
>600M
vectors stored
>$75k
annual savings
~10%
faster model-to-market cycle time
Patent litigation is a high-stakes environment. A single case can cost millions of dollars and hinge on whether attorneys can find the handful of historical documents, often buried among hundreds of millions of global patents and billions of academic papers, that prove a disputed invention already existed. This process, known as prior art search, determines the strength of a lawsuit and shapes litigation strategy.
Melange is a patent analytics company built to make this process faster and more reliable using large-scale semantic search. Their solution automates the most labor-intensive aspects of prior art discovery by embedding and retrieving hundreds of millions of documents across languages, formats, and jurisdictions. Their clients depend on Melange to surface the right set of 6–10 documents that could change the outcome of a lawsuit.
To deliver on that promise, Melange needed an infrastructure partner that could handle massive vector workloads at low cost without requiring the company to manage complex systems. When their self-hosted open source deployment hit scalability limits and began crashing under memory pressure, the team turned to Pinecone.
Scaling to hundreds of millions of documents without an infrastructure team
Before adopting Pinecone, Melange relied on a self-hosted Milvus cluster to power vector search across their patent and academic corpus. It worked, but not at scale. As they incorporated larger datasets and new models and tried to push the system beyond roughly 40 million records, it became unstable:
- Memory bottlenecks caused repeated crashes
- The team could not maintain reliable uptime on a serverless cost model
- Hosting their own always-on infrastructure would have required significant new spend
- They lacked the dedicated infrastructure staff needed to operate a production-grade vector database
In their business, partial data is unacceptable. Patent search requires full recall across global patent repositories and academic literature. Any missing document can undermine a case and the relationship with the client. When litigators demanded that Melange expand its dataset to their full global patent corpus (roughly 450 million records at the time), their home-grown solution could not run at all.
Melange evaluated various commercial and open-source vector stores but eliminated any vendor that lacked a serverless option or required managing infrastructure. Their evaluation included hosted alternatives such as Turbopuffer, but Pinecone’s recall statistics and hands-on support stood out as the most reliable path to achieving the completeness required for prior art search. At their scale, cost-efficient storage and usage-based compute were non-negotiable. They needed predictable reliability, high recall, and a solution that “just worked” so their engineers could focus on search quality and model innovation.
