What happens in your brain when you see someone you recognize?
First, the rods and cones in your eyes record the light intensity. Those signals then travel to the visual cortex in the back of your head, where they activate neural cells through several layers in your visual cortex. In the end, you have millions of neurons activated in varying intensities. Those activations are transmitted to your temporal lobe, where your brain interprets as: “I see Julie.”
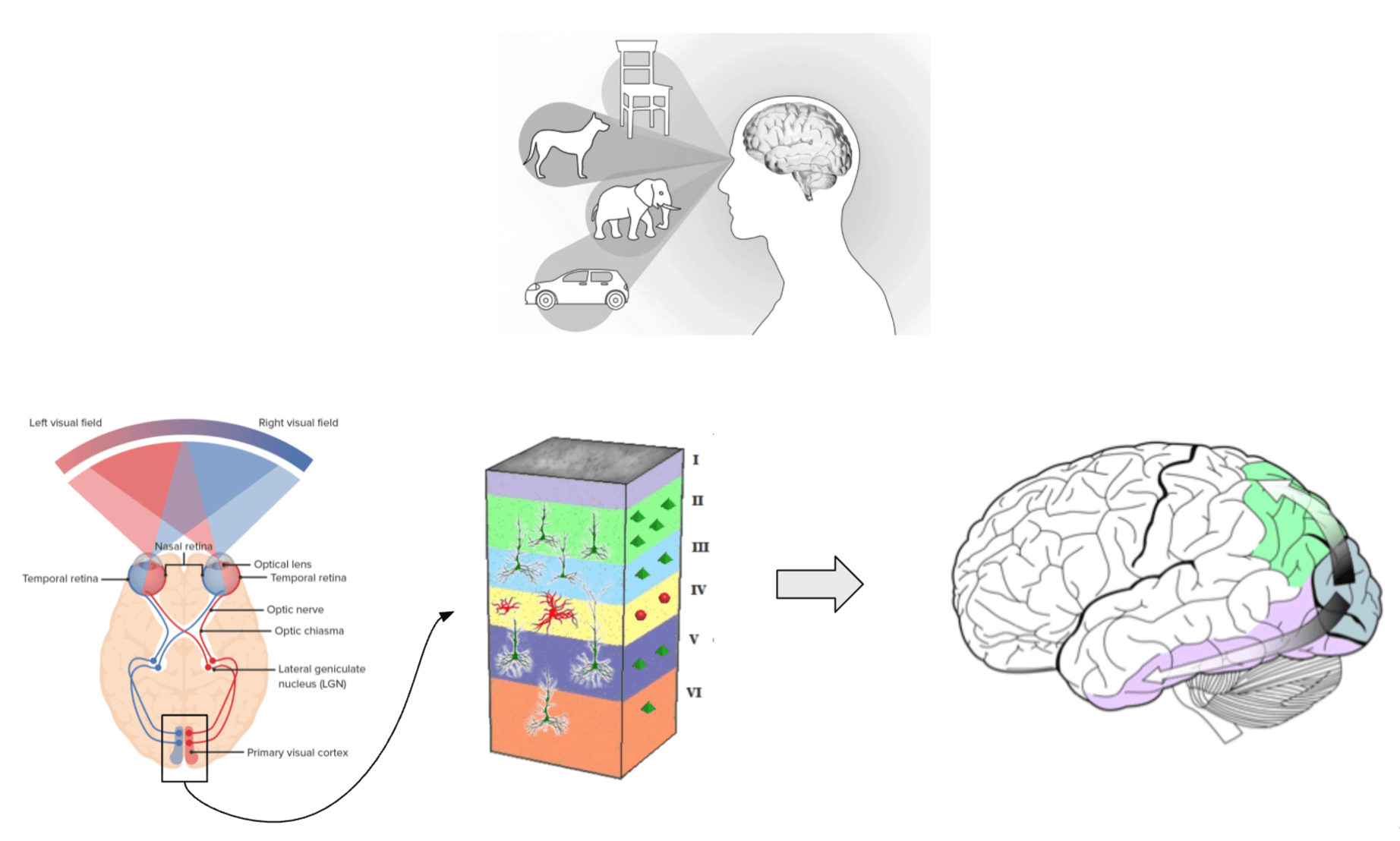
The higher functions related to vision happen on information that hardly resembles the initial intensity of the light that hit your eye. Instead, they deal with the much richer representations output by your visual cortex. When you interpret what you see or read, your brain operates on those neural representations and not the original image.
