ZoomInfo Delivers High-quality, Real-time Contact Recommendations for GTM Teams with Pinecone, Driving a 50% Increase in User Engagement

>50%
increase in user engagement
2x
increase in relevancy and recall
50x
increase in customer peak requests served
ZoomInfo provides go-to-market intelligence software used by sales and marketing teams to identify the right people and companies to engage. Its platform includes hundreds of millions of professional contact records, enriched with firmographic data and advanced AI search tools.
To give its customers faster and more relevant results, ZoomInfo’s Applied AI team set out to build a real-time contact recommendation system at scale. The goal was to change how users discover the right people to reach out to inside a target account. Instead of manually searching and filtering, users would receive personalized suggestions the moment they viewed a company profile.
Building this capability required accurate and low-latency vector search over more than 390 million contact embeddings. The team needed a vector database that was simple to use, production-ready, and able to support the full customer base and more. After early experimentation, ZoomInfo chose Pinecone.
Delivering real-time personalized recommendations at scale
ZoomInfo wanted to transform how its users discover the right people to contact inside a target account. The existing experience required users to manually search, filter, and navigate through large volumes of professional contact data. This slowed time-to-action and made it harder for sales teams to quickly identify the most relevant buyers. For many users, identifying the right contacts often required hours of manual searching and filtering across large datasets.
The Applied AI team began engineering a system that could generate personalized recommendations the moment a user viewed a company profile. This involved building and tuning vector embeddings from its proprietary contact data using a ~400M-parameter text embedding model, producing high-dimensional representations optimized for real-time relevance. It also required a new technical foundation: real-time semantic search over hundreds of millions of contact embeddings, with accuracy strong enough to meaningfully improve user engagement.
Several constraints made this challenging:
- Real-time latency: Results needed to return in under a second to support an interactive UI
- Massive scale: The system needed to serve vectors across more than 100,000 namespaces and support traffic growth across ZoomInfo’s large and increasing customer base
- High recall and ranking quality: Recommendations had to outperform existing algorithms to justify rollout
- Operational reliability: The team required predictable performance with no complex tuning or manual system management
- Throughput growth: Full deployment required on the order of hundreds of queries per second, with headroom to continue scaling
- Developer efficiency: The team needed a solution that allowed rapid iteration without adding infrastructure overhead
ZoomInfo considered vendors including Milvus, pgvector, and Spanner. Milvus and other open-source vector databases depended on deep expertise in ANN tuning and distributed cluster management, which would add ongoing operational overhead for ZoomInfo. pgvector and Spanner, as bolt-ons of traditional database systems, were constrained by architectures not designed for high-throughput vector search at scale, leading to performance and scalability limitations.
These challenges created a clear need for infrastructure that could support high-volume, low-latency vector search while remaining simple to integrate and operate across ZoomInfo’s platform.
Implementing real-time vector search with Pinecone
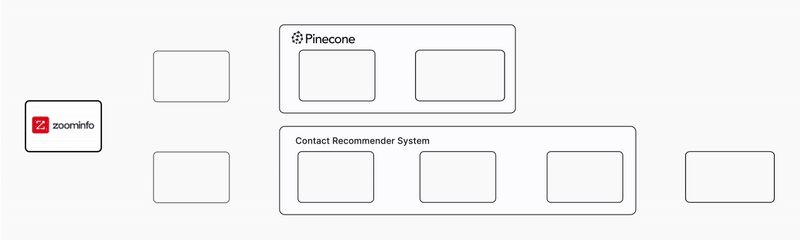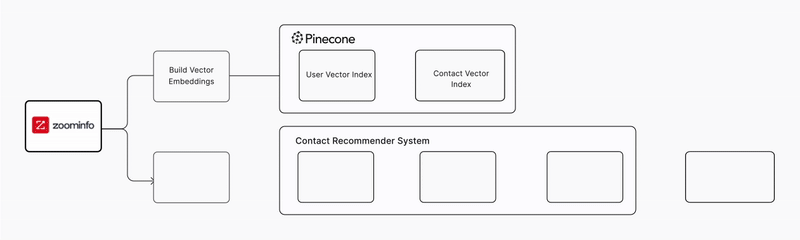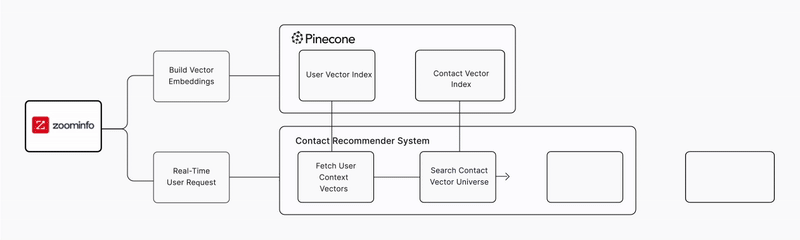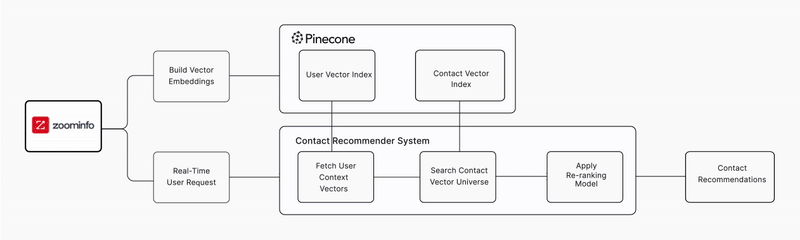
To build a real-time semantic search system that could support its recommendation workloads, ZoomInfo adopted Pinecone as the vector database powering the platform. Pinecone provided the reliability, accuracy, and operational efficiency the team needed to deliver fast, personalized results at scale. These capabilities allowed ZoomInfo customers to shift from a manual, multi-step discovery process to an instant, recommendation-driven workflow.