A serverless vector database optimized for large datasets, high recall, and low operational overhead
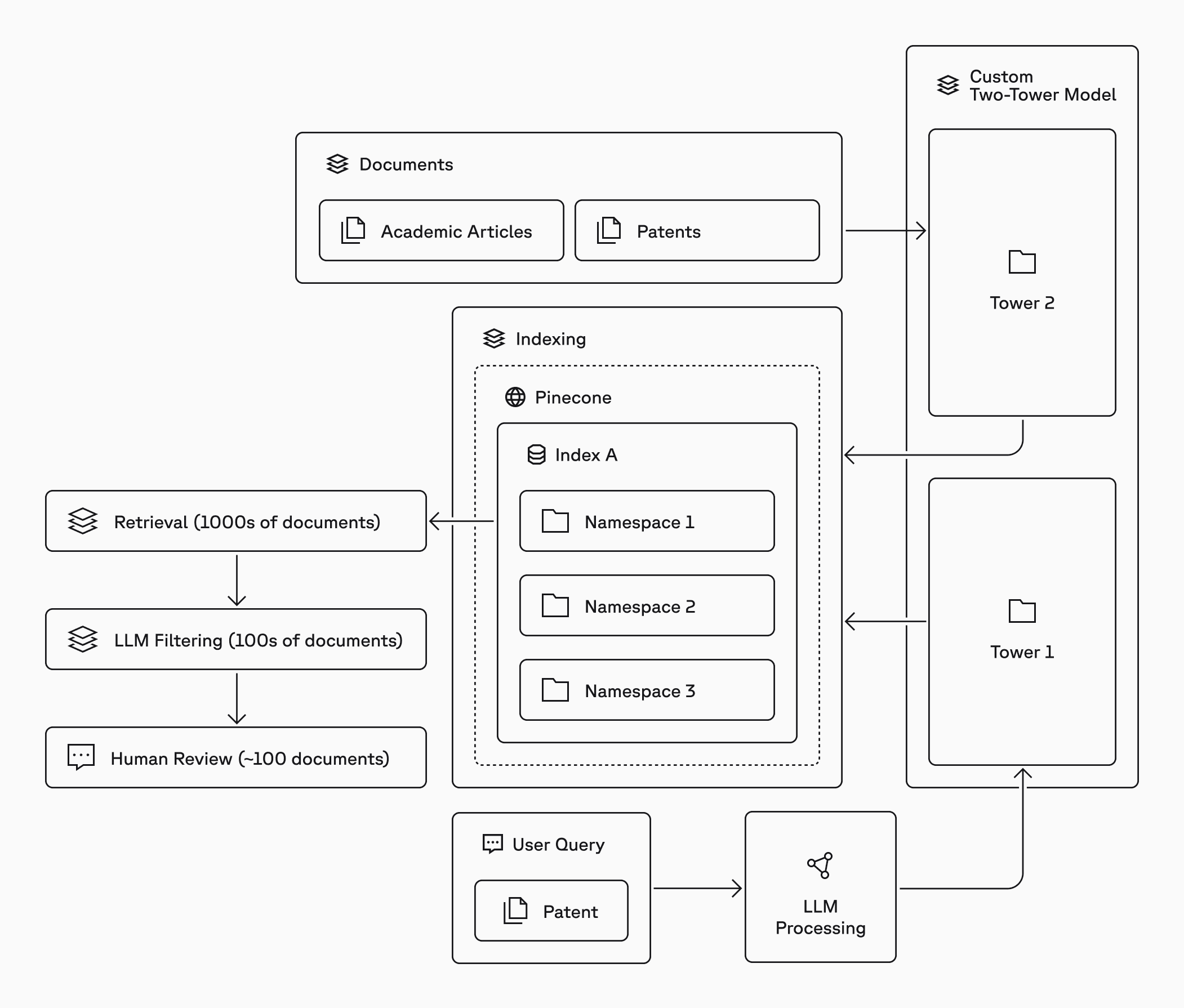
Melange’s workload—very large datasets paired with moderate query volume—creates a distinct set of requirements for reliability, cost efficiency, and recall. Pinecone’s serverless slab architecture meets those needs directly without requiring Melange to manage infrastructure or tuning complexity.
Decoupled storage and compute for large, cost-efficient datasets
Pinecone’s slab architecture separates long-term storage from query processing. This allows Melange to store hundreds of millions of embeddings at low cost while only paying for compute when searches are performed. For their workload, this approach reduces the operational work needed to maintain infrastructure.
The slab design also enables predictable performance. Data is stored in compact, immutable slabs that can be loaded, unloaded, and reorganized without affecting availability. This removes many of the memory bottlenecks Melange encountered when managing their own infrastructure.
High-recall retrieval across evolving datasets
Prior art search depends on completeness: if even one relevant document is missing, a case strategy can change. This requirement for high recall was a key reason Melange chose Pinecone over alternatives like Turbopuffer, whose recall characteristics did not meet their needs. Pinecone’s retrieval engine is built to support high recall at scale by maintaining stable index structures regardless of dataset size or update frequency. Slabs are optimized for efficient scan patterns, enabling consistent retrieval quality even as Melange introduces new models, new corpora, or new embedding strategies.
Because the system does not degrade as vector count grows, Melange can expand beyond patents into academic literature and other sources without redesigning their search stack.
Fast, reliable bulk ingestion using standardized pipelines
Melange uses Parquet-based bulk imports to load embeddings into Pinecone. This pattern aligns with Pinecone’s recommended ingestion workflow, which is optimized for large, static, or semi-static datasets. The slab architecture is designed to absorb these large writes efficiently: new slabs are created, validated, and indexed without interrupting queries on existing data.
