Load Balancing AI Services for Availability and Speed
TLDR: Pinecone Assistant routes requests across embeddings, rerankers, and LLMs, each backed by multiple providers and regions. Static routing strategies couldn't keep up with real-time backend conditions, so we built a service-aware load balancer on top of the "power of two choices" algorithm: sample two backends, pick the better one, repeat. The result is adaptive routing with no global coordinator, automatic failover during upstream incidents, and meaningfully lower latency on structured AI calls. Different service types get different scoring policies, because LLMs and embeddings are not the same routing problem.
Modern AI products rarely depend on a single model endpoint. In Pinecone Assistant, a single user request may reach across embeddings, rerankers, and LLMs, each with multiple backends across regions and providers, some managed by third parties and others operated in-house.
Those backends serve different purposes: some exist to expand quota, some exist to improve availability, some do both. In practice, every request is also a routing problem: which backend should handle this call right now?
We built a service-aware load balancer for Pinecone Assistant to make that choice automatically. The goal: keep the product available during upstream issues, and reduce latency where latency is a useful routing signal.
The Problem
When you rely on third-party AI services, failure is not binary.
- A backend can fail hard and return errors.
- A region can stay up but get much slower.
- A provider can be healthy overall while one endpoint is overloaded.
- Quota pressure can force traffic away from the endpoint you would normally prefer.
- A backend can recover, but static routing will not notice quickly enough.
We had already seen this in Pinecone Assistant: outages, latency spikes, and the operational work of routing around them manually. Before this approach, we also tuned routing by region proximity to keep latency down. That helped, but it was still a static strategy in a system where backend conditions changed continuously. We needed routing that reacted in real time.
What We Wanted
We were optimizing for a few properties at once:
- High availability: unhealthy backends should stop receiving traffic quickly.
- Low latency: when latency is predictable enough to optimize, we should get that benefit from live conditions rather than manual tuning.
- Low coordination overhead: no complex global controller making every decision.
- Graceful recovery: backends that recover should rejoin traffic automatically.
- Service-specific behavior: embeddings, rerankers, and LLMs should not all be treated the same way.
That last point mattered most. A good policy for one kind of AI call can be exactly the wrong policy for another.
Approaches We Considered
Before settling on our design, we looked at several well-known techniques.
Least loaded routes each request to the backend with the fewest active connections. This works well for long-lived TCP connections or file transfers, where connection count is a reliable proxy for load. AI service calls and vector database queries break those assumptions. A backend with two active connections can be slower than one with twenty, depending on queue depth, request complexity, and current memory pressure. Connection count is a surface metric; it does not expose what is actually happening inside the backend.
Latency-aware routing selects the globally best backend by measured latency. The appeal is clear, but it introduces two problems. First, it requires coordination and continuous metering costs across all callers, adding overhead we wanted to avoid. More critically, it is structurally unstable. When all callers share the same latency estimates, they converge on the same winner simultaneously. That winner gets overloaded, its latency spikes, everyone shifts to the next winner, and the cycle repeats. Exponentially Weighted Moving Average (EWMA) tracking dampens this somewhat, but the herding behavior is inherent to any globally-ranked scheme and does not fully go away.
Round-Robin and Weighted Round-Robin cycle through backends in order, with optional weighting to distribute traffic unevenly. Both are simple, predictable, and promote fairness. The limitation is the weights are static. They do not change dynamically when a backend slows down or partially fails. When one machine fails, fairness means every caller absorbs its share of the impact until the configuration is manually updated.
Consistent Hashing maps requests to backends deterministically, typically on a key like user ID. This is valuable for cache locality: the same user always hits the same backend, which warms up caches and reduces redundant work. We evaluated this specifically for LLM workloads where prompt caching matters. The problem is that consistent hashing does not adapt. If the assigned backend slows down or fails, that user stays on it until the configuration changes. We need automatic adaptation, not sticky routing with manual overrides.
Random Selection picks a backend uniformly at random. It is cheap, stateless, and trivial to implement, but it has no situational awareness and does not balance load evenly under variance. For example, we must detect repeated failures and remove unhealthy backends from the pool to prevent them from getting more requests. Then, after a cooldown, backends re-enter the pool. This health tracking and pool management turns out to be very complex, and it ends up hardcoding much of the adaptive logic the load balancer was supposed to provide in the first place.
