Vector workloads aren't one-size-fits-all. Some applications, such as RAG systems, agents, prototypes, and scheduled jobs, have bursty, variable traffic. They spike, they idle, they spike again. Pinecone's On-Demand service is built for exactly this: elastic, usage-based, and cost-effective when query volume is unpredictable.
But when retrieval is both revenue-critical and consistently running at scale, the requirements change. Query volume is high and sustained, latency SLOs are tight, finance needs a number they can forecast, and per-request pricing stops being your friend. The cost curve steepens. Rate limits constrain throughput. And the question shifts from “does retrieval work?” to “can we run it affordably and predictably at this scale?”
Today, we're announcing Pinecone Dedicated Read Nodes (DRN) is generally available. DRN indexes are designed for workloads that need predictable performance, high throughput, and cost-efficient scaling under sustained load.
TL;DR
If you run search, recommendations, or agents with sustained, high-volume traffic, DRN gives you:
- Lower, more predictable cost with fixed hourly per-node pricing that is significantly more cost-effective than per-request pricing for high-QPS workloads and easier to forecast
- Predictable low-latency and high throughput through dedicated, provisioned read nodes with a warm data path (memory + local SSD) that keeps your vectors always hot, no cold start latency regressions
- Scaling that matches production traffic, via replicas for QPS and shards for storage, no rate limits constraining your throughput
- A single API call migration path from On-Demand with no reindexing, no downtime, and no code changes
- 77-97% cost reduction on real production workloads. See the examples below.
And with GA, DRN adds four new production capabilities for deeper control and observability. Read more about DRN's new GA capabilities here: Four New GA Features for Dedicated Read Nodes That Give Teams More Control and Observability.
Use the Pincone Assistant below to ask questions about Pinecone Dedicated Read Nodes – from use cases and scaling to cost model and migration. Or skip the assistant and read the rest of the blog post.
When revenue-critical retrieval consistently runs at scale, the economics change
Most teams don't fail because vector search “doesn't work.” Teams hit a different wall: retrieval is part of an end-user experience that drives revenue, and the economics and performance of that retrieval need to be as reliable as any other piece of critical infrastructure.
In practice, three things tend to happen at once as workloads scale:
- Per-request costs climb at sustained QPS. On-Demand's usage-based pricing is efficient for variable demand. But when volume is consistently high, costs scale with every query, especially when scanning large datasets. What was cost-effective at moderate traffic becomes expensive at sustained scale.
- Cost becomes hard to forecast. When pricing is per-request and volume fluctuates even modestly, forecasting spend requires assumptions. Finance wants a number. You can only offer a range.
- Rate limits constrain throughput. Multi-tenant serverless systems use rate limits to ensure quality of service across all users. That's good system design. For workloads that need thousands of queries per second without interruption, those limits become a ceiling you can't control.
At sustained scale, these tradeoffs carry real business consequences, especially when retrieval is revenue-critical:
- Hard-to-forecast spend from a request-driven cost curve at high, steady QPS
- Throughput ceilings from rate limits that can't flex with your traffic
- Slower product velocity when engineers work around limits instead of building features
DRN is built for workloads where retrieval performance and economics need to be planned and provisioned, not variable.
What workloads are a fit for DRN?
Choose DRN when your workload has:
- Consistent or high QPS: Hourly per-node pricing beats per-request pricing, often significantly
- Large vector counts: Hundreds of millions to billions of vectors benefit from DRN's always-hot data path, with indexes kept in memory and on local SSD, so there are no cold start latency regressions
- Tight latency SLOs: Dedicated resources give you a performance floor you control
- Predictable spend requirements: Fixed hourly pricing makes forecasting straightforward
On-Demand is the right fit for:
- Bursty or variable workloads: Elastic scaling and per-request pricing are more efficient
- Dev/test environments and prototypes: Lower cost, zero provisioning
- Workloads with many small namespaces: On-Demand's low latency and effortless scaling shine here
DRN is configured per-index. So you can run dev/test workloads on On-Demand and production workloads on DRN. Same platform, same APIs. Pinecone uniquely lets you mix these performance profiles within a single platform.
Customer story: how ZoomInfo scaled real-time recommendations (and kept costs predictable)
ZoomInfo builds go-to-market intelligence software that helps sales and marketing teams identify the right people and companies to engage. Their Applied AI team built a real-time contact recommendation system that required accurate, low-latency vector search over more than 390 million contact embeddings, with interactive UI expectations.
Pinecone became the foundation of their recommendation system. As traffic grew, Dedicated Read Nodes provided a straightforward way to isolate and scale reads with predictable performance and cost, without adding ops-heavy scaling, management, and tuning.
