Pinecone Nexus Is Now in Public Preview
Seven weeks ago, we announced early access to Pinecone Nexus, to deliver knowledge to AI agents. We’ve since partnered with a broad cohort of users spanning massive data, high complexity, and stringent accuracy, latency and cost requirements. Today, we are opening up public preview.
Distributed enterprise knowledge, compiled into something agents can rely on.
Agents built around frontier models are great at world knowledge, complex reasoning, and synthesizing information across disciplines. Finding specific information buried across files is a search problem, one vector databases have been chipping away at for years.
There's a third kind of knowledge that neither of those touches: business context. It's what a three-year employee knows without searching; which internal process doc reflects how things actually work today, what the quarterly goals mean in practice, how a policy in one department connects to a decision in another. It lives distributed across your enterprise in contracts, wikis, HR docs, meeting notes, support tickets, and financial records. Most of it has been written down somewhere, often many times over, but written down isn't the same as compiled, and an agent walking into a task needs the latter.
Every time an agent starts a task, it starts from zero on all of this. It can piece things together on the fly, but the cost shows up in tokens, in time, and in answers that are half right.
Pinecone Nexus is a knowledge engine that closes that gap. It compiles an enterprise's distributed knowledge into a structured layer agents can query directly, shifting token spend out of the per-query retrieval loop and into a one-time curation step.
Today, we're opening it up to anyone with a business use case. Pinecone Nexus is now in Public Preview.
What's Ready
Starting today, request access to Pinecone Nexus and see what curated knowledge does for agentic workloads on the dimensions that matter: cost, speed, and accuracy.
Nexus is built for bounded corpora where agents need to reason across documents. It's at its best on the kind of corpus where a single question touches dozens of files and standard retrieval starts falling apart.
There are two ways in:
Preview Playground: request access today and get a live environment to connect your data, design a Context, and run real queries. It's enough to validate the approach on something real before committing to a deployment.
BYOC Deployment: for production workloads, request a dedicated deployment. The cluster runs in your VPC with no shared infrastructure. Pinecone never has access to your data, your documents don't leave your infrastructure, and there's no shared compute with other tenants. Our deliberate focus on this deployment model is to align with the needs of enterprises where data residency, security, and compliance are non-negotiable.
See Nexus in Action
The demo above uses a synthetic financial services corpus of a household's complete set of financial records including their goals, plans, meeting notes, and portfolio documents. It’s the kind of corpus where a question like, "How are the Chens tracking against their retirement goals?" touches dozens of documents across multiple years, and unlike Nexus, a standard retrieval system would return chunks instead of fully-formed answers.
The Knowledge Engine, Explained
The results enterprises in Early Access are seeing aren’t a product of better prompting or a smarter model. They come from a different approach to how knowledge is organized before any query arrives. (See our previous blog, Nexus in the Wild: Real Results from Our Early Access Customers)
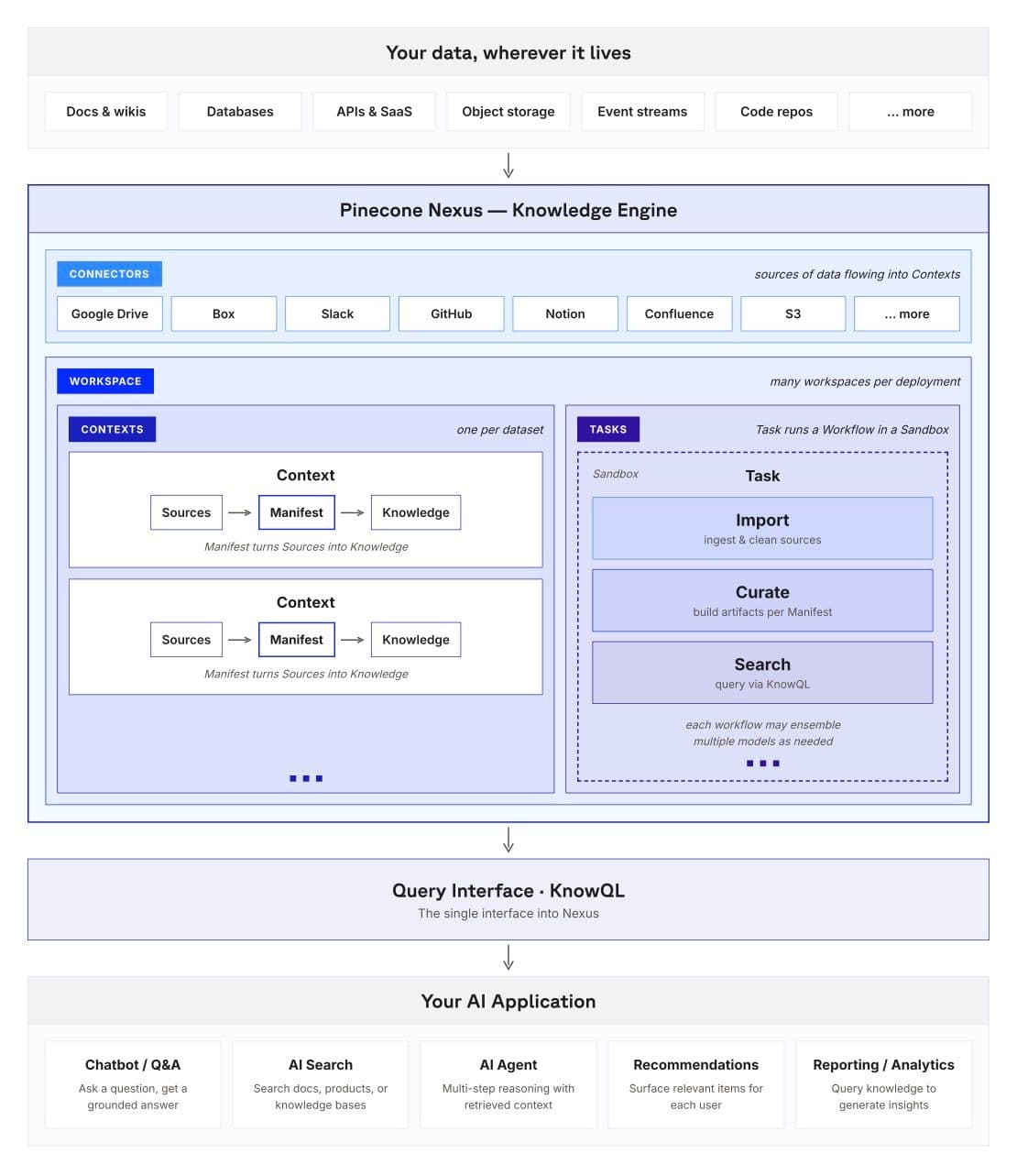
Connectors handle ingestion: Local file upload, Box, and Microsoft OneLake are live today, with Google Drive, Slack, GitHub, Notion, Confluence, and S3 close behind.