The Power of Two Choices
Each of those approaches fails for the same underlying reason: they trade one problem for another. Random selection is blind. Global ranking is unstable. Static policies don't adapt. The fix is to stop treating this as a binary choice between "ignorant" and "omniscient." In 1996, Mitzenmacher showed there is a middle path. Instead of choosing randomly or ranking globally, sample two backends at random and pick the better one. That single extra comparison drops the maximum load from to , an exponential improvement from one additional choice.
This idea is usually known as “power of two choices” (p2c) and is the backbone of our balancer:
- Pick two candidate backends at random.
- Compare them using a recent score.
- Send the request to the better one.
The decision is simple, local, and cheap. It preserves enough randomness to avoid herding while still steering traffic away from the worst hot spots. No distributed state, no global controller, just one comparison per request.
What We Built
Each request follows the same pattern:
This is intentionally simple. We are not trying to predict the future perfectly. We are trying to make a good routing decision using fresh signals, without turning the balancer itself into a complicated distributed system.
One Service Type, One Policy
The most important design choice was not using a single scoring rule everywhere.
| Service type | What dominates latency | Routing signal |
|---|---|---|
| Embeddings | Endpoint health, queueing, network path | Recent latency + reliability |
| Rerankers | Endpoint health, queueing, network path | Recent latency + reliability |
| LLMs | Prompt size, caching, model behavior, output length | Reliability and load, not end-to-end latency |
For embeddings and rerankers, latency is a useful signal. Those calls are structured and comparatively fast, and performance differences across backends show up clearly enough that routing on recent latency gives a real benefit.
LLMs are different. End-to-end latency is heavily shaped by the request itself: prompt length, cache behavior, model internals, and token count. Routing on that number is noisy, and it breaks cache locality. Some LLM calls benefit from caching that is local to a specific backend; constantly chasing the lowest measured latency works against that. Short-lived sticky routing outperforms it.