“Pinecone’s slab architecture and Dedicated Read Nodes gave us the speed, consistency, and isolation we needed to run real-time recommendations at scale. Instead of managing infrastructure, we spend our time improving our recommendation model and the product itself. That has reduced the time our customers spend researching, filtering, and evaluating contacts—from hours to minutes—by giving them the right people to reach out to with a single click.” — Carlos Nunez, Vice President of Engineering and Applied AI at ZoomInfo
In practice, DRN gave ZoomInfo predictable performance and cost-efficient scaling, while keeping the workflow simple to operate. So engineers could stay focused on model and product improvements rather than infrastructure management.
Read the ZoomInfo case study.
DRN in production: cost and performance across real workloads
The economics of DRN depend on the shape of your workload. Below are three production workloads that illustrate where DRN makes a big difference.
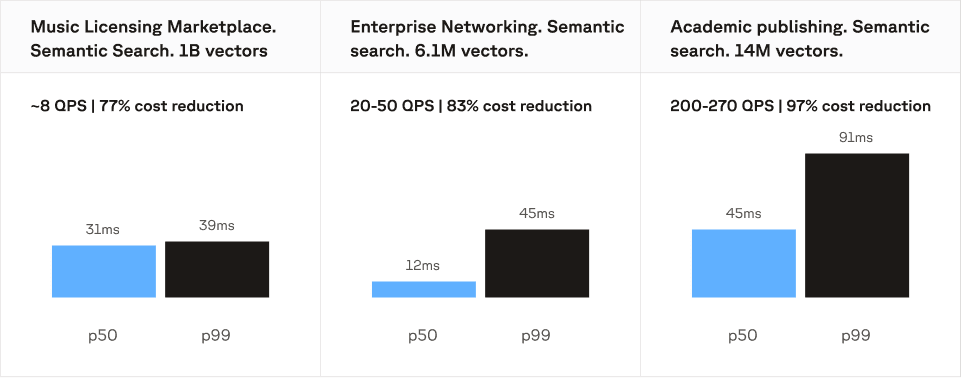
Billion-scale vector search: 77% cost reduction
A major music licensing marketplace runs semantic search over a catalog of 1 billion vectors in a single namespace. Query volume is low at ~8 QPS, but the dataset is large enough that per-request pricing adds up fast, because every query scans a massive index.
On DRN, this workload runs on T1 nodes with 14 shards and 1 read replica. Latency is tight: 31ms p50, 39ms p99. This workload costs 77% less to run on DRN.
The takeaway: even at low QPS, large vector counts drive meaningful savings on DRN because the cost scales with provisioned infrastructure, not per-query scans over a billion-vector index.
Low-latency search: 83% cost reduction
A global enterprise networking company uses Pinecone for search across a 6.1 million vector index at 20-50 QPS. The workload is small in vector count but latency-sensitive, and the consistent query volume makes per-request pricing expensive relative to the dataset size.
On DRN, this workload runs on T1 nodes with 2 shards and 2 read replicas. They achieve 12ms p50 and 45ms p99. This workload costs 83% less to run on DRN.
The takeaway: DRN's dedicated resources deliver a latency floor you control. When your SLOs are tight and traffic is steady, provisioned capacity is both faster and cheaper than paying per request.
High-QPS search: 97% cost reduction
A major academic and scientific publishing platform runs sustained search traffic at 200-270 QPS across a 14 million vector index. This is the workload profile where per-request pricing diverges most sharply from provisioned pricing: moderate-to-large dataset, high and consistent query volume.
On DRN, this workload runs on T1 nodes with 1 shard and 4 read replicas. They hit 45ms p50 and 91ms p99. This workload costs 97% less to run on DRN.
The takeaway: at sustained high QPS, DRN's fixed hourly pricing delivers a dramatic cost advantage. Replicas scale throughput near-linearly, so you add capacity in proportion to query volume rather than paying per request at every step.