A Workspace is the top-level container: the boundary around a team or business unit. Connectors and other shared resources live at the Workspace level, so the natural mental model is one Workspace per team that owns its own data sources and access controls: a support org, a legal team, a data science group.
Inside a Workspace, your data is organized into Contexts: one per dataset or knowledge domain. Sources flow through Nexus's curation layer, guided by a Manifest that turns raw documents into structured knowledge artifacts tuned to the domain. The Manifest is the blueprint for how the corpus should be understood.
Tasks run the actual work inside isolated Sandboxes: import to ingest and clean sources, curate to build artifacts per the Manifest, and search to query via KnowQL. Each workflow can employ an ensemble of models, with the right model picked for each step. Everything surfaces through a single interface: KnowQL, the Query Interface into Nexus. Agents, chatbots, AI search applications, recommendation systems all tap into the same knowledge layer through one consistent surface.
SMEs in the loop
The people who know what questions matter, and what knowledge structure would answer them, usually aren't the engineers building the pipeline.They're the patent attorney who knows how patent standards are organized. The M&A analyst who knows which document categories need to be cross-referenced for a clean diligence answer. The revenue leader who knows which signals in a Gong transcript actually predict churn.
The Manifest is how we bring that person into the loop. A subject matter expert can design a blueprint defining the artifact types and relationships that encode their domain knowledge into the curation layer before any query runs. The agent isn't left to figure out the structure of the corpus at query time. It inherits the SME's understanding of it.
This is a different model than prompt engineering. The model isn't being coached at query time, it's being handed a knowledge layer that was designed by someone who actually knows the domain. The difference is between an agent that retrieves the most relevant chunk and one that reasons over a corpus already structured by someone who understood it. The answer comes out precise and fast, with the reasoning pointed in the right direction from the start.
Knowledge doesn't stay static. Regulations change, products evolve, and a corpus that was accurate six months ago develops what we call knowledge drift. Nexus lets SMEs re-curate: update the Manifest to reflect new requirements, rebuild the knowledge layer, ship. The agent stays current because the person who understands the domain stays in control of the knowledge layer.
More Benchmarks
Since opening Early Access, we've kept benchmarking. Different industries, different corpus shapes, same question: does the Manifest-driven curation model hold up when the knowledge problem gets harder or stranger? Three of those benchmarks are below.
Q2: Support Knowledge Base for Financial Services
Domain: Digital Banking / Financial Technology
Q2 builds digital infrastructure for financial institutions. Their support team works through thousands of technical knowledge base articles as part of standard triage, searching them every time a client calls in with an issue.
The articles themselves are easy to find. Most real support questions, though, have answers that live across several of them, and a wrong answer to a financial institution carries real downside, so accuracy ends up being the deciding criterion.
Q2 ran this benchmark themselves. They got early access to the preview environment, ingested their sources, designed a Manifest from a pre-built template, curated the artifacts, and ran the evaluation without Pinecone team in the loop.
Corpus: A sample of Q2's internal technical support knowledge base, covering the breadth of questions their support team handles daily.
Eval set: 20 questions across 6 categories: single-article lookups, two-article reasoning, multi-article synthesis, persona-based support scenarios, and customer cases. Designed to mirror the real question types Q2's support teams face daily.