For streaming workloads, time-to-first-token is a better signal than full completion time. But in general, LLM routing should optimize for availability and load, not raw speed.
Exploration and Recovery
p2c works because it routes on recent scores. That is also its vulnerability: scores only stay fresh if backends keep receiving traffic.
The fix is small: continuous allocation of exploratory traffic — not enough to hurt performance, but enough to keep the picture fresh. Good load balancing is not just about steering away from trouble; it is about noticing when the trouble is over.
Results
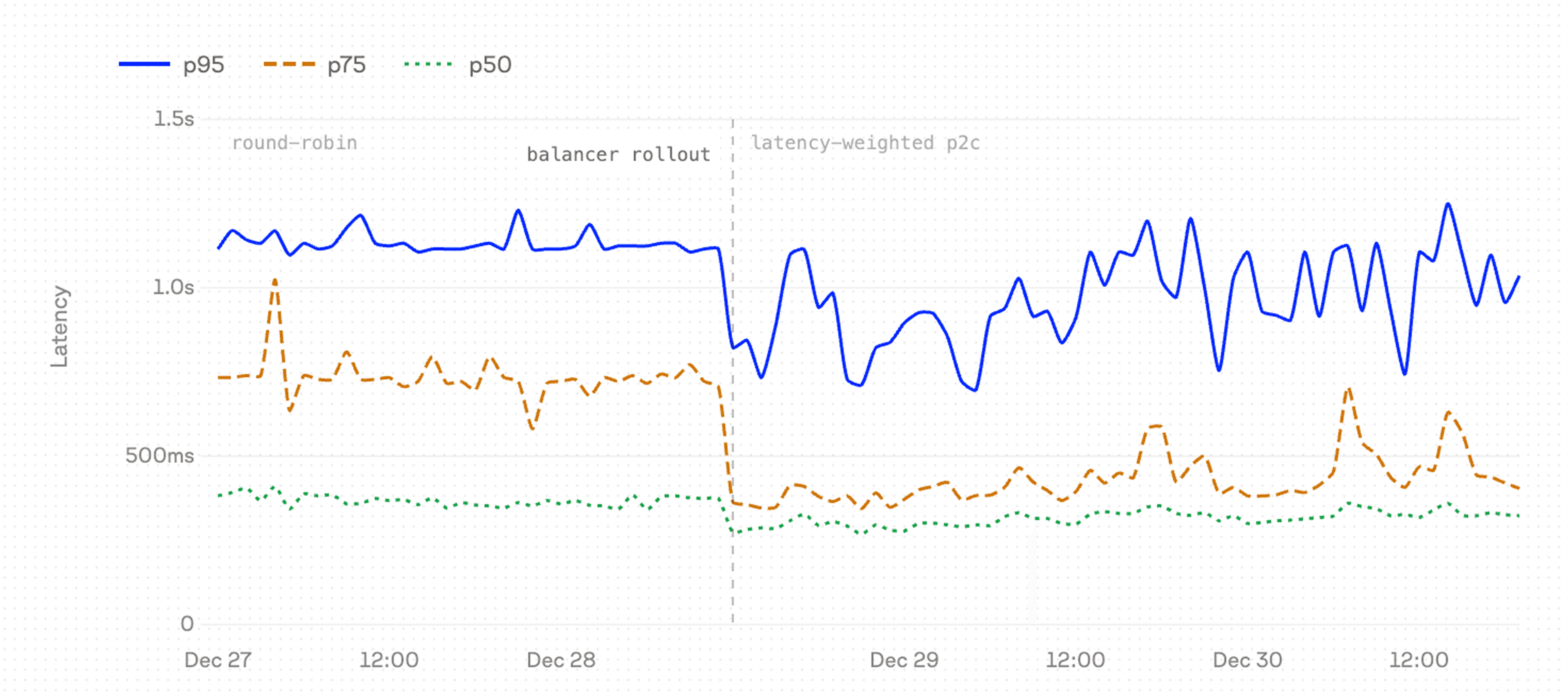
The balancer rolled out in stages: rerankers migrated first from direct provider calls onto a p2c-balanced path, then embeddings had a scoring-strategy swap from round-robin to latency-weighted p2c. The metrics below track each transition.
Reranker latency (direct provider calls → balanced path)
Before rollout, reranker calls went directly to Provider A with a 10-second client timeout. After rollout, calls flow through a p2c-balanced path across multiple replicas including integrated inference services.
| Metric | Before | After | Change |
|---|---|---|---|
| p50 | 138 ms | 135 ms | −3% |
| p95 | 7,577 ms | 953 ms | −87% |
| p99 | 10,621 ms | 1,917 ms | −82% |
The pre-rollout tail was timeout-bound; the new path's tail is simply network plus model latency against a healthy replica.
Embedder latency (round-robin → latency-weighted p2c)
Embeddings already had a balancer, but it used round-robin selection. The strategy swap introduced the p2c scoring described above.
| Metric | Before | After | Change |
|---|---|---|---|
| p50 | 368 ms | 298 ms | −19% |
| p95 | 3,802 ms | 1,793 ms | −53% |
| p99 | 4,377 ms | 3,171 ms | −28% |
Bulk ingest throughput also rose about 4.5× the same week. The reconciler had been bottlenecked on slow embedder calls; smarter routing unblocked it.
Before → after for embeddings
The latency drop is a routing story. Under round-robin, all six provider endpoints received equal traffic regardless of performance — roughly 17% each. Under latency-weighted p2c, the balancer scores replicas continuously and concentrates traffic on the faster ones.
