Understanding Hallucinations in AI: A Comprehensive Guide
Large Language Models (LLMs) like GPT 3.5, GPT 4, and LLaMa have gained significant interest over the past year. Existing and even entirely new products have been enhanced and developed thanks to LLMs, none of which were possible before the recent explosion of AI.
While LLMs are an incredibly powerful form of Natural Language Generation (NLG), they do suffer from several serious drawbacks:
- Decoding methods can generate output that is bland, incoherent, or gets stuck in repetitive loops.
- They have a “static” knowledge base that is not easily updated.
- They often generate text that is nonsensical or inaccurate.
The latter is known as hallucination. The terminology comes from the human equivalent of an "unreal perception that feels real".
For humans, hallucinations are sensations we perceive as real yet non-existent. The same idea applies to AI models. The hallucinated text seems true despite being false.
Hallucinations produce unwanted behaviors and, in extreme cases, can be genuinely dangerous. For example, with the use of NLG in medicine, a medical report containing highly convincing yet completely false information could lead to life-threatening treatments or lack thereof.
Other consequences may not be so dangerous, but serious issues can prevent the adoption of NLG and broader AI technologies. A paper submitted to NeurIPS (one of the most prestigious AI conferences) contained false yet convincing information and passed peer review [1]. Last February, Alphabet's Bard lost $100 billion in market value after their experimental chatbot wrongly answered a question on their Twitter promotional post.
In this article, we will dive into hallucinations and effective solutions for limiting them.
Example of Hallucinations
To explain the concept of hallucination, we are going to ask ChatGPT how to use the LLMChain in LangChain. Something ChatGPT (gpt-3.5-turbo-0301) cannot know about, as it was trained before the release of LangChain.
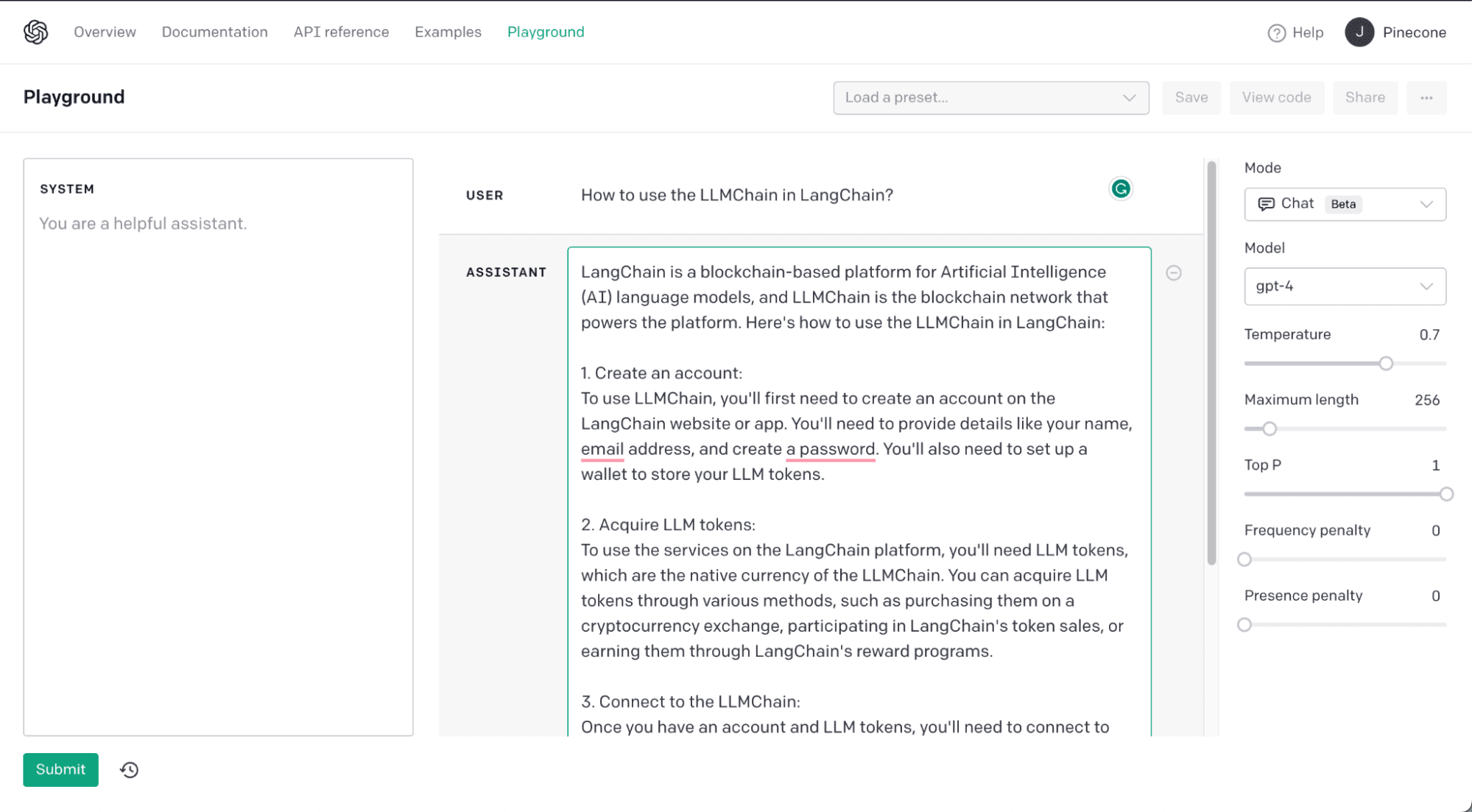
We can see how a completely false answer was generated. Indeed, LangChain has nothing to do with blockchain but is a framework built around Large Language Models (see this article to learn more about LangChain).
In this example, we expected false information, yet it was still convincing enough to double-check whether this information was factual. We found that, yes LangChain was a blockchain-based platform, but the remainder of the information about “LLM tokens” and connecting to the “LLMChain” are entirely false.
Unfortunately, most scenarios of hallucination are unlikely to be intentional and may go completely undetected by users who believe the hallucinated text.
Forms of Hallucination
There are two forms of hallucination in NLG [2]:
- Intrinsic hallucination — the generated output has manipulated information that contradicts source material. For example, if we asked, “Who was the first person on Mars” and the model told us “Neil Armstrong”, this would be a case of manipulated information as the model (almost certainly) knows he was the first person on the Moon, not Mars.
- Extrinsic hallucination — the generated output has additional information not directly inferred from source material [3]. Like the “LLM tokens” in our earlier example, there is no evidence in the source material of their existence, yet, the model has told us that they do exist.
In short, intrinsic hallucination is where input information is manipulated, and extrinsic hallucination is where information not in the input is added.
Source material varies by task. In abstractive summarization, we have the input text to be summarized acting as our source, i.e. we rely on source knowledge. In GQA, the source material is typically all knowledge, i.e. world knowledge [3] learned by the model during training.
Because of this difference in the definition of source material, hallucinations in some tasks do not constitute hallucinations in others. For example, in summarization, if a model includes knowledge learned during training ("world knowledge") that was not included in the text to be summarized (“source knowledge”), this would be extrinsic hallucination. If the same happened during GQA and the model used its "world knowledge" to answer a question, this would not constitute hallucination.
See the ‘Nomenclature’ section for the definition of world, source, and parametric knowledge.
Other important terms connected to hallucinations are "factuality" and "faithfulness". The generally accepted definitions of these terms are:
- Factuality is defined as the alignment of generated text to world knowledge.
- Faithfulness is defined as the alignment of generated text to source knowledge. It is the opposite of hallucinations. When we reduce hallucination, we increase faithfulness.
Sources of Hallucination
To reduce hallucination, we must understand why models hallucinate. Primary factors are listed below:
- Imperfect representation learning — the encoder of language models is responsible for encoding human-readable input text into machine-readable, meaningful vector representations. If the encoder misunderstands the input text, it will create a misleading vector representation that misleads the model decoder (which generates text output).
- Erroneous decoding — the decoder of language models is responsible for taking the meaningful vector representations and decoding them into generated human-readable text. Injecting more randomness (i.e., increasing temperature) into the decoding process generates more creative but more unexpected and potentially hallucinatory outputs.