ZoomInfo began by building an end-to-end proof of concept using Pinecone’s Python SDK. Within three weeks, the team had loaded millions of embeddings, validated recall, and confirmed that Pinecone could meet sub-second latency requirements without manual index configuration or tuning. In parallel, the Applied AI team engineered data pipelines to generate and update these embeddings at scale, ensuring that Pinecone’s vector indexes remained fresh as new contact information was added to the platform. They also evaluated model outputs for relevancy and quality to verify that the system delivered meaningful recommendations for end users. This early phase proved that Pinecone could support the level of performance necessary for an interactive recommendation experience.
In Pinecone’s serverless environment, storage and compute scale independently, and the platform automatically manages indexing, capacity, and resource allocation. Because users never manage clusters, nodes, or machines directly, ZoomInfo could rely on Pinecone to handle sharding, data distribution, and performance optimization under the hood. This removed the operational overhead typically associated with vector infrastructure and allowed ZoomInfo’s engineers to focus on modeling, evaluation, and product integration instead of system maintenance.
ZoomInfo also benefited from Pinecone’s unique slab architecture, which stores vectors in large, contiguous units to avoid the fragmentation and unpredictable access patterns common in other vector databases. With slabs, all operations remain independent; data is available the moment it is written, and the system never pauses for background index optimization. Writes proceed at a constant speed without blocking queries, and reads fan out across slabs in parallel, allowing the system to consider all relevant data efficiently during search. Combined with Pinecone’s use of memory-mapped files for fast access, this design provides the predictable, low-latency performance needed to support ZoomInfo’s real-time recommendation workloads as they increase.
As the system grew to support more products and user cohorts, Pinecone’s Dedicated Read Nodes (DRN) became an important part of the deployment. DRN provides isolated read replicas with a warm data path—memory plus local SSD—that delivers predictable low-latency performance even under sustained, high-QPS workloads. Replicas scale throughput linearly, while shards scale storage, giving ZoomInfo a clear path to grow without re-architecting the system. The predictable, per-node pricing model also offered better cost efficiency than per-request pricing for ZoomInfo’s steady, always-on traffic patterns.
Pinecone’s slab architecture and Dedicated Read Nodes gave us the speed, consistency, and isolation we needed to run real-time recommendations at scale. Instead of managing infrastructure, we spend our time improving our recommendation model and the product itself. That has reduced the time our customers spend researching, filtering, and evaluating contacts—from hours to minutes—by giving them the right people to reach out to with a single click. — Carlos Nunez, Vice President of Engineering and Applied AI at ZoomInfo
Higher relevance, faster decisions, and scalable performance
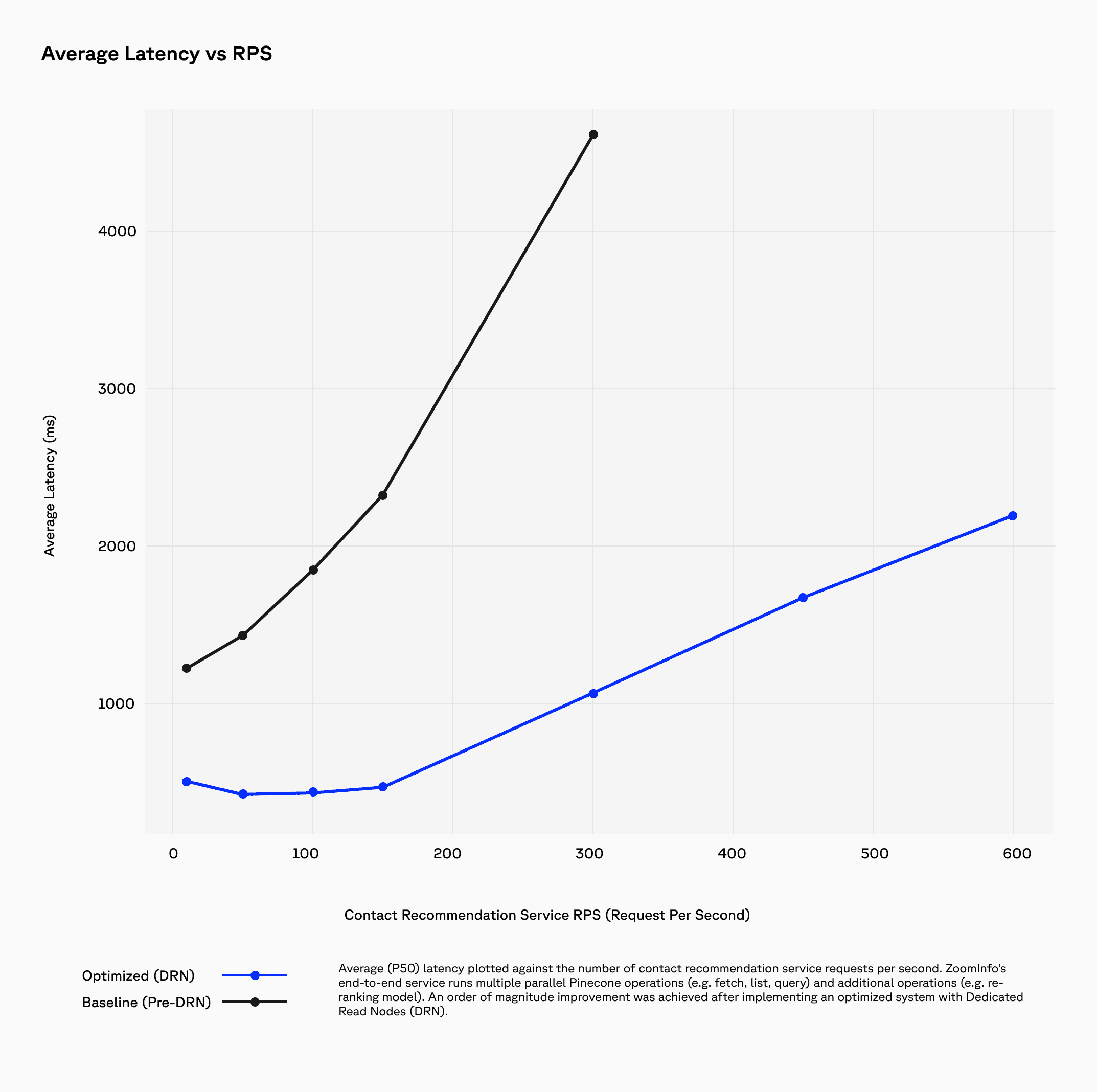
With Pinecone powering its real-time recommendation system, ZoomInfo improved relevance, user engagement, and system performance across its platform.