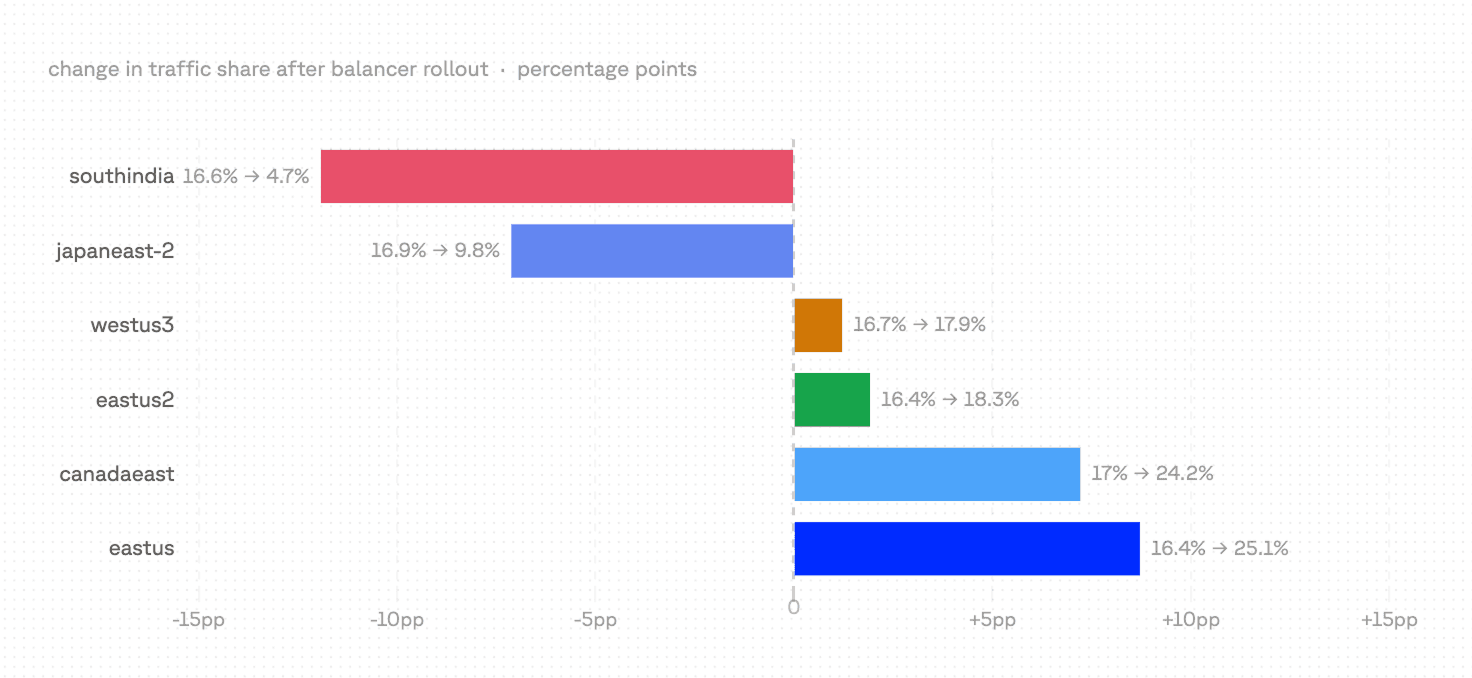
Two endpoints lost significant share; two gained it. The balancer keeps lower-traffic endpoints in the pool as overflow capacity and for exploratory traffic — probing them with a small fraction of requests so it detects when performance recovers. The concentration toward the top two endpoints is what produced the p75 and p95 improvements in the table above.
Availability during upstream incidents
Across the rollout window we observed four material backend degradations. The balancer absorbed short, narrow incidents fully; on broad, multi-day degradations it reduced but did not eliminate user impact.
The acute spike is the textbook case: one Provider A region degraded, the balancer routed around it, and users saw 5 failed reranks out of 6,580 calls that day in this cluster.
The two multi-day Provider A incidents show where the balancer's absorption runs out. When most replicas of the same upstream provider are simultaneously slow or erroring, no balancer can fully mask the degradation — the best it can do is pick "least bad”.
The Provider B incident is the clearest continuity win, and the one that validates the LLM-specific policy choice. Our LLM balancer scores on reliability and load rather than end-to-end latency. Through 12 days of sustained regional degradation (peaking at 1,288 unhealthy signals on a single day), chat throughput stayed flat at 3.4–6.2k requests/day and no alerts paged. Customers did not notice.
Operational impact
Manual routing interventions dropped from roughly 3 per week to near zero after the balancer was deployed. The hand-tuned regional preference configuration that had required ongoing maintenance was also eliminated.
The Bigger Lesson
AI load balancing is not one problem. It is a family of related problems. The right strategy depends on what kind of service sits behind the call, what signals are trustworthy, and how much coordination you want to pay for.
For us, the winning pattern was simple: keep unhealthy backends out of the way, use p2c to get most of the benefit of smart routing with very little complexity, and stop pretending every AI service should be optimized the same way.
Was this article helpful?