- Exposure bias — the training method of typical generation models consists of predicting a sequence of tokens based on ground-truth (i.e. real) input text. During inference, this is no longer the case. The initial generations use ground-truth input text, but subsequent generations use the synthetic text the model generates. Because of this “synthetic generation based on synthetic input”, we may see degradation in the quality of the generated text. It is akin to a system becoming increasingly random and chaotic over time.
- Parametric knowledge bias — the use of ever larger language models results in models memorizing more knowledge stored during training within the model parameters, acting as a model's "memory". This parametric knowledge benefits many downstream tasks but naturally leads to hallucination in tasks where we'd like the model to rely more or entirely on source knowledge.
In all of these examples, the source of hallucination is either:
- Hallucination from input data (source knowledge), or
- Hallucination from training (parametric knowledge).
In the first case, any input text at inference time might contain contradictory information, confusing the model. In the second case, errors might arise during training, such as a bias generated during the encoding process due to poor representation learning, an error from the model's decoding process, or an exposure bias deriving from generating text based on previously generated historical text.
How to Reduce Hallucination
The hallucination problem can be partly addressed using different approaches:
- Improving the training and inference data inputs, or
- Improving the model, again during training and inference.
(1) Data-Related Methods
Using Faithful Data
One of the strongest solutions is building a faithful dataset. Many researchers have used hallucination evaluation metrics to measure and rank the training data based on their level of hallucination. These metrics allow us to automatically "clean" the data by removing the lowly ranked samples [4] [5].
Using Source Knowledge
In many scenarios, we may want our model to use source knowledge as its source of truth. Unfortunately, this is where we will experience parametric knowledge bias.
Parametric knowledge bias is a big problem with increasingly larger LLMs. As model parameters increase, the strength of their parametric knowledge against source knowledge becomes significantly imbalanced.
However, given the correct prompts, we can enforce more strictness in the data that the model uses. Take this example:
Weak prompt:
"Since 2022 penguins are green.
Question: What color are penguins?
Answer:"
Generated text:
"Penguins come in a variety of colors but often consist of a black coat with white belly."
---
Strong prompt:
"Answer the question below using the information contained in the context as the ground truth.
Context: Since 2022 penguins are green
Question: What color are penguins?
Answer:"
Generated text:
"Penguins are green."In our weak prompt, the source knowledge of "Since 2022 penguins are green" is ignored by the model, as it has already learned that this is not true during model training; its parametric knowledge bias is too strong against our weak prompt.
In the strong prompt, we explicitly demand the model to use the context as the source of truth. Because of this more strict language, the model understands that it must use the source knowledge given in the context.
All of this is great, but we still have a problem; if no context is given to the model, it can rely only on its parametric knowledge, which could be outdated or simply not contain the information we need.
How can we ensure that relevant context(s) are attached to each query? For this, we must use an external knowledge base with a retrieval mechanism that can find relevant information based on a query.
We refer to this as retrieval augmentation. It is a popular choice encouraged by tools like LangChain, the ChatGPT Retrieval Plugin, and the OP stack. The idea is to implement an external knowledge base to provide relevant source knowledge to help us beat the aforementioned parametric knowledge bias.
To implement this, we can use the Pinecone vector database. A vector database stores vector representations of text (or other information) and allows us to retrieve records based on their vector similarity — vector similarity is equivalent to human “semantic similarity”.