This allows Melange to stand up new namespaces for model testing, run side-by-side comparisons, and introduce new generations of embeddings with little operational overhead.
Freshness and consistency for model iteration
As Melange experiments with custom embedding models, they need a system where new vectors can be ingested quickly and served consistently. Pinecone’s serverless design ensures that updated embeddings are accessible with predictable performance, and slab compaction ensures that queries always run against coherent, optimized index structures. The underlying architecture is designed to maintain predictable latency and recall even as datasets evolve.
This supports Melange’s workflow of generating embeddings externally, producing Parquet files, and loading new indices without manual tuning or index rebuild complexity.
Operational simplicity for a small engineering team
Pinecone abstracts away the complexity of cluster sizing, memory management, index maintenance, and failover—areas that previously consumed significant engineering time for Melange. With serverless infrastructure, the team does not need to maintain compute resources or monitor scaling behavior. They interact with Pinecone as an API rather than a system to operate.
For a company whose core value lies in search quality and domain expertise—not infrastructure—this reduces operational load and allows engineers to focus on building better models and analysis tools.
Our KPI for Pinecone is straightforward: how little time we spend thinking about it. Since we started, we haven’t had a single reliability issue, and that’s exactly what we need as a small team focused on building the product—not maintaining infrastructure — Joshua Beck, CEO at Melange
Saving money and time with reliable large-scale search
With Pinecone in place, Melange moved from a fragile 40M-record prototype to a production system spanning more than 600M vectors across multiple model generations. Their search pipeline now runs reliably at this scale without the crashes, memory failures, or operational overhead they experienced with their self-hosted deployment.
The stability of the system has become a core part of Melange’s workflow. Pinecone serves as the entry point for every search, enabling the team to process global patent and academic corpora with consistent recall and predictable performance. Melange’s engineers can now focus on model development and search quality rather than infrastructure tasks.
Our entire search operation relies on Pinecone as the first step in the process. When we evaluated the developer experience and time saved, Pinecone was far and away the clear winner. Being able to generate files in the cloud and import them seamlessly with guaranteed enterprise support was exactly what we wanted. We knew the biggest thing for us was spending as little time as possible on the vector database problem and Pinecone makes that possible. — Joshua Beck, CEO at Melange
Significant cost and time savings
Melange estimates that Pinecone saves them approximately $75,000 per year across avoided infrastructure maintenance, reduced operational burden, and less engineering time spent troubleshooting database issues. Because Pinecone requires minimal involvement from their team, Melange can ship improvements to their search models faster, reducing model-to-market cycle time by weeks.
Faster iteration across multiple models
As Melange trains and tests new embedding models, they can stand up new namespaces and run comparisons without managing clusters, tuning memory, or rebuilding indexes. A workflow that previously required significant setup and troubleshooting now takes only hours or less. This allows Melange to experiment with new model architectures and data sources with greater frequency.
Predictable performance at scale
Even as their dataset has grown to hundreds of millions of vectors, Pinecone has maintained stable recall and predictable performance. This consistency has been essential for Melange’s customers, whose cases depend on the system’s ability to surface the full set of relevant prior art without degradation as the corpus expands.
Millions at Stake: How Melange's High-Recall Retrieval Prevents Litigation Collapse
Adding more (and larger) models to Pinecone
Melange plans to expand its use of Pinecone as their corpus and modeling strategy grow. They expect to operate multiple custom embedding models in parallel, including ensemble approaches that combine the strengths of different representations. As their case work increases, Melange will be able to seamlessly increase their total vector count well beyond current levels.
They also plan to incorporate additional data modalities, including patent drawings and other visual information, and embed those alongside textual data in Pinecone. The team expects to continue using Parquet-based ingestion to test new model generations quickly and refine their system without added infrastructure work.
Pinecone’s serverless architecture makes these expansions straightforward. Melange can generate new embeddings, stand up new namespaces, and evaluate updated models using the same workflow they rely on today.