Searching for Birds with Pinecone Full-Text Search
Semantic search excels at meaning, but some queries demand exactness. It finds documents that mean roughly what the user asked, even when the exact words don't match. That's useful until you need a specific term, a verbatim phrase, or an explicit exclusion — like an error code, or legal clause. When search returns “close enough” instead of exact, users lose trust and developers spend time debugging.
Full-text search is built for exactly those cases. Pinecone’s implementation runs BM25 scoring against string fields in your index, supports Lucene query syntax for boolean and phrase queries, and can be combined with dense or sparse vector ranking when you need both lexical precision and semantic similarity.
By the end of this post, you'll have a working reference for every query pattern and a new appreciation for North American birds. The examples use a flock of 200 North American bird articles indexed with three searchable text fields: bird_name, intro, and body. The body field has stemming enabled; bird_name and intro don't. The index also includes an image_embedding field, a 768-dimensional dense vector from Gemini Embedding 2, which we'll use when combining vector search with text filtering.
Want to follow along in code? The full notebook is here.
Each section below adds one tool to your query-building vocabulary, starting with a single token match and ending with combining dense vector ranking with a text filter.
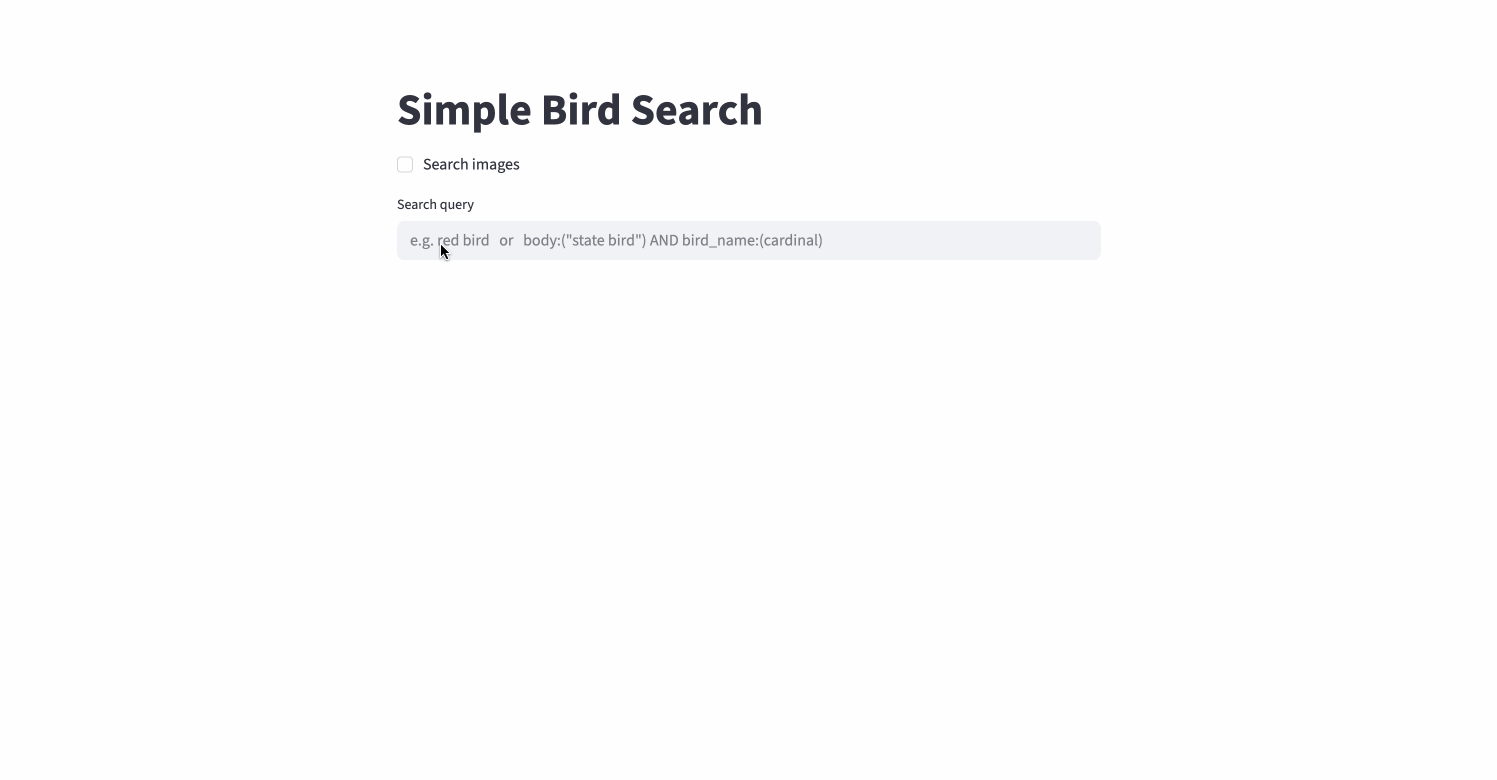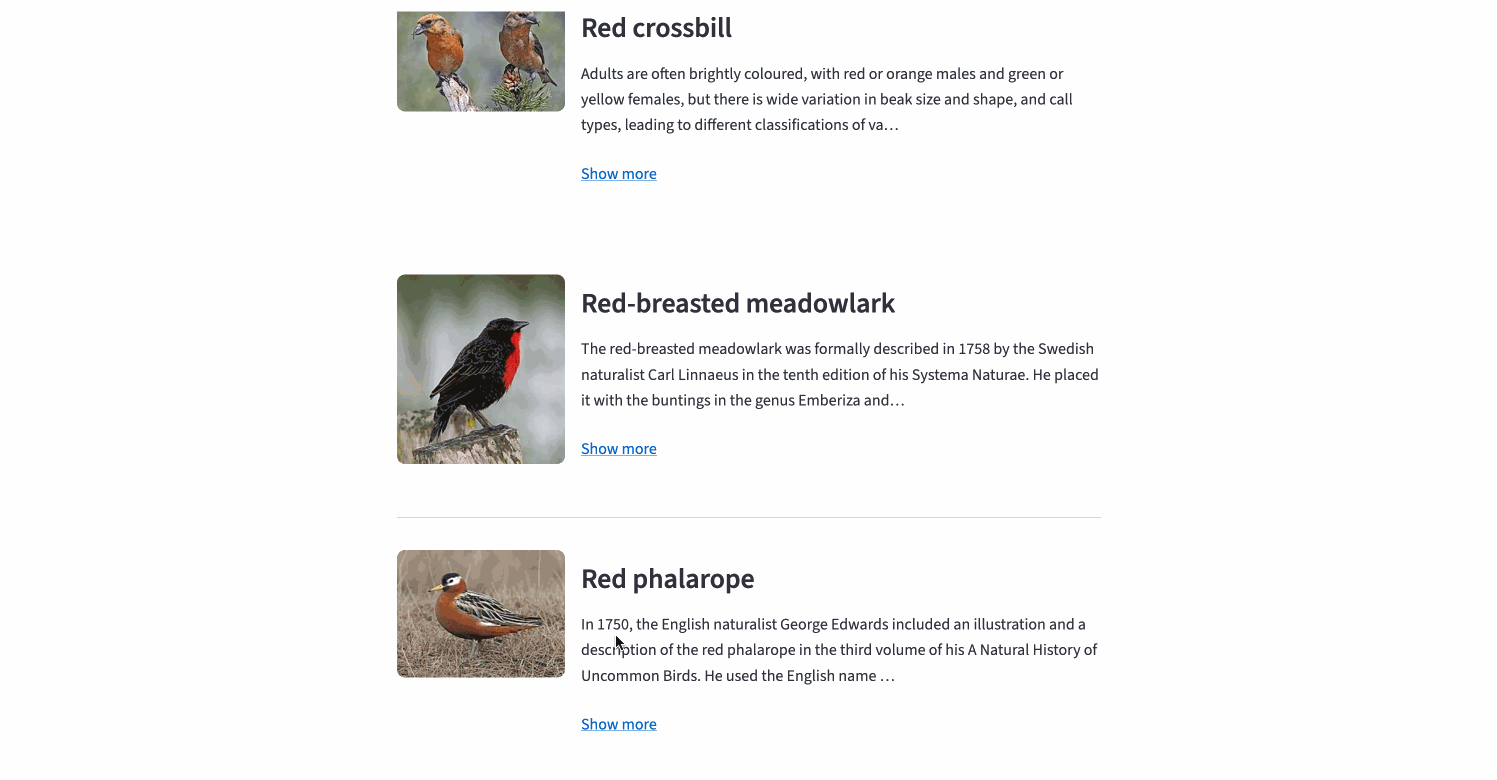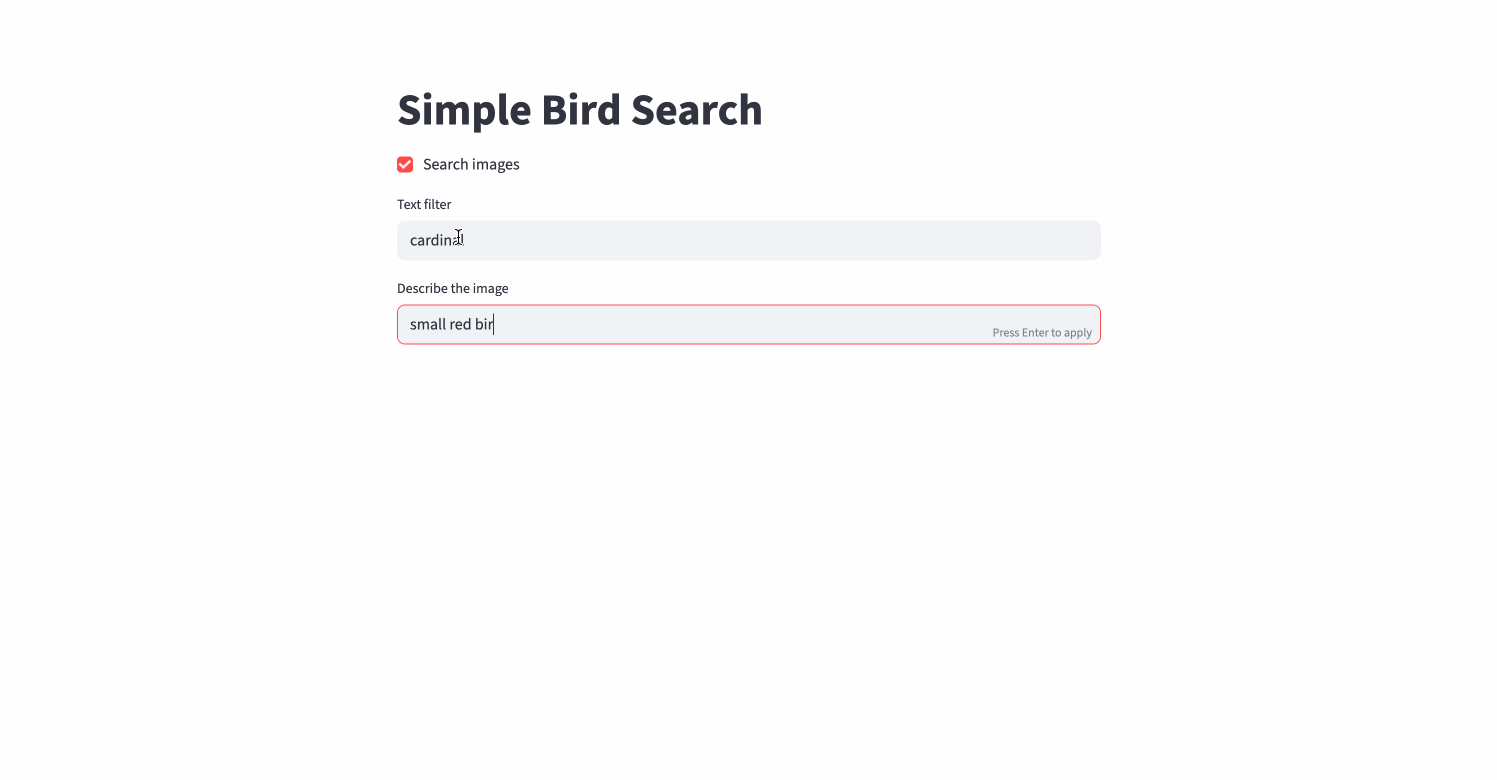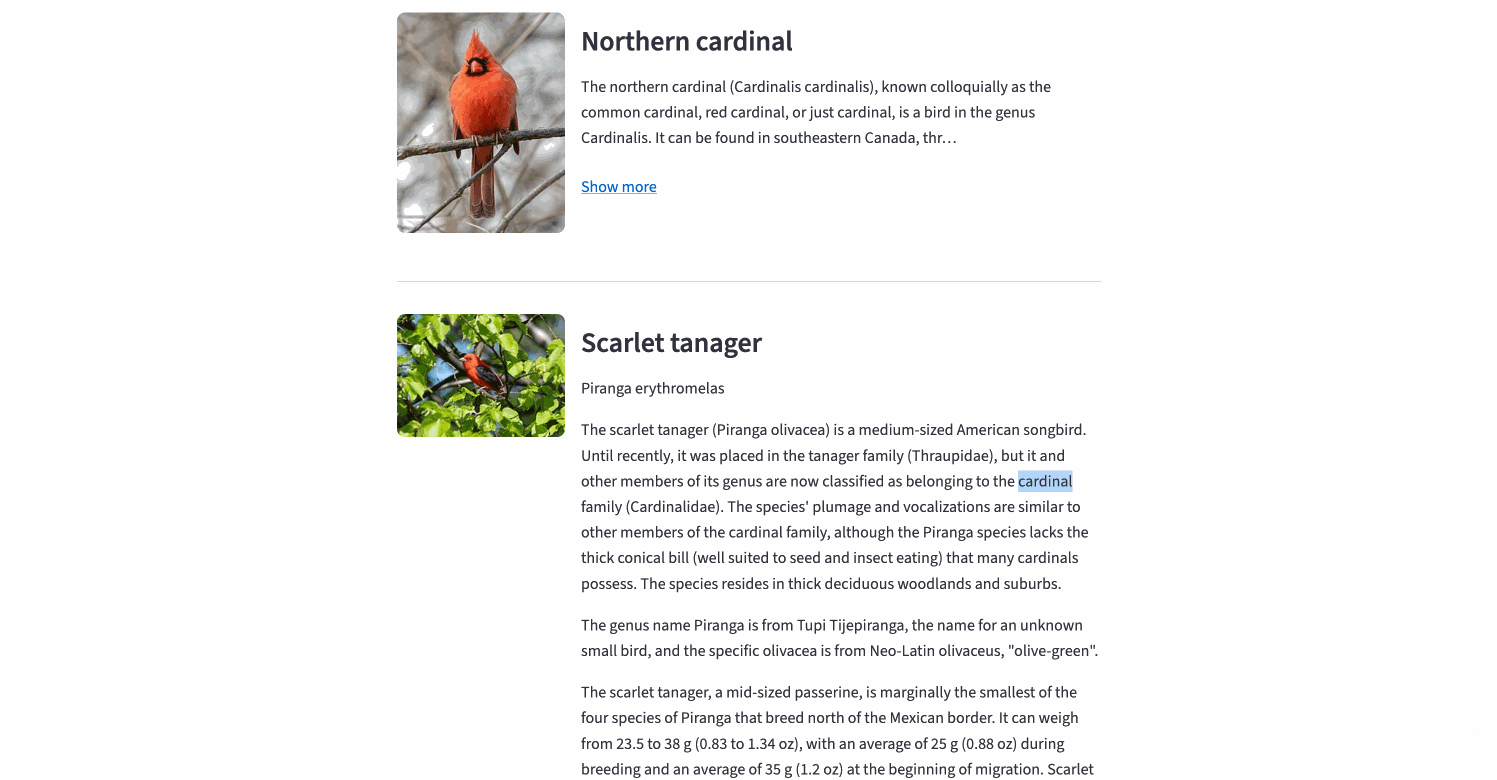
Simple queries: single-term and multi-field
The simplest full-text query is a type: "text" clause targeting a single field. Here it searches the body field for documents containing the token "migration".