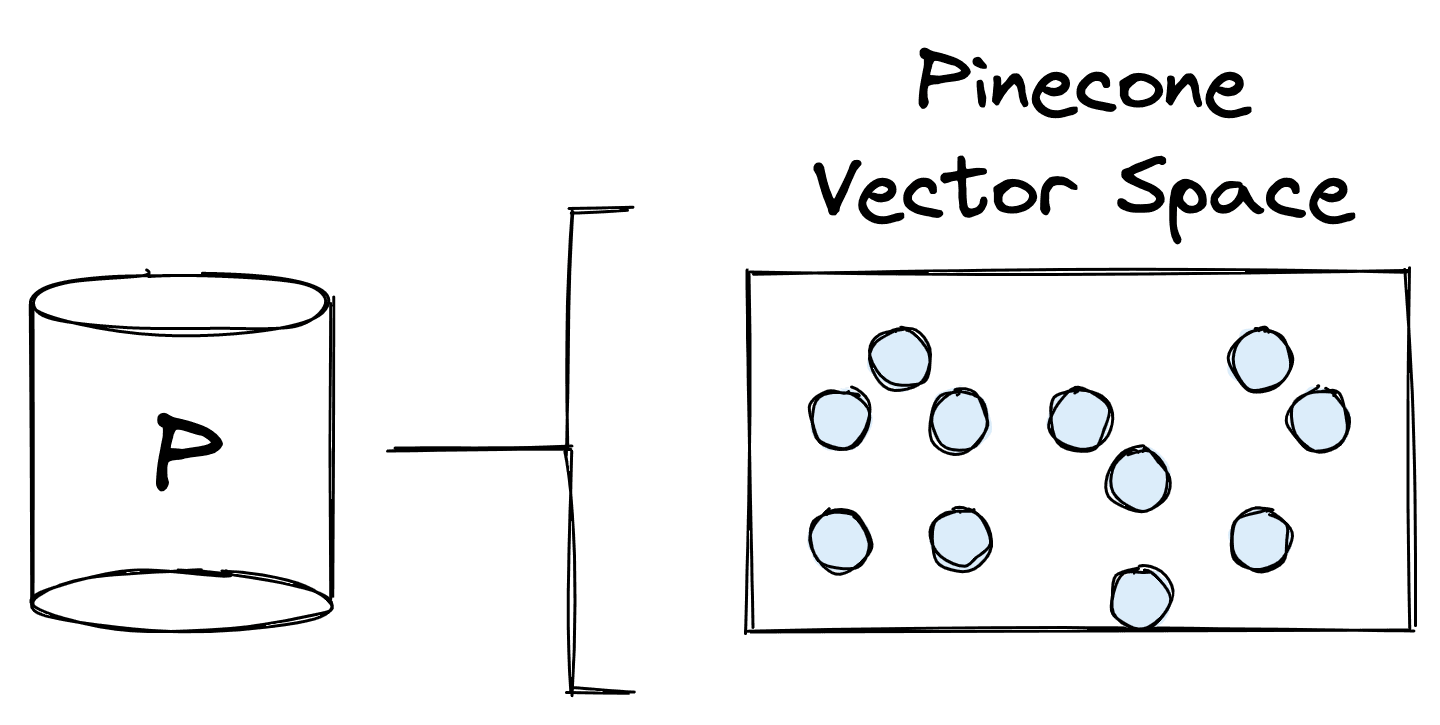
Using an embedding model to create these vector representations, we can encode text with similar meanings into a similar vector space. How? We can search using a "query vector", typically built using the same embedding model. We can then input the query vector into Pinecone to identify semantically similar embeddings to our query.

These semantically similar embeddings can be mapped back to the text that created them, and this text is returned as source knowledge (often called contexts) for our generation model (LLM).
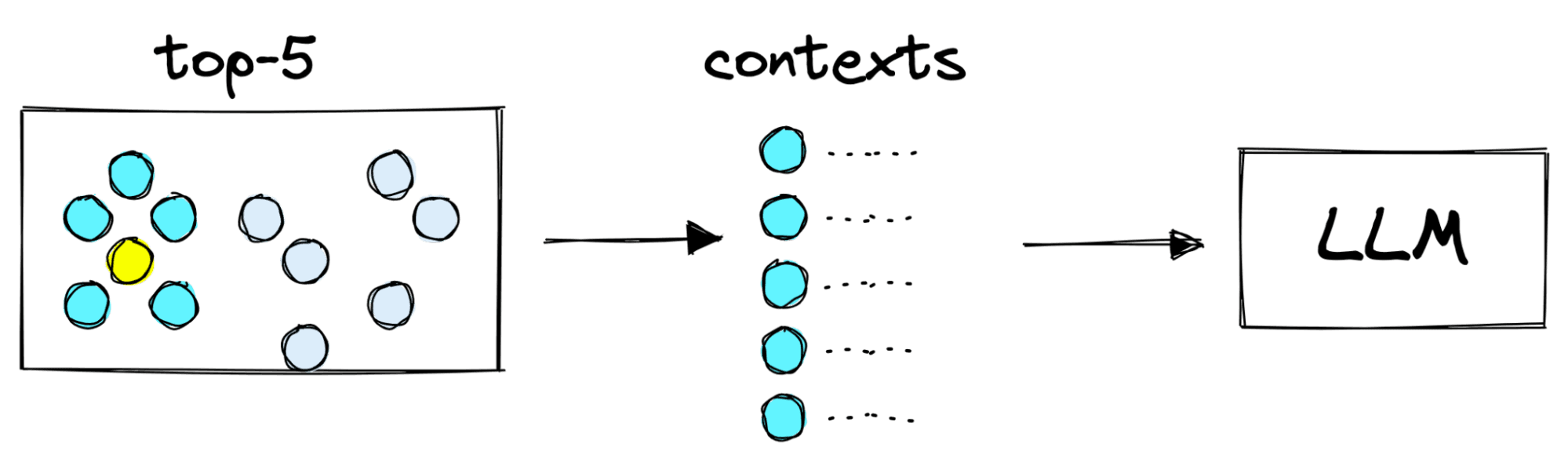
From here, we merge our strict prompt with these contexts and the user query. With our retrieval augmented input, a good LLM can often answer questions with high accuracy, even when it has not been trained on that specific data or topic.