Deep learning applications process the world in a similar way. Information is converted into vector embeddings — or simply “vectors” — which are then used for predictions, interpretation, comparison, and other cognitive functions.
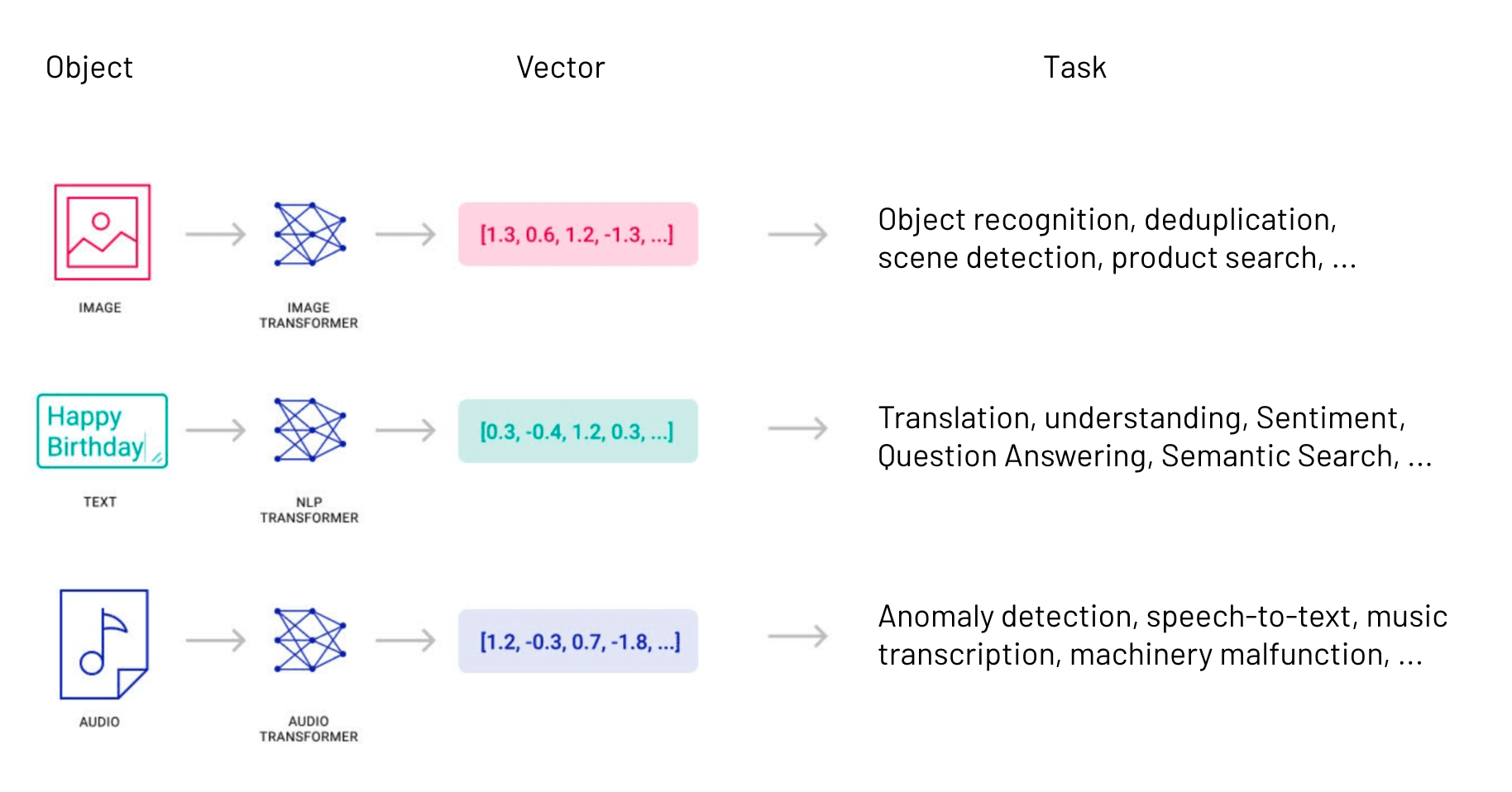
In Machine Learning, transformer models — or more generally “embedding models” — serve the role of converting raw data into vector embeddings. They generate vector data.
There are embedding models for all kinds of data: audio, images, text, logs, video, structured, unstructured, and so on. By converting raw data into vectors, they enable functions such as image search, audio search, deduplication, semantic search, object and facial recognition, question-answering, and more.
