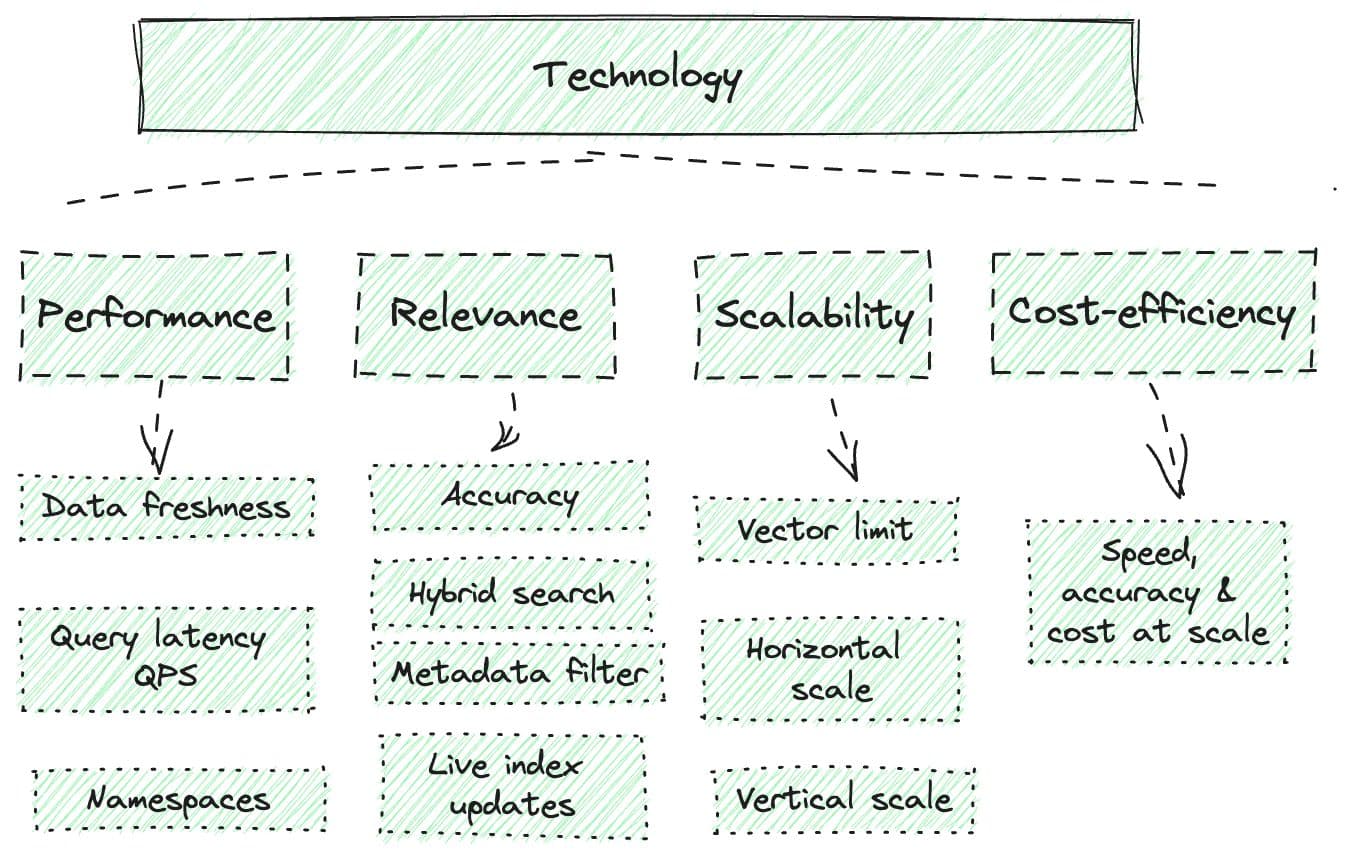
Performance
- Data freshness: How long does it take for you to query the new data? Your business could suffer if the data is not fresh. For example, if the new product information on e-commerce platforms doesn’t get updated in time, it will impact sales.
- Query latency & query per second (QPS): How much time does it take to execute a query and receive the result? How many queries can the system process in one second? Those are very important if you want to build real-time applications like chatbots that delight customers.
- Namespaces: Namespaces are a way to segment data into distinct areas within your index. The intent is to have the ability for an index to serve multiple purposes. Searching by namespace allows you to search over a subset of data versus an entire dataset to reduce query latency. They also reduce the need for additional indexes by isolating segments of vectors within an index. Having namespaces help improve query performance and lower cost.
Relevance
- Accuracy: A vector DB uses a combination of different algorithms that all participate in the Approximate Nearest Neighbor (ANN) search, which allows it to search for the nearest item. Since vector DBs provide approximate results, there can be tradeoffs between accuracy and speed. However, a good system can provide ultra-fast search with great accuracy.