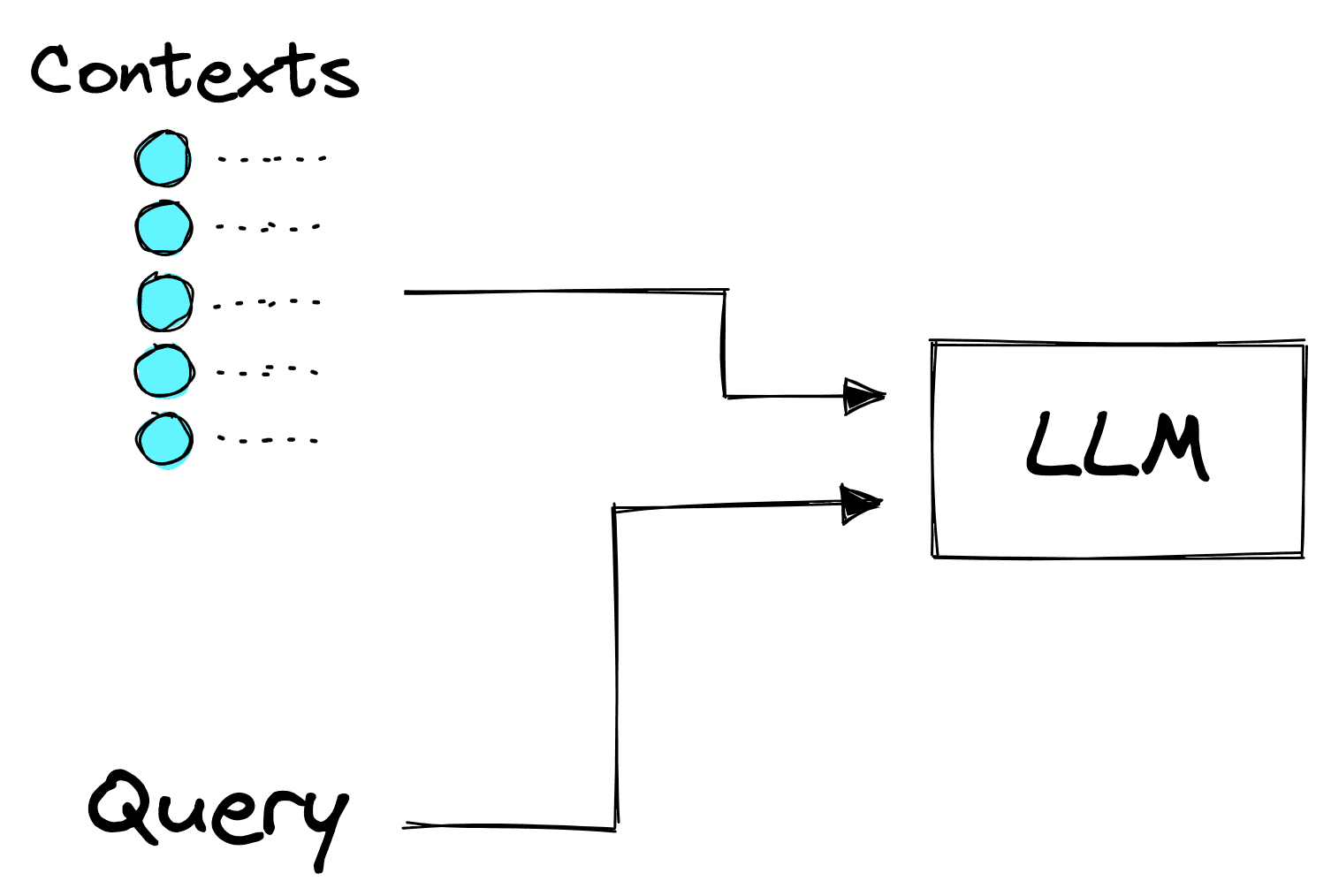
We can visualize this method, choosing to retrieve the top five most relevant contexts to augment our prompt like so:
You can implement the same using the code here.