Embedding models are growing in numbers, capability, and adoption. They’re also getting easier to access and use. Deep-learning frameworks such as MXNet, TensorFlow, PyTorch, and Caffe have pre-trained models included and accessible with as few as two lines of code.

import torchvision.models as models
model = models.squeezenet1_0(pretrained=True)The more models are used, the more vector data gets generated. Often, vectors get immediately discarded after they are generated. But what if you save the vector data you generate? That, it turns out, can be quite valuable. So valuable that Google, Microsoft, Amazon, Facebook, Netflix, Spotify, and other AI trailblazers have already put it at the core of their applications.
Making Something of Vector Data
What higher cognitive functions could we unlock by aggregating millions or billions of semantically rich vectors?
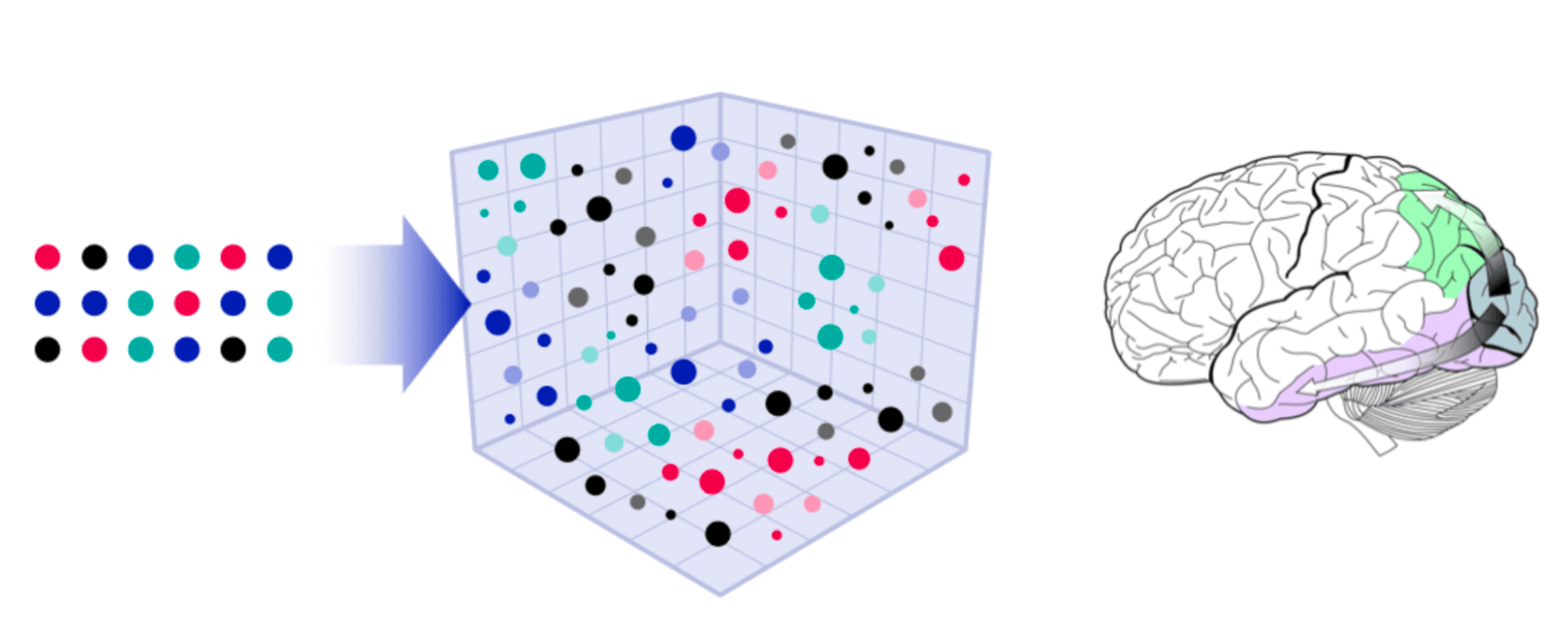
One of the most helpful and fundamental things unlocked by storing vectors is simple: search.
Given some new vector, find other known vectors that are similar. Since this similarity search (or “vector search”) acts on rich vector representations, it performs a lot more like our brains do when we look for similar objects: we use pattern recognition, semantic meaning, relevant context, memory, association, and even intuition.
This fundamentally new method of information retrieval can make many things better: search engines, recommendation systems, chatbots, security systems, analysis tools, and any other application involving user-facing or internal search functions.
