How Language Embedding Models Will Change Financial Services
How financial players are using vectorized data to gain insights.
In finance, big profits are usually reserved for the ones who get the insights first. Each second counts, and high frequency trading algorithms are clear examples of this. But it’s not only a matter of speed: Data aggregation and knowledge discovery have become essential abilities. This is the reason why so many financial players are turning into data science companies.
Traditional financial data sources, like company filings, are widely available and accessible to everyone. Moreover, so many companies mask their accounts that financial statements are becoming less and less valuable to get to the insight first. So what are financial companies doing? Turning to alternative data.
Alternative data refers to non-traditional data that can provide an indication of future performance of a company outside of traditional sources. You can think of examples like records from credit card transactions, web-scraped data, geolocation data from cell phones, satellite images and weather forecasts. These sources are less structured and usually less accessible than the traditional ones, making them ideal for uncovering insights.
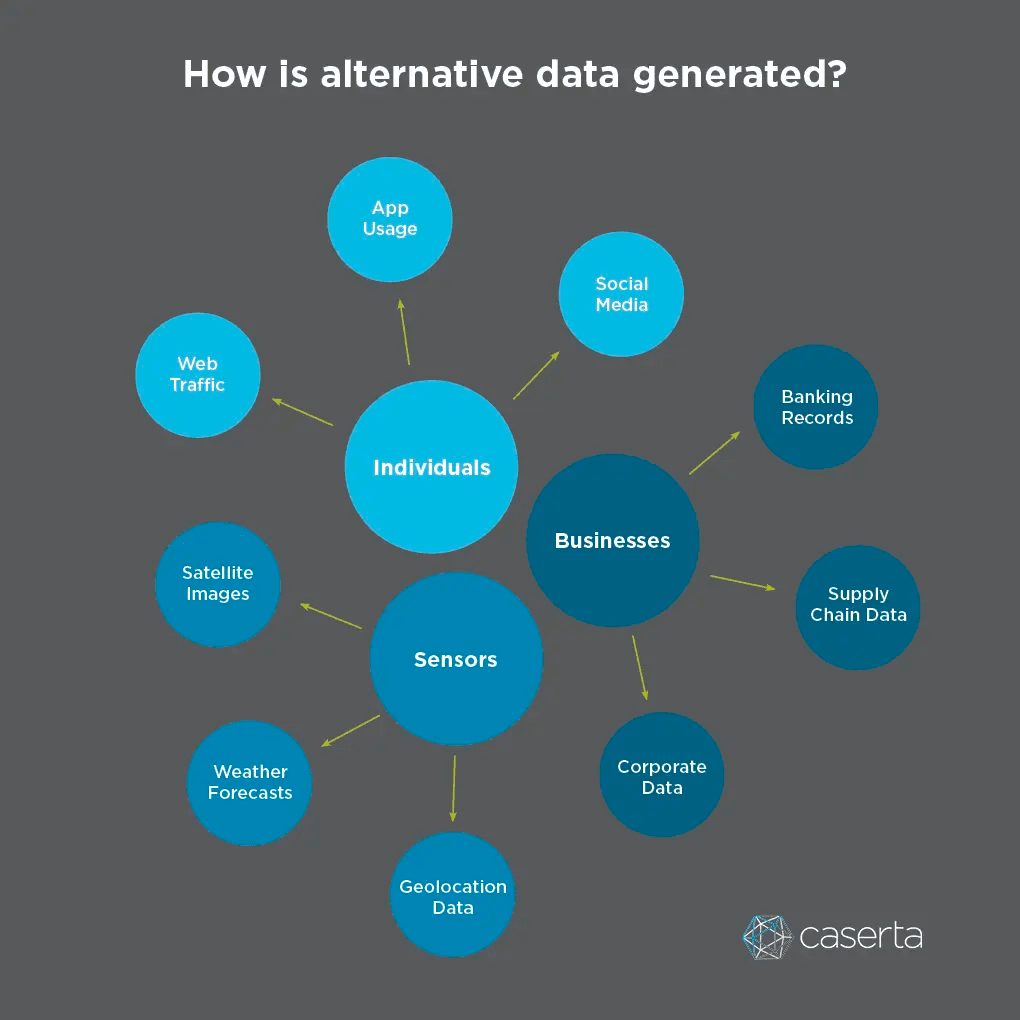
From this growing universe of alternative data, there’s one in particular gaining super-fast traction. The accelerated growth of text data has been identified as a valuable source of opportunities to gain insights. Think about it: Text data includes text from social media, consumer reviews, news, documents, and even media formats like video and audio files. We’re surrounded by this type of data, and they carry precious amounts of information.