Results:
| Metric | Result |
|---|---|
| F1 Score | 95% |
| Avg Recall (1–5) | 4.70 |
| Avg Precision (1–5) | 4.70 |
For Q2, accuracy was everything, and 95% on their hardest questions was the number that made the case. Jesse Barbour, Chief Data Scientist at Q2, put it best:
Q2 Quote
A Legal Research AI Company: Coverage and Reliability Over EU Case Law
Domain: Legal Research / LegalTech
This benchmark, run with a company building AI tools for legal research, tested Nexus on the task at the center of their product: answering substantive legal questions over EU case law and legislation. Nexus ran against an agentic-RAG baseline and a coding agent, with the same model composing every answer. Only the retrieval architecture changed, so any difference in the results is attributable to it.
The questions span the shapes a real legal researcher asks: looking up what a specific provision requires, tracing how a doctrine has been applied across cases, assembling every relevant precedent on a topic, and reasoning across multiple regimes at once. These are hard for standard retrieval for the same reason municipal records and support tickets are: the answer is rarely sitting in one document.
Corpus: 30,000 documents (~1.1 GB) of CJEU and General Court case law plus EU legislation, spanning 2021–2026.
Eval set: 35 legal research questions across 8 categories, including provision lookups, doctrine synthesis, cross-case and cross-regime reasoning, coverage and enumeration questions, precedent chains, and out-of-corpus negative controls.
Results:
| Metric | Nexus | Agentic RAG | Coding Agent |
|---|---|---|---|
| Completion rate | 100% | 66% | 6% |
| Accuracy | 87% | 45% | 4% |
| Avg Tokens per query | 9k | 80k (~9x) | 135k (~15x) |
The completion gap tells most of the story. The coding agent completed just 2 of 35 questions, browsing 30,000 documents by listing and reading files doesn't scale to a corpus this size. The RAG baseline did better but fell apart on doctrine synthesis, cross-case reasoning, and coverage questions, the shapes that require many sources assembled into one answer. On 12 of those, it never made it to composing a response at all. Nexus completed every question in the set, and even on the ones both systems answered, it was more accurate.
On a control question about U.S. securities law, asked of a corpus that contains only EU law, Nexus recognized the question was out of scope and said so. The other two systems fabricated answers.
A Leading Data Protection and Security Vendor: Cross-Document Reasoning Over Municipal Records
Domain: Enterprise Data Management
This benchmark, run with a data protection and security vendor, tested Nexus on a corpus where the documents themselves aren't technically complex, but they're structured so that almost no question can be answered from a single one of them.The corpus is 598 documents of municipal meeting minutes from a major city, spanning 2022–2025 across 13 governing bodies. Almost no question in the eval set can be answered from a single document. Counting a council member's attendance requires reasoning across roughly 40 documents. Resolving a project location requires joining an agenda item to its parcel number, applicant, and owner. Reading a motion's full vote requires extracting a structured roster from a narrative paragraph.
These are exactly the queries that expose the problem with standard retrieval. Chunk the corpus, embed it, and there's no way to answer "How many times did Mayor Smith preside over a city council meeting between 2022 and 2025?" without the agent looping back dozens of times to reassemble partial answers.
Corpus: 598 documents, one per meeting. 13 governing bodies. 4 years of data. Multi-session meetings with repeated structures.
Eval set: 100 questions across 13 categories including attendance counts, motion votes, officer history, project locations, deadlines. All cross-document by design.
The Manifest: 12 artifact types, including dedicated SQLite-backed tables for Meeting Attendance, Motion Log, Deadline Log, and Project Location.
Results:
| Metric | Result |
|---|---|
| Accuracy | 90% vs (RAG Baseline: 65%) |
| Curation cost (one-time, 598 documents) | $0.0038 per doc |
| Query cost | $0.0069 per question |
Curating 598 documents into 12 structured artifact types cost $2.31 and took 34 minutes. Every subsequent query runs against that curated index at a low average cost, with no per-query retrieval loop accumulating tokens. The knowledge gets compiled once.
A leading data protection and security vendor, a digital banking infrastructure provider, and a legal research AI company don't have much in common. One use case is reasoning across years of government meeting minutes, another is answering technical support questions for banks, and the third is legal research across tens of thousands of case law documents. But all three hit the same wall with standard retrieval, and all three saw the same thing when they switched to a knowledge layer built for their corpus: accuracy went up, costs came down, completion rates climbed, and questions that used to require multiple retrieval loops just got answered.
The shift is to compile knowledge upfront instead of reassembling it on the fly. When the knowledge layer is structured before a query arrives, the agent reads from a layer that already knows the shape of the corpus, rather than rebuilding that understanding from raw retrieval every time it gets asked something.
Start Building
If your agent setup has hit its ceiling on your corpus, has accuracy that won't improve, token costs that won't close a business case, latency that doesn't fit a live workflow… the issue is almost always in the knowledge layer, not the model.
Pinecone Nexus solves those problems. And when you're ready to go to production, BYOC deployment means your data never leaves your infrastructure. No shared environment, no data residency concerns, no compromises on security. Your cluster, your VPC, is fully isolated.
Was this article helpful?