And not just a little better. If you’ve recently marveled at the personalized product recommendations from Amazon, the sublime music recommendations from Spotify, the mystifyingly relevant search results from Google/Bing, or the can’t-look-away activity feeds from Facebook/LinkedIn/Twitter, then you’ve experienced the power of similarity search.
Some of those companies have written about their use of vector embeddings for search. Google, Spotify, and Facebook have even open-sourced the core components of their similarity search technology.

Vector data is growing, and there’s a clear benefit to using it for search. However, there’s a reason why only a few companies with some of the largest and most sophisticated engineering teams are doing similarity searches at scale.
The Tangle of Vector Search Algorithms
Vectors have a unique format that requires novel indexing and search algorithms.
There are well-established tools for searching through relational databases, key-value stores, text documents, and even graphs. Vector data requires an entirely new index and search methods involving the geometric relationships — proximity and angles — between items represented as vector embeddings.
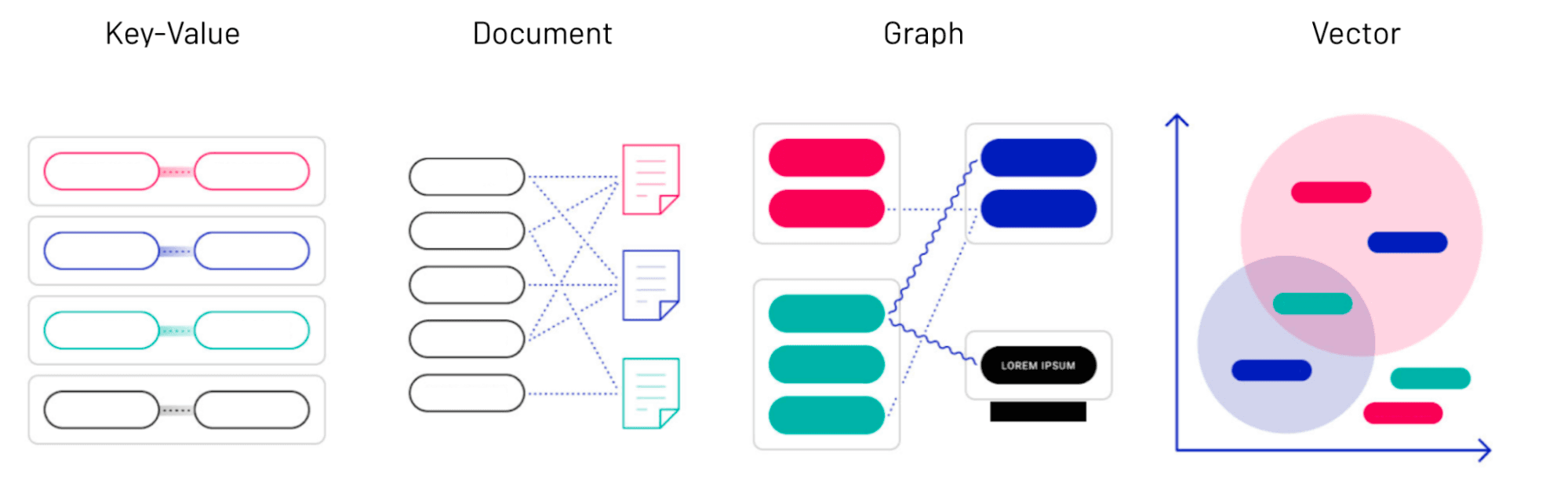
Vectors don’t contain discrete attributes or terms you could just filter through. Instead, each vector embedding is an array of hundreds or thousands of numbers. Treating those numbers as coordinates lets you treat vectors as points in a multi-dimensional Euclidean space. Then, searching for similar items is equivalent to finding the neighboring points in that space.