But how can we decode the information integrated in text data? Text data is highly unstructured, which means it doesn’t have a predefined format. Although this has always been a problem for analytical and predictive models, modern AI solutions are capable of processing this type of data effectively. There’s only one caveat. For models to be effective, they have to deal with another important characteristic of text data: its high dimensionality.
The problem of high dimensionality
Data dimensionality refers to how many attributes a dataset has, and high dimensional data is characterized by having multiple dimensions. How many? There can be hundreds, thousands, or millions of dimensions in a single dataset. A sample of thirty-word Twitter messages that use only the one thousand most common words in the English language, for example, has roughly as many dimensions as there are atoms in the universe!
The Curse of Dimensionality is the name given to the problem of the exponential increase in volume associated with adding extra dimensions to the data space. High dimensional data brings all sorts of challenges, but there’s one in particular that deserves our attention: the problem of data sparsity. Sparsity of data occurs when moving to higher data dimensions, as the volume of the space represented grows so quickly that the data cannot keep up and thus becomes sparse.
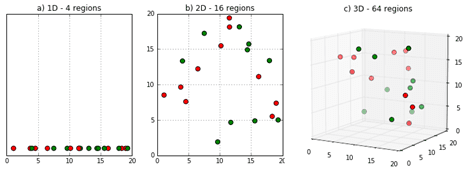
So how can we manage this complexity and discover insights in our current massive data volumes? The answer is: using vector embeddings.
What are vector embeddings?
Machine Learning models expect inputs as numbers, not words, images, or videos. In order for these models to extract patterns and make predictions, data has to be transformed into a vector first. Vector embeddings represent inputs like text as numbers, so that we can train and deploy our Machine Learning models for tasks like classification or sentiment analysis.
Vector embeddings are low-dimensional representations of high-dimensional data. Typically, a standard vector won’t capture all information contained in the original data, but a good vector embedding will capture enough to solve the problem at hand.
When we use vector embeddings as inputs, the main benefit is their ability to encode information in a format that our models can process and then output something useful to our end goal. In the case of text data, we can use vectors to represent the features we want our model to learn. This vectorization produces meaningful numerical representations for the machines, enabling them to perform different tasks.
This way, a text representation shifts from a sequence of words to points that occupy a vector embedding space. Points in space can be close together or far apart, tightly clustered or evenly distributed.
This vector embedding space is therefore mapped in such a way that words and sentences with similar meanings are closer together, and those that are different are farther apart. By encoding similarity as distance, we can begin to derive the primary components of texts and draw decision boundaries in our semantic space. Once words or sentences get represented as numerical vectors, you can perform mathematical operations with them like addition and subtraction. This is an amazing property of vector embeddings because it means that they carry important relational information that can be used in many different Natural Language Processing (NLP) tasks.
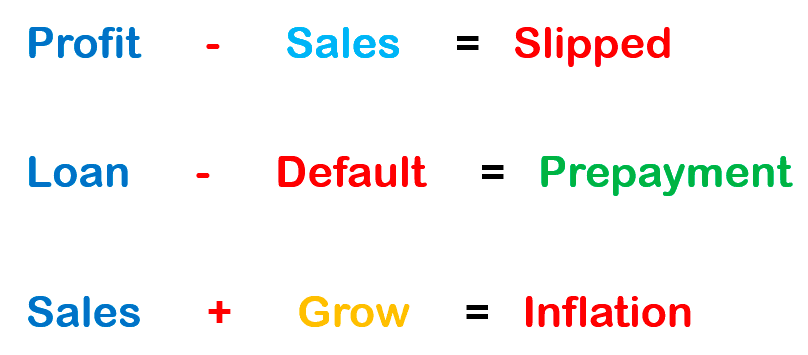
Different models including neural-net language models (NNLM), global vectors for word representation (GloVe), deep contextualized word representations (ELMo), and Word2vec are designed to learn word embeddings, which are real-valued feature vectors for each word.
Word embeddings built from a general corpus of sources like Wikipedia or Google News are widely available to use and provide acceptable results to solve general tasks. These are general purpose models, however, which need to be fine-tuned to the specific vocabulary if you want to increase your model performance. For example, it’s possible to redefine word embeddings by adding text from 10-K filings to improve results on tasks such as document classification, document similarity, sentiment analysis, or readability index.
