As demand grows for better search results and recommendations, the path to better search applications is through AI, specifically vector search. Last year, we launched Pinecone to make it easy for developers to build high-performance vector search applications — at any scale and without infrastructure hassles.
Today I’m excited to announce we raised $28M in Series A funding. This investment, along with our rapidly growing number of users and customers, is an undeniable testament to what we believed from day one: The future of search is vector search. And the future of vector search is Pinecone.
I’d like to share how we got here and where we’re headed. It all started in the year 1200…
Search from 1200 AD to Today
In the 13th century, close to 200 years before the invention of the printing press, the cardinal Hugh of Saint-Cher created the first concordance of the Latin Bible by listing important keywords along with the page or passage numbers where they appear.
It would seem that search technology has changed a lot since then — we have modern indexing and ranking methods, with databases that can store and search through billions of records in milliseconds. And yet the core idea hasn’t changed: Eight centuries after the Concordantiae Sancti Jacobi was penned, search technology still revolves around keywords.
In recent years, advancements in AI/ML have made it possible to capture the meaning of any data in a machine-readable format called vector embeddings. That opened the door to vector search, a revolutionary information-retrieval method that searches through data using meaning and not only keywords.
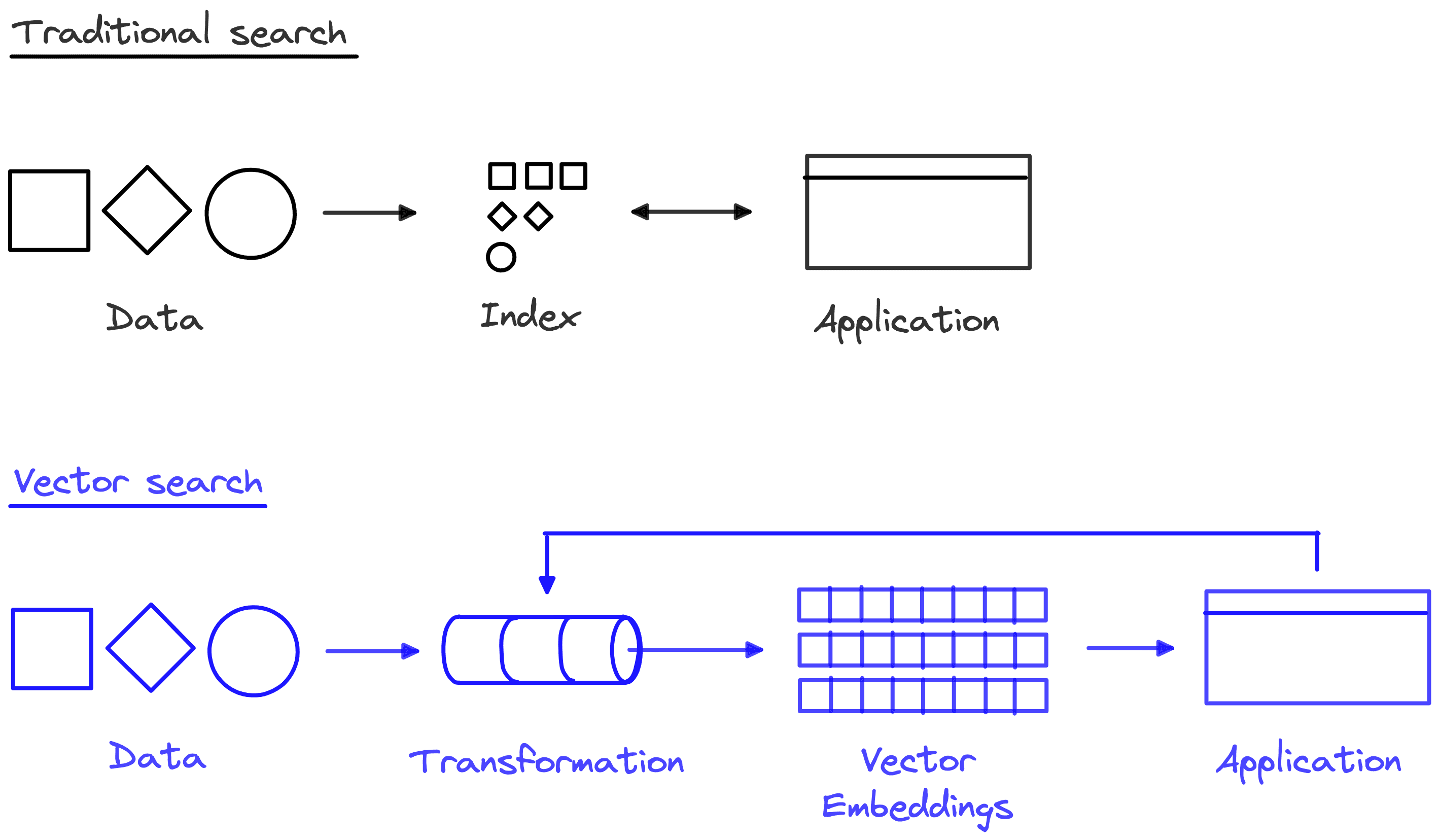
The biggest tech companies have already adopted this technology. When you search on Google, get recommended products on Amazon, and read relevant stories on your Facebook feed, you see vector search in action.
It’s no coincidence this revolution started at the largest, most advanced tech companies: Leveraging vector search inside large-scale and high-performance applications requires a new kind of infrastructure to be built and maintained, along with extensive engineering and data science work. In other words: It’s hard.
Enter Pinecone
We founded Pinecone to make it easy for engineers to build vector search applications. That meant creating a completely new kind of infrastructure and indexing algorithm, standing it up as a managed service, and exposing it through a simple API. We needed to call it something, so we came up with “vector database.”
Since launching in 2021, we:
- Released new features such as real-time index updates and single-stage filtering.