DRN is now GA
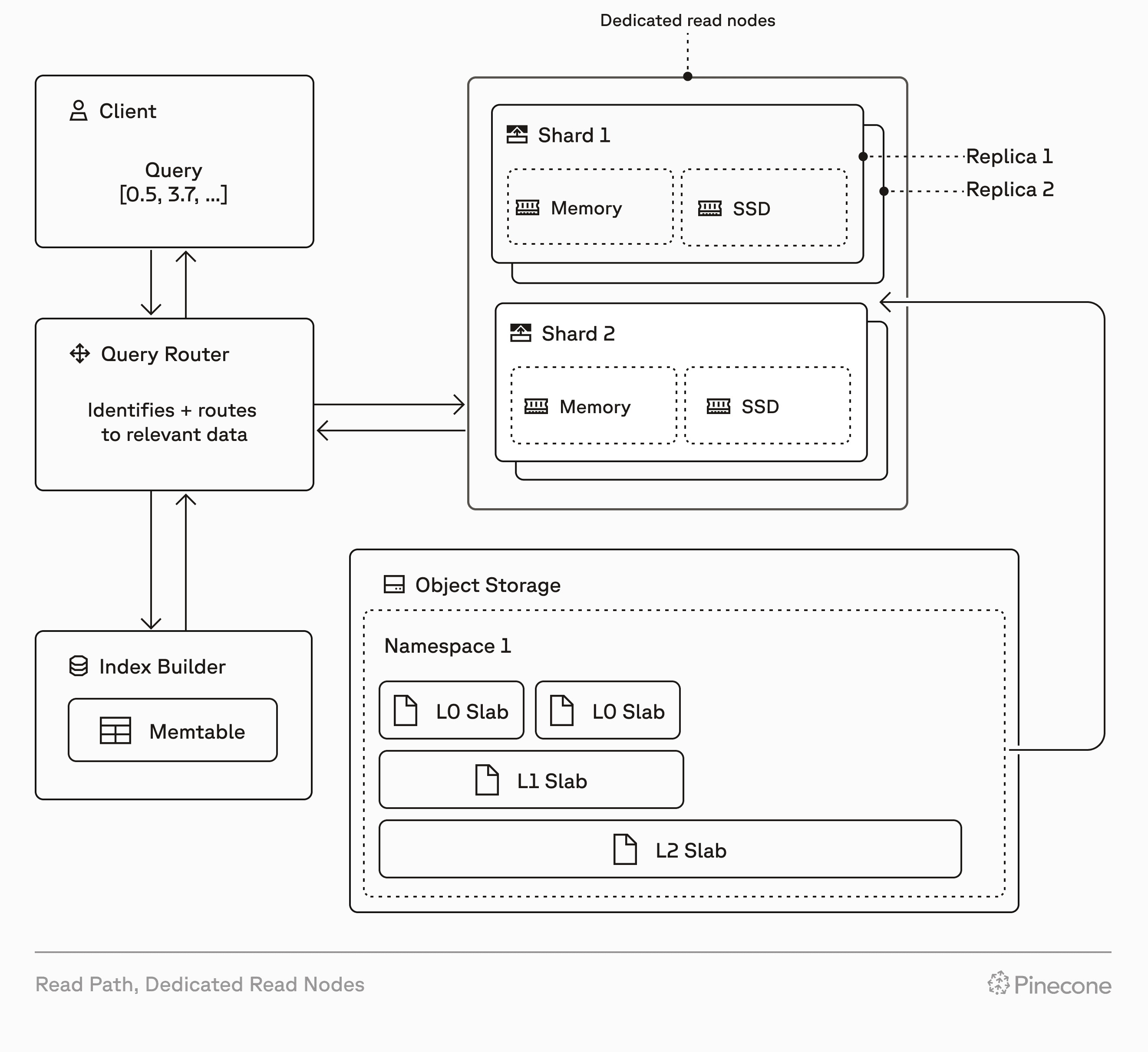
Dedicated Read Nodes gives your index a dedicated serving layer for reads while keeping everything else the same.
You keep:
- The same Pinecone APIs and SDKs
- The same write pipeline
- The same operational model for your index lifecycle
You add:
- Dedicated, provisioned read capacity per index
- A warm data path, with data always kept in memory and on local SSD
- No read rate limits, dedicated resources mean you control your throughput ceiling
You scale DRN in two dimensions:
- Replicas scale throughput and availability. Add replicas to increase QPS near-linearly.
- Shards scale storage. Add shards to grow capacity in fixed increments.
And because DRN is configured per-index, your dev/test indexes can stay on On-Demand while production indexes get dedicated resources. Same architecture, same APIs, same behavior, different cost and performance profiles where you need them.
DRN lets you keep Pinecone's simple developer experience while making read performance and costs predictable at production scale.
Four new GA features for deeper control and observability
DRN's core value stays the same: dedicated resources, always-hot data, and fixed-cost scaling. GA adds four capabilities that improve control and observability for day-2 operations: configurable performance vs. recall per query, metrics exporting for observability, a web console experience, and multi-namespace support (in early access).
Read more about DRN's new GA capabilities here: Four New GA Features for Dedicated Read Nodes That Give Teams More Control and Observability.
Make revenue-critical retrieval predictable at scale
The most expensive time to fix retrieval infrastructure is after users already depend on it. By then, every cost surprise has a real consequence: budget overruns trigger hard conversations, throughput ceilings slow product launches, and engineers spend time working around limits instead of building features.
Dedicated Read Nodes, now generally available, gives teams running revenue-critical retrieval at sustained scale a clean path to predictability: dedicated read capacity with always-hot data, no read rate limits, and fixed hourly pricing that scales with your infrastructure, not your query count.
Create a DRN index to get started, or read the DRN documentation for configuration details, scaling guidance, and API reference.
Was this article helpful?