Back in August, we announced a new performance pod type - p2 - in public preview. Different from the existing p1 pods, p2 pods use a new graph-based index to provide blazing fast search speeds (up to 10x faster than p1) and higher throughput (up to 200 QPS) per replica.
Today, we are excited to announce that p2 pods are now generally available for all users. Since the preview announcement, we have made the pods even more efficient and accessible for high-throughput use cases. Along with being generally available, p2 pods are now:
- Available in the Starter (free) plan: Users can now easily experiment with high-throughput use cases with a single p2 pod. Try a p2 pod today without any commitment!
- 50% lower in cost: We’ve continued to invest in optimizing p2 memory utilization throughout public preview. These optimizations allow us to reduce the p2 price by 50%, making p2 a more cost-competitive option than ever before.
- Dot product compatible: Along with support of cosine and euclidean distance metrics, p2 pods now support dot product. Choose the metric that works best for you.
Updated pricing for p2 pods has been in effect since December 1, 2022, starting at $0.144/hour and up depending on plan, pod size, and cloud environment. See the pricing page for more details.
Deciding between pod types? When to consider p2
In general, p2 pods are designed for applications that require minimal latency (<10ms) and/or high throughput (>100 QPS). Examples of performance-focused use cases are movie recommendations on video streaming applications or personalization in social media feeds.
Here are some sample query latencies using a single p2.x1 pod:
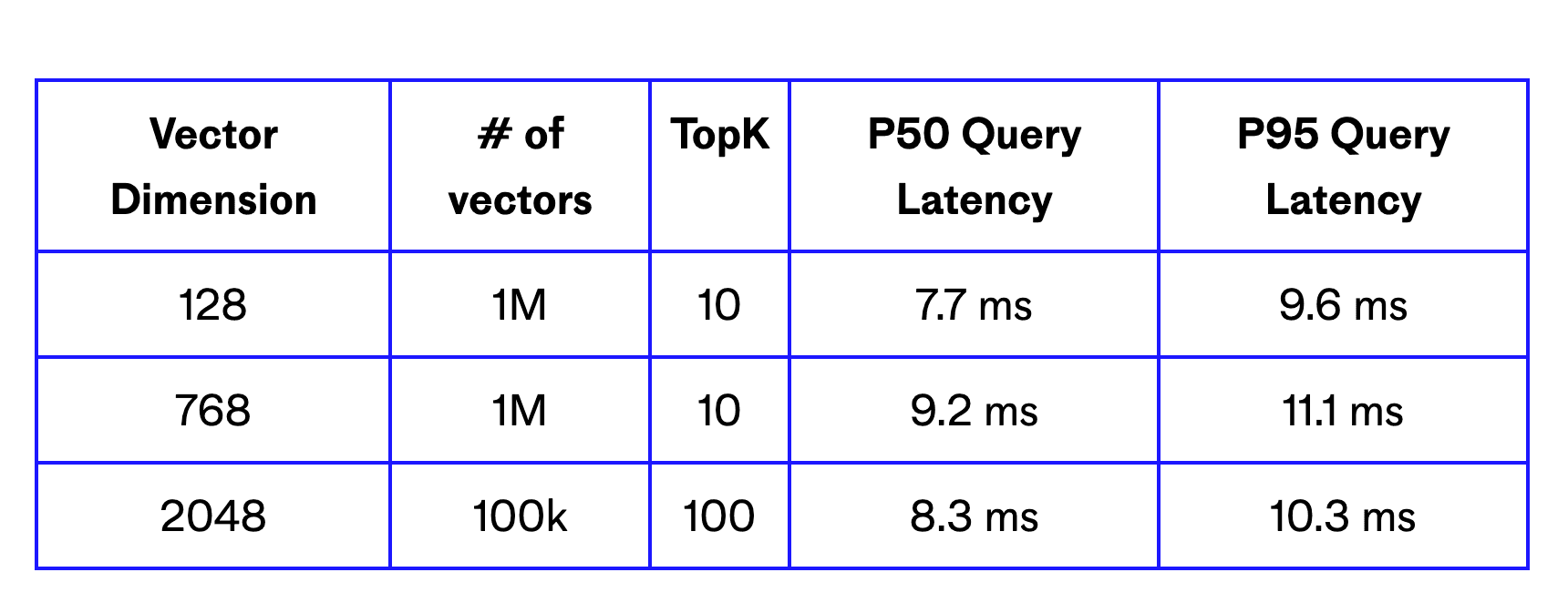
Vertically scaling p2 pods also improves each pod’s throughput. For example, with a single p2.x8 pod, you can support over 1000 QPS searching across 10 million 256 dimension vectors.
As always, your performance and accuracy may vary and we encourage you to test with your own data and follow our tips for performance tuning. Performance is dependent on vector dimensionality, topK, filter conditions, cloud provider, and other factors.
If you have high storage and low QPS requirements, consider using our s1 pod type.
Get started
Check out the documentation to learn more and how to start using p2 pods. We will share benchmarks against p1 in the near future, so stay tuned!
Was this article helpful?