Pinecone’s vector search accuracy made recommendations more actionable, helping users act faster and spend less time searching for the right contacts. These improvements strengthened customer interaction with the feature and supported a more efficient workflow for sales teams.
Pinecone’s asynchronous operations, serverless design, slab-based storage, and Dedicated Read Nodes also provided the throughput and latency stability required to expand recommendations across ZoomInfo’s product suite. The system maintained predictable performance under sustained traffic while reducing the operational burden associated with managing vector infrastructure. Pinecone sustained a P50 latency of ~60ms at ~40 QPS, which helped ZoomInfo’s goal of keeping the end-to-end latency of the entire recommendation service below 1 second for lighter loads (<100 RPS), and less than 5 seconds for heavier loads (>100 RPS). This was achieved even as ZoomInfo scaled to more than 390 million vectors.
Pinecone enabled us to build, scale, and optimize a real-time contact recommendation system that processes thousands of large-embedding-model vector search queries per second, which has driven a 2x improvement in relevancy and 50% boost to user engagement. — Tamiro Scholer, Senior Data Scientist at ZoomInfo
Key Outcomes
- >50% increase in user engagement, driven by more relevant and timely recommendations
- 2x improvement in relevancy and recall, resulting in higher-quality suggestions
- 50x increase in peak customer requests served, enabling rollout across more products and cohorts
- Consistent low-latency performance, supported by slab-based storage and Dedicated Read Nodes
- Reduced operational overhead, freeing engineering time for model and product improvements
- Faster time-to-action—from hours to minutes—for end users, with instant access to high-quality contact recommendations
ZoomInfo now delivers a faster, more accurate recommendation experience that helps users identify the right buyers quickly and take action sooner, strengthening the value of its platform.
Expanding real-time recommendations across the platform
With a scalable and reliable vector search foundation in place, ZoomInfo plans to expand its recommendation capabilities across more products, customer segments, and internal applications. The Applied AI team is exploring additional ways to use Pinecone to support new surfaces, new types of recommendations, and broader adoption throughout the platform.
ZoomInfo expects to extend the same real-time semantic search pipeline to power new workflows for go-to-market teams, as well as additional AI-driven insights built on the underlying dataset. Future enhancements will continue to focus on shortening time-to-action for customers by surfacing the most relevant insights immediately within their workflow. As usage grows, Pinecone’s combination of serverless scale, slab-based storage, and Dedicated Read Nodes will continue to provide the predictable performance and cost efficiency needed for sustained high-QPS and low-latency workloads.
Over time, ZoomInfo plans to increase traffic volumes even further and integrate recommendations into more touchpoints across its product suite. With Pinecone, the team is well positioned to support these growth targets while maintaining the responsiveness and accuracy that end users rely on. — Nilesh Mishra, Senior Manager of Applied AI at ZoomInfo