- Released a new REST API built using the OpenAPI standard.
- Made significant performance and scalability improvements to the core engine.
- Launched a vector-search community and the Pinecone Pioneers program.
- Invested in educational materials about vector search, including a free online course on NLP for semantic search.
- Tripled the size of our team, including Ram Sriharsha who joined as VP of Engineering after holding the same position at Splunk.
- Released a free plan for experimentation and small applications, and scalable usage-based plans for everyone else.
- Onboarded thousands of users, ranging from fast-growing startups to Fortune 500 companies.
The impact has been astounding. Engineering teams of all sizes and machine-learning skill levels — are already running vector search in production thanks to Pinecone.
To give a few of my favorite examples: Pinecone powers the semantic search inside Mem to help people stay organized, the alert management at Expel to protect cloud infrastructure, the file search at Searchable to make teams more productive, and the feed ranking inside a major social app to bring people together.
We have now crossed another milestone by raising $28M in Series A financing, led by Menlo Ventures with participation from new investor Tiger Global and previous investors, including Wing Venture Capital. Tim Tully, Partner at Menlo Ventures and former CTO of Splunk, will join the board of directors.
I first met Tim when we worked at Yahoo, where where he led the data organization and media properties. Since then he has led multiple engineering organizations (including Splunk) and advised some of the fastest-growing cloud infrastructure startups. He is the most technically experienced investor I know, with an exceptional understanding of the AI and data infrastructure space. I couldn’t have asked for a better partner to join us on this journey.
The Future of Search
We’re on a mission to build search and database technology for the AI age. In the near term, that means two things: First, we must make it incredibly fast and easy for developers to use vector search applications, regardless of their experience with machine learning. Second, we must push the boundaries of vector search to provide faster and more relevant results at any scale.
To that end, we’re investing even more in product and engineering, developer advocacy and customer success, and core research into machine learning, natural language processing, and information retrieval. That includes growing an incredibly talented and ambitious team in those areas. If this sounds exciting to you, join us!
Was this article helpful?