- Hybrid search: You might want both semantic search and keyword search - Hybrid search - for specific use cases, and your provider should be able to support that. Pinecone uses the sparse-dense index to support hybrid search. Our research shows that hybrid search performs better on relevance compared to standalone keyword and semantic search.
- Filter on metadata: This is a way to add information to individual vectors to give them more meaning. By adding metadata to your vectors, you can filter by those fields at query time. This enables you to limit your vector search based on metadata and scope down queries, creating a faster and more accurate search.
For example, if you want to build a semantic search application for a large corporation to search through internal documents, metadata filters allow you to apply a set of conditions like dates and departments. Without metadata filters, you’re more likely to get irrelevant docs - someone in HR doesn't likely need to include engineering docs in their search.
There are different ways to do metadata filtering including pre-filtering and post-filtering. Pinecone uses single-stage filtering, which produces the accurate results of pre-filtering at even faster speeds than post-filtering.
- Live index updates: Supporting live index updates for up-to-date data helps maintain data freshness, which is crucial for real-time applications like chatbots. If your provider doesn’t support live index updates, you could be waiting for hours for updates to appear in search results.
Scalability
Scalability describes a system’s ability to grow. Figure out if there’s a limit to the number of vector embeddings the DB provider can support and how you can scale.
Most vector DBs allow you to scale both horizontally and vertically. Vertical scaling means adding resources to the existing system (scaling up), while horizontal scaling involves adding additional servers (scaling out). Each option has its pros and cons and needs to be evaluated case by case, but both require manual actions.
In a perfect state, you can scale automatically and don’t need to worry about how to scale at all because it’s all taken care of.
Cost-efficiency
A great system delivers satisfactory speed and accuracy at a reasonable price, not only for a small application but also when you scale to billions of embeddings. Estimate the number of embeddings you want to scale to, and ask your vendor what speed, accuracy, and price they can offer with your embedding number.
Developer Experience
You want a vector database that’s super easy for developers to get started with, and deliver value for your business soon.
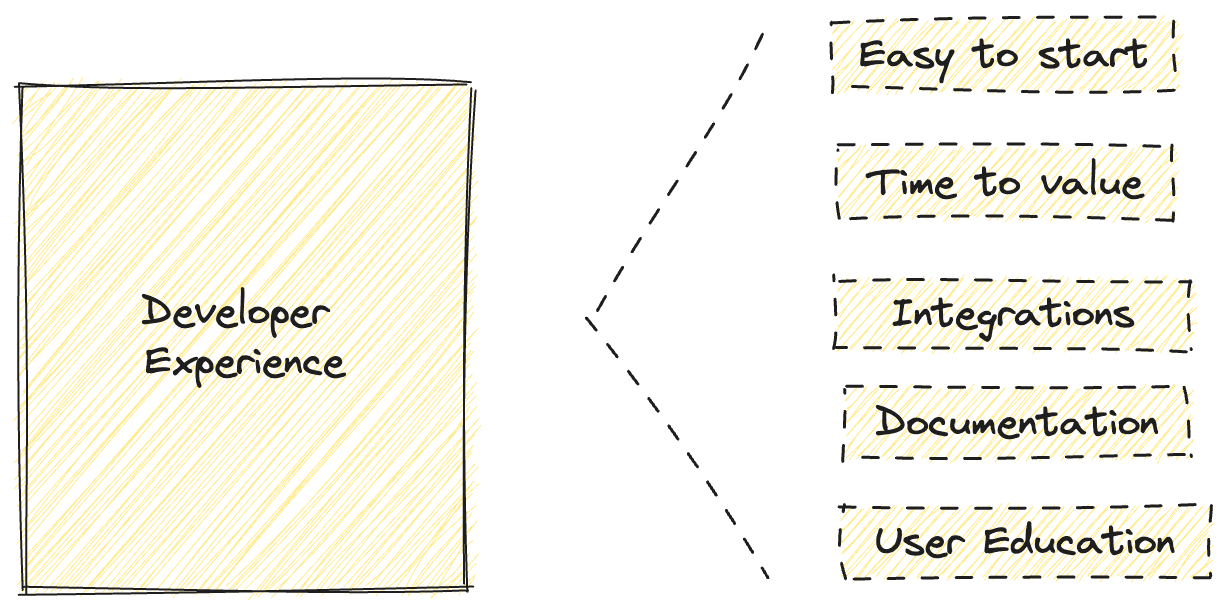
- Easy and quick to start: How much work does your team need to do to get started with this database? Do they have easy-to-use APIs and SDKs for various clients? SDKs offer a collection of tools, libraries, and documentation that empower your developers to build faster. For example, Pinecone offers SDKs for Python and Node.js.