Discouraging Guessing
LLMs love to guess answers and hate admitting they don’t know something. That’s a problem for us. Even if we include a strong prompt to rely on source knowledge and integrate that source knowledge, if we don’t return relevant information, how can we be sure the LLM won’t make something up?
# system message to 'prime' the model
primer = f"""You are Q&A bot. A highly intelligent system that answers
user questions based on the information provided by the user above each question. If the information can not be found in the information provided by the user you truthfully say "I don't know".
""""
res = openai.ChatCompletion.create (
model="gpt-4"
messages=[
{"role": "system", "content": primer},
{"role": "user", "content": augmented _query}
]
)One approach is to tell the LLM, "If the answer can not be found in the information provided by the user, you truthfully say "I don't know". This doesn't fix the hallucinations problem, but it helps.
We can see similar behavior in tool usage of LLM agents. LLMs are typically bad at math, but they will try and solve any math problem given to them. A common approach to fixing this is giving an LLM access to an external calculator tool. Still, LLMs are overconfident and need instructions that tell them, “You cannot do the math and should never attempt it, instead, use your calculator tool”. With this, they often stick to using their calculator tools.
Using these instructions that define the limits of what an LLM should generate is very important to limit hallucination.
(2) Modeling Methods
A common approach to reduce hallucination is to enhance the model architecture, i.e., modeling methods.
Many authors have enhanced the encoder to align it with the input characteristics. [8] [10] This would improve the encoder learning process and vector representation.
Others have integrated attention mechanisms [11] [12] [13], modified the decoder, [14] [15] [16], or even added rule-based output parsing.
Let’s see some examples.
Temperature Sampling
Generative LLMs consist of an encoder step to create the vector representations of some input. These representations are then used to generate the output text of the model using a decoder.
In this decoder step, we can use temperature sampling to reduce repetitiveness and generate more "interesting" results — increasing generation diversity [6].
Unfortunately, increasing generation diversity through sampling correlates with increased hallucination, leading to "erroneous decoding". The reason is that the generated output is randomly selected from a top-k number of most likely results rather than picking the top most probable result, which is often more faithful to the source material.
We used the OpenAI playground platform to test results using different combinations of temperature sampling, which can be adjusted using the temperature slider.
Consider our query: "Was Neil Amstrong the first man on the moon?"
Let’s first consider a high-temperature sampling, or temperature = 1. Results for different values of “Best of” will vary as we have some randomness in results:
- Best of = 1: Yes, Neil Armstrong was the first man on the moon. On July 20, 1969, he famously said, "That's one small step for man, one giant leap for mankind" as he took his first steps on the moon.
- Best of = 3: Yes, Neil Armstrong was the first man on the moon. He was part of the Apollo 11 mission, which was the first manned mission to the moon in 1969.
- Best of = 5: Yes, Neil Armstrong was the first man to set foot on the moon on July 20, 1969.
Now, let’s reduce the temperature sampling to zero, i.e., remove randomness (temperature = 0). In this case, we’ll note that results for different values of “Best of” are the same because results are now deterministic (not random):
- Best of = 1: Yes, Neil Armstrong was the first man to walk on the moon.
- Best of = 3: Yes, Neil Armstrong was the first man to walk on the moon.