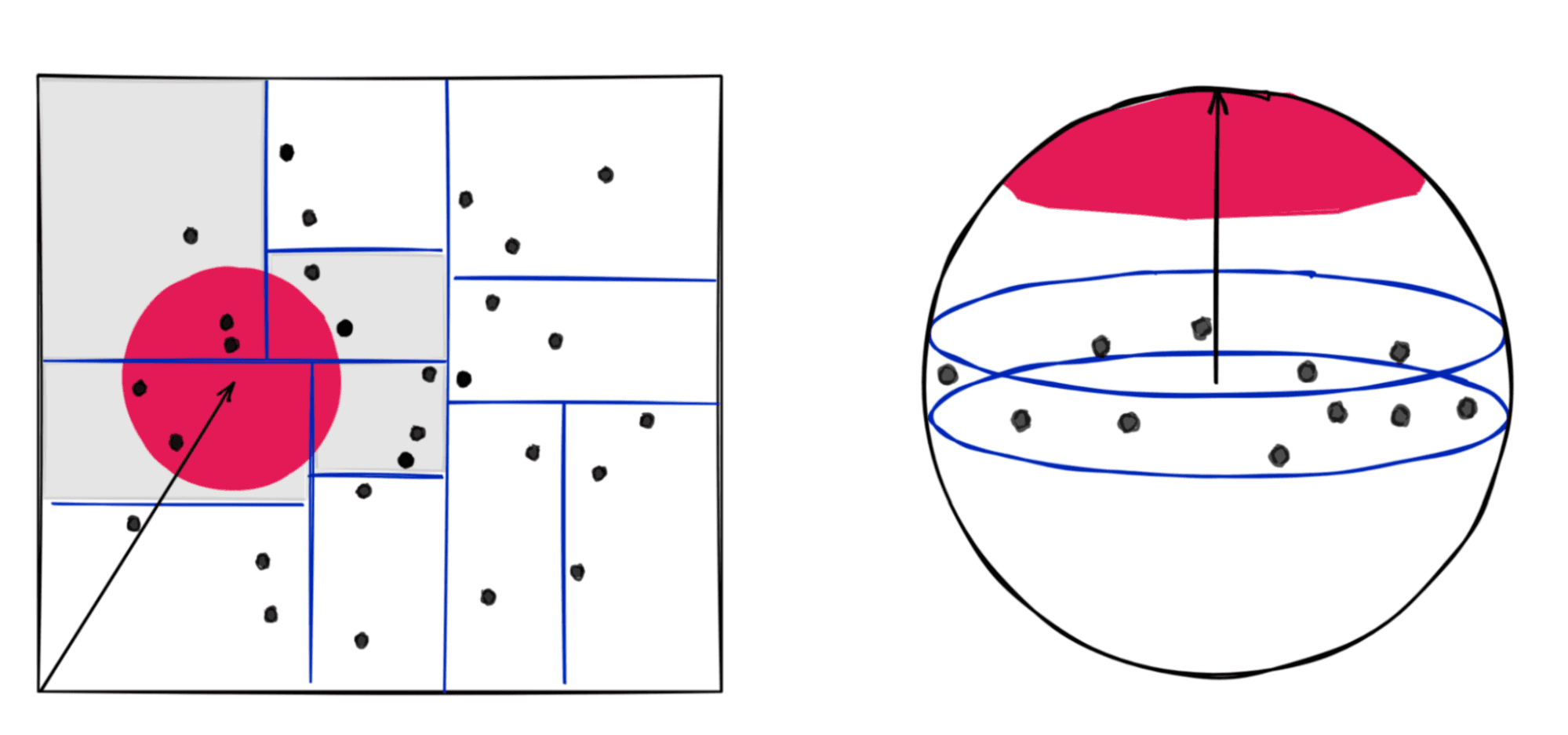
It’s relatively easy to do this with two-dimensional vectors: Dissect the space in a way that you can say, apriori, the red circle only intersects the gray rectangles, then focus your search for nearest neighbors there. That describes the well-known k-d tree algorithm. It works well in low dimensions but fails in higher dimensions. In higher dimensions (three-dimensional in the figure above for illustration), there is no simple way to dissect the space into “rectangles” to accelerate the search procedure.
We need a much more complex search algorithm for high-dimension spaces. Fortunately, there are over a dozen open-source libraries dedicated to solving this problem efficiently. Less fortunately, each of those contains multiple algorithms to choose from, each with varying trade-offs between speed and accuracy, each with different parameters to tune.