Gain insights with vectorization
Extracting information from unstructured data can be of enormous value. Text from news, social media, and company filings and communications is used to predict asset price movements and study the causal impact of new information. Through vector embeddings, you can perform exploratory analysis and visualizations to derive insights and discover patterns.
News
More than 2 million articles are published every day on the web. That’s more than 1,300 per minute. How can you keep pace with them? One strategy is to automatically extract insights from these massive volumes using Machine Learning. Through vectorization, it’s possible to monitor news media in an automated fashion: from digital newspapers to video and audio channels. By embedding all data into the same vectorized space, we can perform searches and look for similarities between data sources that previously seemed dissimilar. News that contains useful information on companies and markets can be exploited for profits, no matter their original format.
Consumer sentiment
Through vectorization, it’s also possible to derive people’s sentiment. The idea behind it is to analyze pieces of content (e.g., documents, videos) to determine the emotional tone they carry, usually classifying them by positive, negative, or neutral. The goal? To understand attitudes towards a topic. This is a highly used resource by companies that want to get insights on their customers, through the analysis of reviews, conversations, and posts on social media. Stock market investors also use customer sentiment to anticipate potential market trends.
Financial data companies like Moody’s have integrated these concepts to develop a Credit Sentiment Score that compiles adverse credit signals from news articles, backed by extensive research and state of the art NLP, text analytics, and Machine Learning techniques. This score helps firms assess credit in the loan origination and portfolio risk monitoring process and track unfavorable media. The higher the score, the stronger the credit distress signal.
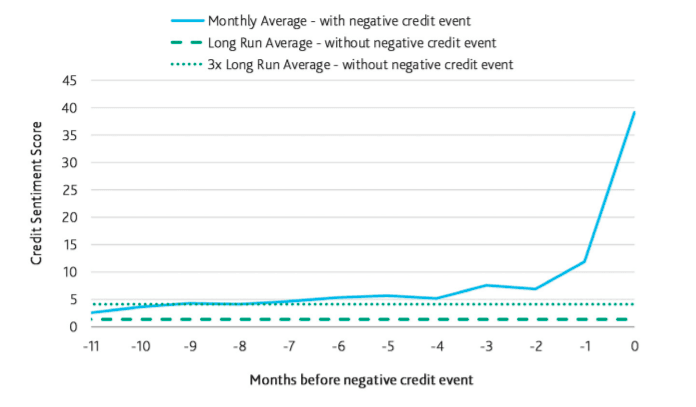
Standard & Poors (S&P) is another company exploiting the benefits of vector embeddings. They launched Textual Data Analytics (TDA), a sophisticated data offering which applies NLP to generate sentiment scores and behavioural metrics based on company transcripts. This solution allows to incorporate more qualitative measures of company performance into investment strategies by quantifying sentiment and behaviour during company calls.
Better data interaction
Besides allowing us to create target solutions, vector embeddings also allow you to interact with the data in a much easier way.
What if you could ask questions to your data like you would ask a human being?
Solutions like Spawner AI enable you to ask questions about financial instruments and get back natural language answers. You can ask all sorts of questions about income statements, balance sheets, and cash flows. Instead of using query languages, why not ask “What is the revenue of General Electric”?
What the future looks like
Sectors beyond finance are paying strong attention to the value of alternative data. Decision makers across all industries are demanding more actionable insights before making inferences about what actions to take. To fill this need, lots of companies have been fast enough to gather, clean, analyse, and interpret useful data from non-traditional sources.
Today more than ever, alternative data can give insights that traditional data cannot. Additionally, mobility and smartphones have brought wide possibilities: all cell phone apps are rich sources of data that can be used while we circulate and interact with the physical world.
But how can we make sense of all these data sources to get insights? It’s estimated that nearly 90% of today’s data is unstructured, and this massive volume will only keep growing. But since unstructured data can’t be easily processed or stored in traditional databases, we need to think about different strategies.
Whether you’re dealing with numeric data, text, images, sounds or rich media, everything can be vectorized into the same space, and the semantic similarity of these objects and concepts can be quantified by how close they are to each other as points in this vector space. Vectorizing unstructured data can allow us to store that information in a much more efficient way and use it to feed Machine Learning models for clustering, recommendation, or classification tasks. Machines only process numbers, and vectorization is an effective way to translate our highly diverse data sources into a language that machines can understand.
Was this article helpful?