- Time to value: How long does it take to build an application that works well in production to create business value? Find a provider that allows your team to ship a product-ready application very quickly.
- Documentation: Does the documentation offer clear navigation, onboarding examples, and all the material to help your team master the database quickly?
- Integrations:
- Cloud availability - Is the service available in your preferred cloud provider?
- LLM compatibility - Is the system compatible with different LLMs?
- System integration - Can this new database integrate with your existing infrastructure effortlessly? Does the vendor already have a variety of integrated AI ecosystem partners?
- User education: Does the vendor provide learning materials like blogs and videos, examples, community events & support, etc., to help your team master the tool and understand the space?
If your developer coworkers are looking to learn and experiment with vector databases, check out Pinecone’s Learn articles and examples. The examples present many different AI applications/patterns with runnable Jupyter Notebooks (a web-based interactive computing platform) available for each pattern. You’ll also find tutorial videos and a getting-started guide that your team can run for free on Google Collab, which hosts and runs notebooks.
Combined with Pinecone’s free tier, you have a free end-to-end solution for a developer to run, view, modify and experiment with working code across most of the common AI use cases in the field today.
Enterprise-Ready
Choosing a vector database that’s enterprise-ready, safeguarding your data, and making operations easy.
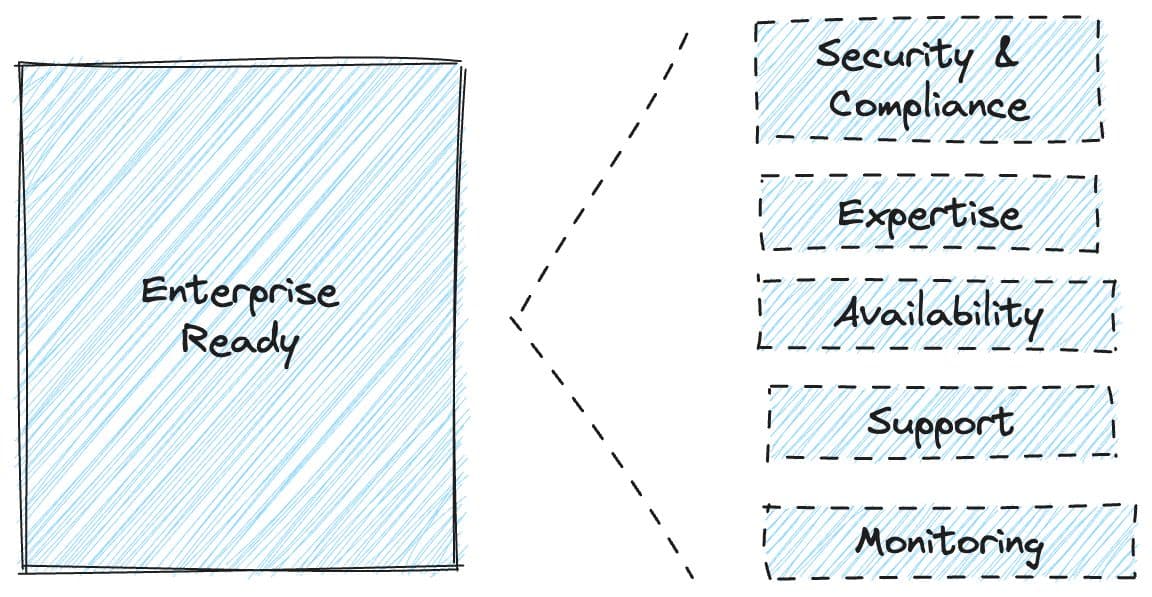
- Security & compliance: Make sure your provider meets your security and operational requirements. For example, is the data encrypted at rest and in transit? Are they SOC-certified, GDPR-ready, and HIPAA-compliant?
- Expertise: Can the solution provider work with you to design solutions for all your use cases? Are they up to date with the space to share helpful advice along your journey? If you’re new to the space, working with experts is key to success.
- Availability: It’s important for your applications to run uninterrupted, especially when they’re customer-facing. Confirm if the provider can offer a service-level-agreement (SLA) that guarantees the uptime they can deliver. An SLA outlines the commitment between the service provider and the client and aligns every party’s expectations.
- Technical support: Will you have a dedicated team to troubleshoot? When are they available?
- Monitoring: Efficient vector database management requires a strong monitoring system to track performance, health, and status. Monitoring is crucial for problem detection, performance optimization, and smooth operations. Can this provider make monitoring easy for you? You can monitor Pinecone with Datadog to optimize performance, control usage and get automatic alerts on metrics.
What’s next
We hope this high-level evaluation list empowers you to make an informed decision. The space is still young and rapidly evolving - if you still have questions, Pinecone is here to help. Contact our team of experts to help you understand everything about vector search and generative AI and design your best path forward. Move now and get ahead of your competition.
Was this article helpful?