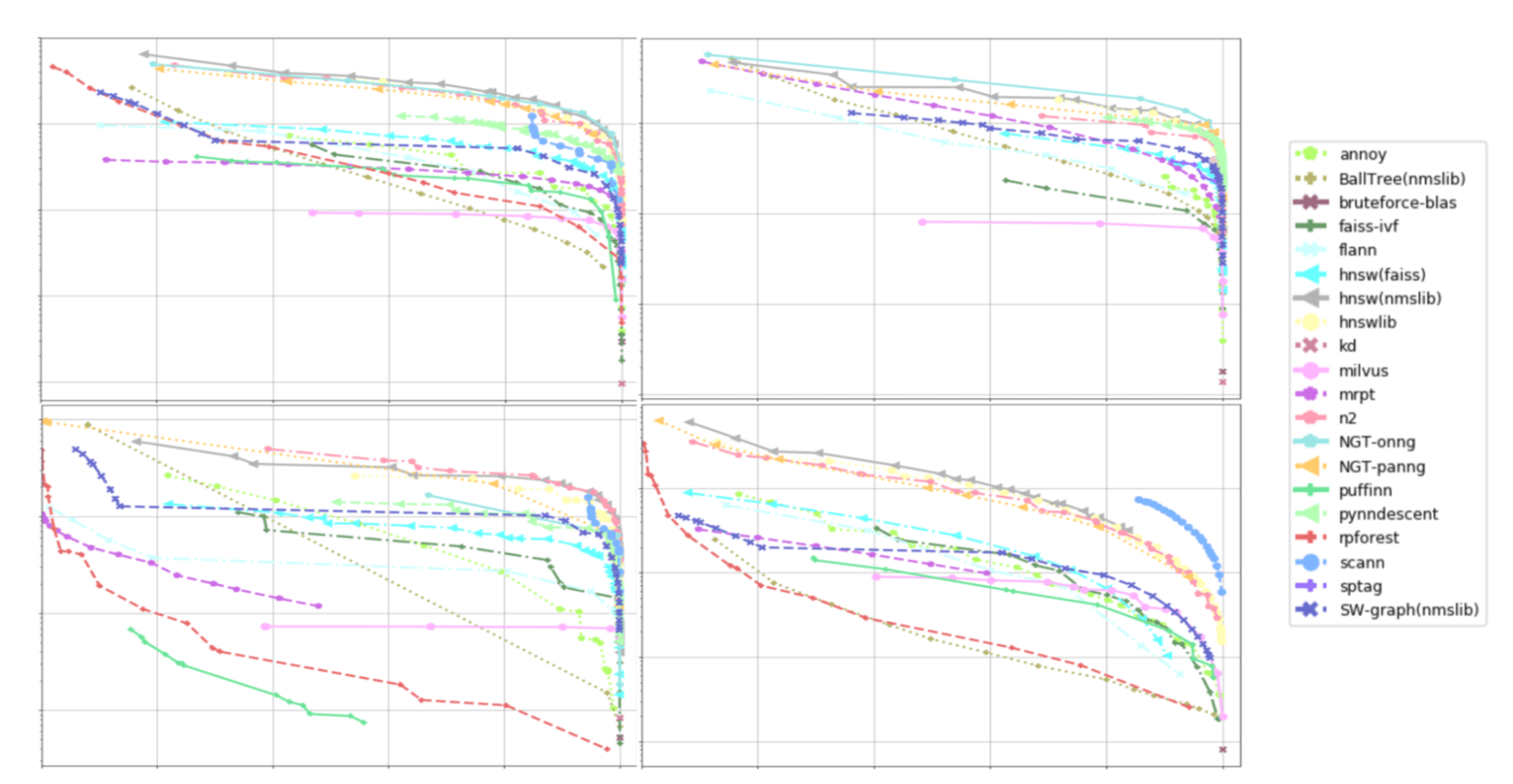
As a practical matter, choosing a library, algorithm, and parameters for your data is the first hurdle. There is no “right” answer. Each algorithm comes with a complex set of trade-offs, limitations, and behaviors that may not be obvious. For example, the fastest algorithm might be wildly inaccurate; a performant index could be immutable or very slow to update; memory consumption can grow super linearly; and more surprises like that.
The Tall Barrier to Scalable Vector Search
Storing and searching through vector data at scale looks a lot like running a database in production, and building the infrastructure takes just as much work.
Depending on the size of your vector data and your throughput, latency, accuracy, and availability requirements, you may need to build a system with sharding, replication, live index updates, namespacing, filtering, persistence, and consistency. Then you need monitoring, alerting, auto-recovery, auto-scaling, etc, to ensure high availability and operational health.
This work becomes a significant undertaking that companies like Google, Microsoft, and Amazon can afford in terms of time and resources. Most other companies can’t, so they can’t use vector search.
Or can they?
The Rise of Vector Tooling
In recent years, the rise of ML models spurred an ecosystem of tools that made it easier to develop and deploy models. As we witness the rise of vector data, we need new tools for working with that data.
We hope to lead the way with our managed vector search solution. We specifically designed it for use in production with just a few lines of code without the user needing to worry about algorithm tuning or distributed infrastructure.
The rise of vector data will have limited impact until more companies have the tools to use it and make their products better. Search is the first and fundamental step in this process, so that’s where we begin.
Was this article helpful?