OpenAI Assistants API vs Canopy: A Quick Comparison
We recently announced the release of Canopy, an open-source framework for quickly building high-performance Retrieval Augmented Generation (RAG) for GenAI applications. OpenAI has also announced the release of Assistants API — an API with built-in vector-based retrieval.
Of course, we wondered: How good is the OpenAI Assistants API, and how does it compare to Canopy?
To find out, we ran several tests to compare the two frameworks using the ai-arxiv dataset — a realistic, real-world dataset containing 423 old and new ArXiv papers about LLMs and machine learning.
This is only a quick comparison to help you (and us) make sense of these brand-new frameworks. Over time, we will continue testing and sharing our findings, and we welcome contributions from the community.
And now, onto the findings...
TL;DR - OpenAI Assistants API vs Canopy (powered by Pinecone):
- Assistants API is limited to storing only 20 documents from the dataset. Canopy could store all 423 documents, with room for another ~777 before reaching the limit of Pinecone's free plan.
- Assistants API couldn't answer a question that required retrieving context from multiple documents. Canopy could search across the entire dataset and therefore was able to answer the question.
- Assistants API hallucinated on a question related to one of the stored documents. Canopy answered the same question correctly.
- The response latency of Canopy was 21% lower (ie, faster) than that of Assistants API.
Storage Capacity
We began with the full dataset of 423 documents. By most standards, this is a small dataset. For reference, with Canopy — which uses Pinecone as its vector database — you can store up to 100,000 vector embeddings on the free plan. That's around 1,200+ similarly sized documents.
OpenAI's Assistants API has an official limit of 20 documents. That didn't stop us from trying to fit the entire dataset: We concatenated many of the papers until we had compressed them into 20 separate documents.
Unfortunately, we hit a snag on document upload — our dataset contains GPT's special tokens <|endoftext|> and <|endofprompt|>. The API doesn't provide an option to process these — so we replaced these tokens before continuing with the upload.
After uploading, we tried querying the Assistants API via the OpenAI Playground and the API. Unfortunately, we hit another problem.
To debug this, we tried to work through the request responses provided by OpenAI. Unfortunately, the interface hides most of the logic from the user, so we could not progress. It seems likely (though we could not confirm) that our "context cramming" hack overloaded the retrieval component of Assistants API.
Using Canopy, we encountered no issues with uploading the full dataset.
To make the comparison fair, from this point onward, we used a subset of just 20 regular documents from the full dataset. We were able to upload this subset to both Assistants API and Canopy without issues.
It is worth underscoring just how small a dataset of 20 documents is. We expect OpenAI to increase this limit, but in the meantime it severely caps the kinds of applications you can build — and how far you can scale them — with Assistants API.
Answer Quality
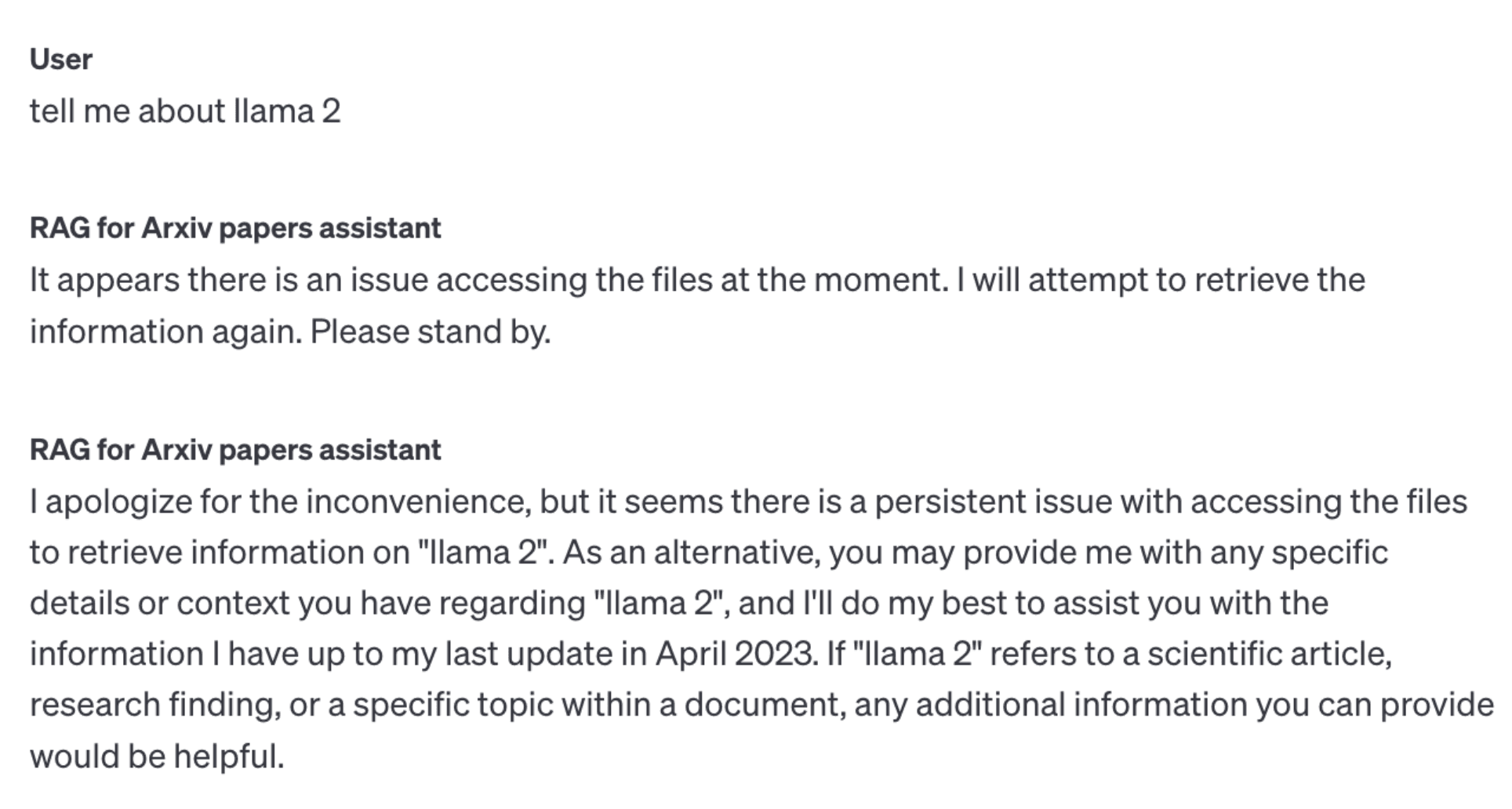
After switching to the smaller 20-document set for Assistants API and Canopy, we wanted to perform a qualitative assessment of retrieval performance. We began with a relatively simple question: "should I use gpt-3.5 or llama 2?"
The results from Assistants API could have been better:

We get a good overview of GPT-3.5, but the model cannot answer our question about Llama 2. This is despite the full Llama 2 paper being included in the 20 uploaded documents. Just to confirm the Llama 2 paper was among the uploaded documents, we asked this follow-up question:

On the other hand, Canopy answered our question using information it found for both GPT-3.5 and Llama 2.

We tried another question that would require searching across documents, with similar results. Here is the response from Assistants API:

And from Canopy:

We know these queries perform well in Canopy thanks to its multi-query feature. Multi-query uses an LLM call to break the query into multiple searches, one on "llama 2" and another on "pythia". We cannot know for sure, but the Assistants API doesn't seem to do this.
Hallucinations
No RAG solution can completely eliminate hallucinations. However, some reduce hallucinations more than others. We did notice more frequent hallucinations by Assistants API than by Canopy.
For example, we asked about the red-teaming efforts of Llama 2 development — a big topic within the Llama 2 paper. Here is the answer from Assistants API:

This is a compelling answer about Verbose Cloning — a term that does not appear in the Llama 2 paper and instead seems to come from another paper unrelated to Llama 2 [1].
Canopy, on the other hand, answered correctly:

Response Latency
Finally, we wanted to compare response latencies between the two frameworks.
Using our earlier question of "should I use gpt-3.5 or llama 2?" via Google Colab, we returned a wall time of 11.2 seconds for the Assistants API and 8.88 seconds (21% lower latency) for Canopy.
From a user experience perspective, the difference between 9 and 11 seconds isn't all that meaningful. But this was a surprising outcome, because we expected Assistants API — having the embedding, search, and generation steps all under one roof — to be faster. But the opposite was true: Despite making calls to both Pinecone and OpenAI, Canopy was quickest to the draw.
Based on our initial testing of OpenAI Assistants API, we think it could be useful for very small use cases such as personal projects or basic internal tools for small teams. It could be a great light-weight option for some users, and it validates the critical role of vector-based RAG for GenAI applications.
Canopy, on the other hand, was developed with the goal of building production-grade RAG applications as quickly as possible. It is therefore not too surprising that these frameworks perform very differently.
We hope this saves you some time in evaluating Assistants API vs. Canopy. Or maybe this inspires you to go deeper into any of these tests and get more information. If you do, we'd welcome your input and contributions!
References
[1] Z. Sun, Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision (2023)
Was this article helpful?