A note on tokens: in full-text search, a token is a unit produced by splitting text on whitespace and punctuation, lowercasing, and optionally stemming — not the same as a token in an LLM or embedding model. "Black-throated" becomes two tokens (black, throated); "migrating" with stemming enabled becomes migrat. Dense and sparse vector encoders use their own internal tokenizers entirely separate from this pipeline.
response = idx.documents.search(
namespace="birds",
top_k=5,
score_by=[
{"type": "text", "field": "body", "query": "migration"},
],
include_fields=["bird_name", "body"],
)Because body has stemming enabled, this query also matches "migrating," "migratory," and "migrated" — the analyzer reduces all of them to the same root token at index time and query time both.
To search across multiple text fields simultaneously, pass multiple score_by clauses — one per field. A query for "sparrow" against bird_name only returns 5 birds with "sparrow" in their formal English name. Blending all three fields surfaces Ammospiza maritima mirabilis (the Cape Sable seaside sparrow), a bird whose Latin name gives nothing away but whose article body uses the word “sparrow” six times:
score_by=[
{"type": "text", "field": "bird_name", "query": "sparrow"},
{"type": "text", "field": "intro", "query": "sparrow"},
{"type": "text", "field": "body", "query": "sparrow"},
]
# Ammospiza maritima mirabilis appears at score 9.9170 — missed by name-only searchBoolean logic: AND and NOT
type: "text" with multiple words uses OR semantics — a document only needs one term to match. For stricter control, switch to type: "query_string", which exposes Lucene syntax. The field name moves inside the query string itself.
AND requires both terms in the field:
score_by=[{"type": "query_string", "query": "body:(aquatic AND diving)"}]
# → Arctic loon (5.5609), American white pelican (4.3182), American coot (4.2712)NOT (or the - prefix) hard-filters any document where the excluded term appears anywhere in the field:
score_by=[{"type": "query_string", "query": "body:(raptor NOT owl)"}]
# → American kestrel (4.1918), American black vulture (2.8799)Owls are out entirely — even a hawk article that mentions owls in passing gets excluded.
Phrase matching and proximity
By default, bird_name:(crested hummingbird) uses OR, any name containing either "crested" or "hummingbird" qualifies. Wrapping the terms in double quotes requires them (or their root tokens if stemming is enabled) to be adjacent and in order:
# Token OR — 5 results (anything with "crested" or "hummingbird")
score_by=[{"type": "query_string", "query": "bird_name:(crested hummingbird)"}]
# Exact phrase — 1 result: Antillean crested hummingbird
score_by=[{"type": "query_string", "query": 'bird_name:("crested hummingbird")'}]When you want the tokens near each other but not necessarily adjacent, use slop with ~N:
# Strict: "nest colony" tokens must be directly adjacent
body:("nest colony")
# Slop ~3: up to 3 intervening or reordered tokens allowed
body:("nest colony"~3)
# → also matches "nest in a colony", "colonial nesting", "nesting in large colonies"Slop is useful for domain language where two terms are conceptually tied but don't always appear side by side in natural text.
Tuning relevance with boosting
Unlike boolean operators, which filter documents in or out entirely, boosting is softer. ^N multiplies a term's BM25 score by N, shaping the ranking without excluding anything. Documents that lack the boosted term can still appear if they score well on the other terms.
# "foraging" counts 3x; "feeding" and "diet" contribute normally
body:(foraging^3 feeding diet)
# → American white ibis: 5.8757
# All terms equal weight
body:(foraging feeding diet)
# → American white ibis: 3.3993Same top result either way, but the score gap shifts the relative ranking of everything below it. Phrases can be boosted too: body:("aerial foraging"^2 insects) boosts the exact adjacent phrase rather than a single token.
