Introducing Canopy: An easy, free, and flexible RAG framework powered by Pinecone
We’re launching Canopy (V.0.1.2) to let developers quickly and easily build GenAI applications using Retrieval Augmented Generation (RAG). Canopy is an open-source framework and context engine built on top of the Pinecone vector database so you can build and host your own production-ready chat assistant at any scale.
From chunking and embedding your text data to chat history management, query optimization, context retrieval (including prompt engineering), and augmented generation, Canopy takes on the heavy lifting so you can focus on building and experimenting with RAG. As a fully open-source framework, you can easily extend or modify each component of Canopy to accommodate your use case.
Canopy uses the Pinecone vector database for storage and retrieval, which is free for up to 100K vectors (around 15M words or 30K pages of text) and can scale to billions of embeddings on paid plans.
Watch the demo video to see Canopy in action.
Transform your text data into a RAG-powered application in under an hour
With many components to manage (e.g. LLM, embedding model, vector database) and levers to pull (e.g. chunk size, index configuration), implementing a RAG workflow from scratch can be resource and time intensive, and is often hard to evaluate. And without a certain level of AI expertise, you can get bogged down by the trial-and-error that comes with designing and building a reliable, highly effective RAG pipeline.
With Canopy, you can get a production-ready RAG-powered application up and running in under an hour. And because it’s built and backed by Pinecone, you get the same great developer experience and performance of our fully managed vector database.
For developers wanting to get started and experiment with RAG, Canopy provides a solution that is:
- Free: Store up to 100K embeddings in Pinecone for free. That’s enough for around 15M words or 30K pages of documents. Free options for LLMs and embedding models are coming soon.
- Easy to implement: Bring your text data in plain text (.txt), Parquet, or JSONL formats (support for PDF files coming soon), and Canopy will handle the rest. Canopy is currently compatible with any OpenAI LLM (including GPT-4 Turbo), with support for additional LLMs and embedding models, including popular open source models from Anyscale Endpoints, coming soon. (Note: You can use our notebook to easily transform your text data into JSONL format.)
#create a new Pinecone index configured for Canopy
canopy new
#upsert your data
canopy upsert /path/to/data_directory
#start the Canopy server
canopy start- Reliable at scale: Build fast, accurate, and reliable GenAI applications that are production-ready and backed by Pinecone’s vector database.
- Modular and extensible: Choose to run Canopy as a web service or application via a simple REST API, or use the Canopy library to build your own custom application. Easily add Canopy to your existing OpenAI application by replacing the Chat Completions API with Canopy’s server endpoint.
- Interactive and iterative: Chat with your text data using a simple command in the Canopy CLI. Easily compare RAG vs. non-RAG workflows side-by-side to interactively evaluate the augmented results before moving to production.
#start chatting with you data
canopy chat
#add a flag to compare RAG and non-RAG results
canopy chat --no-ragGetting started with Canopy is a breeze. Just bring your data, your OpenAI and Pinecone API keys, and you’re ready to start building with RAG. Watch our demo.
Get started with Canopy’s built-in server or use the underlying library
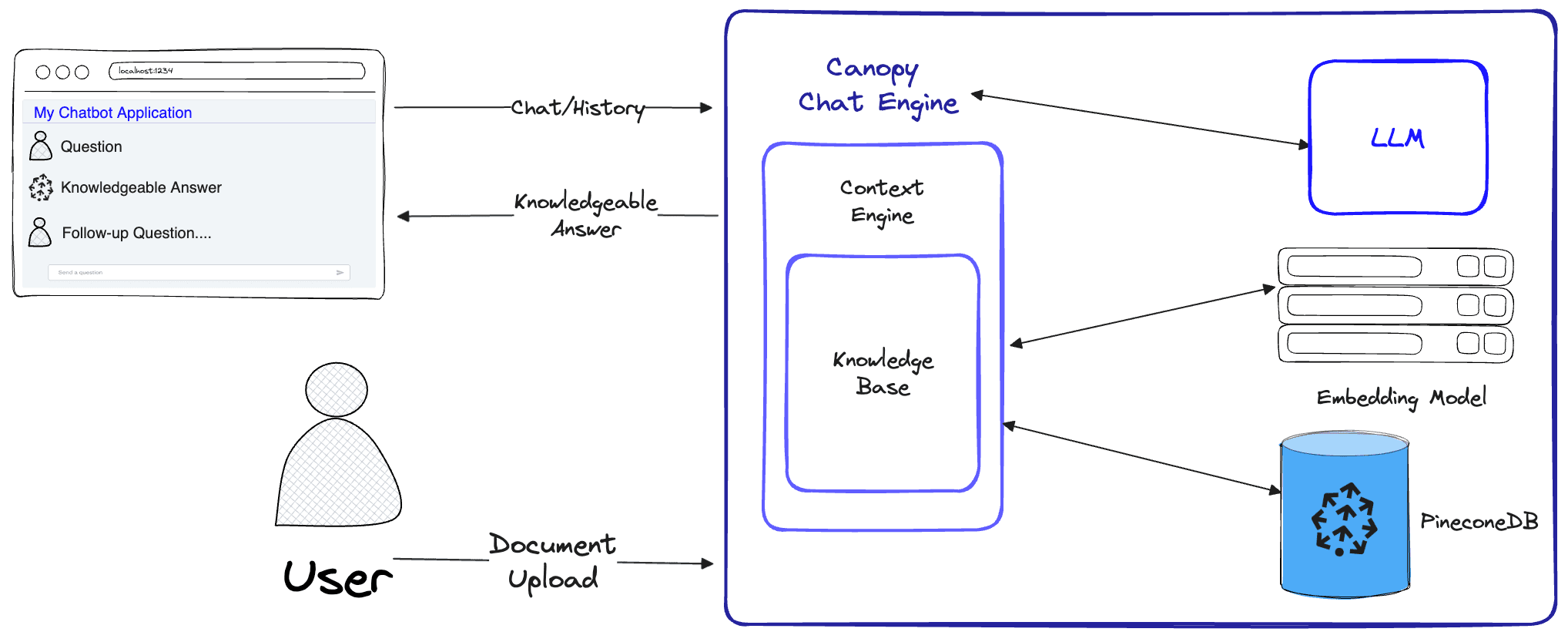
Canopy is packaged as a web service (via the Canopy Server) and a library so you can build your own custom application. The library has three components (or classes) which can be run individually or as a complete package. Each component is responsible for different parts of the RAG workflow:
- The Knowledge Base prepares your data for the RAG workflow. It automatically chunks and transforms your text data into text embeddings before upserting them into the Pinecone vector database.
- The Context Engine performs the “retrieval” part of RAG. It finds the most relevant documents from Pinecone (via the Knowledge Base) and structures them as context to be used as an LLM prompt.
- The Canopy Chat Engine implements the full RAG workflow. It understands your chat history and identifies multi-part questions, generates multiple relevant queries from one prompt, and transforms those queries into embeddings. It then uses the context generated for the LLM (via Context Engine) to present a highly relevant response to the end user.
Start building today
Canopy is now available for anyone looking to build and experiment with RAG. For Pinecone users, existing indexes are currently not compatible with Canopy so you will need to create a new index using Canopy to get started.
Future versions of Canopy will support more data formats, new LLMs and embedding models, and more. Star the Canopy repo to follow our progress, make contributions, and start building today!
Was this article helpful?