- Best of = 5: Yes, Neil Armstrong was the first man to walk on the moon.
Our experimentation on the OpenAI playground platform demonstrated how adjusting the temperature slider affects the outcomes when answering a query about Neil Armstrong's role in the moon landing. Higher temperatures resulted in more diverse responses while reducing the temperature to zero made the results deterministic and consistent across different "Best of" values. The choice of temperature sampling should strike a balance between generating diverse outputs and maintaining accuracy and coherence with the given context.
(3) Inference Methods
Hallucination problems can also be reduced through inference methods, such as post-processing.
Post-processing methods can correct hallucinations identified in the generated output.
This approach is typically used in abstractive summarization and text generation tasks.
In abstractive summarization, the output can be corrected using the knowledge learned from a QA model, which checks the output faithfulness [7].
In text generation, we can use various methods depending on our intended output. For example, if we generate JSON output, we could use a JSON output parser from LangChain to check and fix output JSON syntax when needed.
Conclusion
Hallucinations are still an unsolved problem in Natural Language Generation (NLG).
As Large Language Models (LLMs) become increasingly prevalent in all facets of society, we will undoubtedly see hallucinations have real-world consequences.
Although we’re far from having a complete solution to the problem of hallucinations, we can make the best of what is currently available, such as the Data, Modeling, and Inference methods discussed. With those, we can limit hallucinations to becoming an increasingly rare occurrence in the new world of AI.
References
[1] M. Harrison, Researchers Reveal That Paper About Academic Cheating Was Generated by ChatGPT (2022), Futurism
[2] Z. Ji, et al., Survey of Hallucination in Natural Language Generation (2022), ACM
[3] J. Maynez, et al., On Faithfulness and Factuality in Abstractive Summarization (2020), ACL
[4] T. Liu, et al., Towards Faithfulness in Open Domain Table-to-text Generation from an Entity-centric View, (2021), Computation and Language
[5] L. Shen, et al., Identifying Untrustworthy Samples: Data Filtering for Open-domain Dialogues with Bayesian Optimization, (2021), Computation and Language
[6] C. Chang, et al., KL-Divergence Guided Temperature Sampling, (2023), Computation and Language
[7] Y. Dong, et al., Multi-Fact Correction in Abstractive Text Summarization, (2020), Computation and Language
[8] L. Huang, et al., Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward, (2020), ACL
[10] Z. Cao, et al., Faithful to the Original: Fact Aware Neural Abstractive Summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, (2017), Computation and Language
[11] A. Vaswani, et al., Attention is All you Need, (2017), Computation and Language
[12] R. Aralikatte, et al., Focus Attention: Promoting Faithfulness and Diversity in Summarization, (2021), ACL
[13] K. Krishna, et al., Hurdles to Progress in Long-form Question Answering, (2021), Computation and Language
[14] C. Rebuffel, et al., Controlling hallucinations at word level in data-to-text generation, (2021), Computation and Language
[15] Y. Xiao, et al., On Hallucination and Predictive Uncertainty in Conditional Language Generation, (2021), Computation and Language
[16] K. Song, et al., Joint Parsing and Generation for Abstractive Summarization, (2020), Computation and Language
Appendix A
NLG Methods
Abstractive Summarization
Abstractive summarization consists of extracting the most relevant information from source documents to generate a summary maintaining coherence and readability.
Dialogue Generation
With dialogue generation, the system generates answers to users’ questions based on an existing conversation.
Generative Question-Answering (GQA)
Generative question answering (GQA) involves understanding the question and generating a coherent and concise response that addresses the query.
Data-to-Text Generation
Data-to-Text Generation tasks consist of converting structured data, such as tables, database records, or graphs into human-readable text, providing explanations and summaries.
Machine Translation
Neural Machine Translation (NMT) involves generating accurate and fluent language translation capturing the meaning of the source text.
Nomenclature
Source knowledge: Information supplied to a model directly during inference, such as the input text to a summarization model.
Parametric knowledge: Information learned by the model during training and stored within the model parameters (weights).
World knowledge: Factual information about the world. This information has not necessarily been given as input to the model (source knowledge) nor learned by the model during training (parametric knowledge).
Was this article helpful?