Cross-field and composed queries
A single query_string clause can combine multiple fields with boolean operators:
score_by=[{"type": "query_string", "query": 'bird_name:(hawk) AND body:(hunting prey)'}]
# → Bicolored hawk (7.6021), Black-and-white hawk-eagle (7.0616)Unlike multi-clause score_by blending, where scores are summed across any matching clause, this requires both sub-clauses to be satisfied.
For a production query, compose all the concepts together:
QUERY = (
'bird_name:(hawk^2 OR eagle) AND '
'body:(("dense vegetation" OR "forest canopy") AND hunt -fish)'
)
score_by=[{"type": "query_string", "query": QUERY}]
# → Black-and-white hawk-eagle (14.2552), Bicolored hawk (12.9971)Clause by clause: hawk^2 boosts hawks over eagles in ranking; OR eagle allows either; the body clause requires forest-interior habitat and active hunting while excluding fish-eaters. A single expression does the work of several filters.
When building queries this complex, test incrementally — add one operator at a time and verify the effect before combining.
Regex and autocomplete
Lucene regex syntax matches against the entire indexed token, not the full field string. This makes suffix matching possible where a simple token search fails:
# "bird" as a standalone token — no matches in this corpus
score_by=[{"type": "query_string", "query": "bird_name:(bird)"}]
# Regex: any token ending in "bird"
score_by=[{"type": "query_string", "query": "bird_name:/.*bird/"}]
# → Amazilia hummingbird, Amethyst-throated hummingbird, Anna's hummingbird, ... (all score 1.0)Phrase prefix adds autocomplete-style expansion by treating the last token as a prefix:
score_by=[{"type": "query_string", "query": 'body:("tropical fo"*)'}]
# matches "tropical forest", "tropical foliage", "tropical food sources" ...The preceding tokens must match exactly; only the final one is expanded. Single-token prefix wildcards (tropic*) are not supported — the phrase needs at least two tokens before the *.
Combining dense vectors with text filters
Full-text and dense vector scoring each solve a different part of the retrieval problem. Text queries give you lexical precision with exact terms, required phrases, and boolean logic. Dense vectors give you semantic similarity with synonyms, paraphrases, and conceptual neighbors. Combining them means text filters narrow the candidate set by keyword logic and vector scoring ranks everything remaining by meaning. They run in the same query against the schema.
Consider a bird identification scenario where a user wants to find all the woodpeckers that can be visually described as "prominent red crest". The filter guarantees every result mentions that “woodpecker”; the image embedding then ranks by semantic similarity to “prominent red crest” within that constrained set.
query_vector = (
gem.models.embed_content(
model="gemini-embedding-2",
contents="prominent red crest",
config=types.EmbedContentConfig(output_dimensionality=768),
)
.embeddings[0]
.values
)
response = idx.documents.search(
namespace="birds",
top_k=5,
score_by=[{
"type": "dense_vector",
"field": "image_embedding",
"values": query_vector,
}],
filter={"body": {"$match_phrase": "woodpecker"}},
include_fields=["bird_name", "body"],
)Three filter operators are supported: $match_phrase for terminology precision, $match_all as an AND-style gate without scoring, and $match_any to broaden a constrained vector search. Filters can also be composed with $and and $or across fields.
Wrapping up
Semantic search handles meaning. Full-text search handles precision. In practice, the two aren't competing — they're complementary, and Pinecone lets you use both in the same index.
Reach for the patterns in this post (boolean logic, phrase matching, boosting, regex, and vector ranking combined with a text filter) when the answer needs to be exactly right and a close match isn’t good enough.
To dig deeper, this bird search notebook has the full examples with this dataset including index creation and data loading. The bird search web app shows several of these patterns running together in a Streamlit app. And the Pinecone full-text search guide has the complete API reference and the full list of supported Lucene syntax.
Ready to build? The full-text search skill gets you set up with a working index in minutes right inside your agentic tooling.
Was this article helpful?



