Benchmarking AI Assistants
Pinecone Assistant is a fully managed service that abstracts away the many systems and steps required to build an AI assistant for knowledge-intensive tasks over private data.
Our focus is on delivering the highest-quality and dependable answers over private data. As with every R&D effort, we needed a benchmark. Both for tracking internal progress and comparing with alternative approaches. There was just one problem: How do you measure the answer quality of an AI assistant, which itself is made up of interconnected components that don’t all have established benchmarks?
For context, here are just some of the many parts that power Pinecone Assistant under the hood.
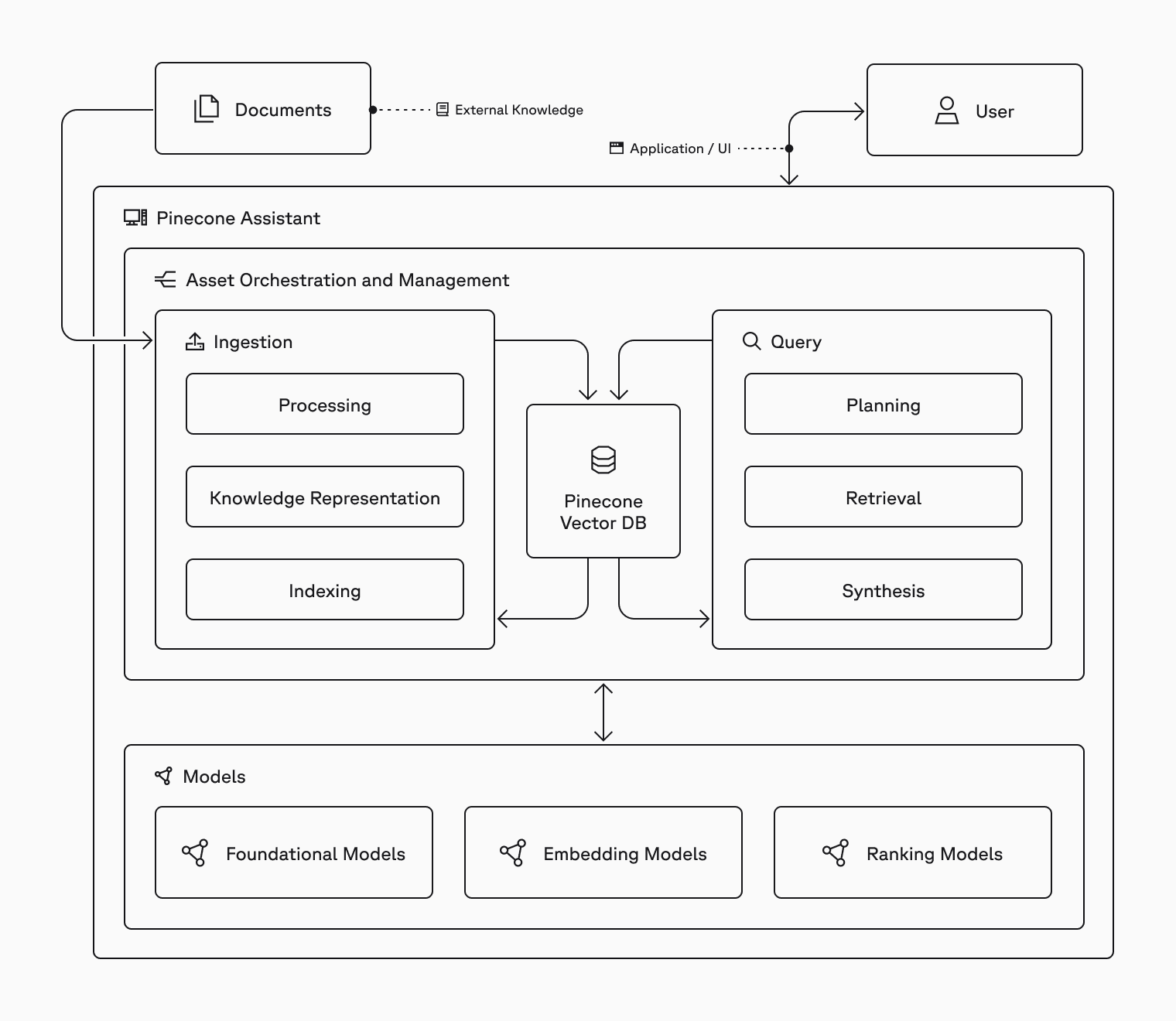
Let’s look at where existing evaluation metrics fall short, the metric we propose for evaluating AI assistants, and how Pinecone Assistant performs across three benchmark datasets.
For a comprehensive look at RAG pipeline performance evaluation metrics and frameworks, see RAG Evaluation: Don't let customers tell you first.
Answer Alignment Score
Evaluating generative AI answers is challenging due to their free-form nature. Compared to structured responses, generative AI outputs can vary significantly in style, structure, and content, making it hard to apply consistent evaluation metrics. Additionally, verifying the facts is difficult, as it often requires checking against reliable sources. This variability and the need for detailed judgment make it challenging to measure quality in a meaningful and quantifiable way.
Many frameworks and metrics have been developed to address this issue. Most of them are unsupervised and use state-of-the-art LLMs to evaluate answers against the context provided by the information retrieval system. When we analyzed the results, we found that for many datasets, unsupervised metrics and human judgment are not aligned.
For example, when comparing the RAGAS evaluation library on FinanceBench, we get a false-positive rate of 0.94 (lower is better). This approach means the metric does not always capture hallucination.

This issue led us to research alternative metrics, resulting in the development of new, supervised, correctness-completeness metrics using the following protocol:
- Extracting a list of atomic facts from the ground truth answer.
- Using an LLM, match the generated answer provided by the assistant with every fact extracted in Step 1
- For every generated answer, we classify each fact extracted in Step 1 with one of the following: “Entailed” - fact was provided and supported by the assistant’s answer; “Contradicts” - the assistant’s answer provided information that contradicts the fact; “Neutral” - the fact is not validated nor contradicted by the assistant’s answer.
We then aggregate, per question, and calculate Correctness-Completeness (formerly Precision-Recall) as follows:
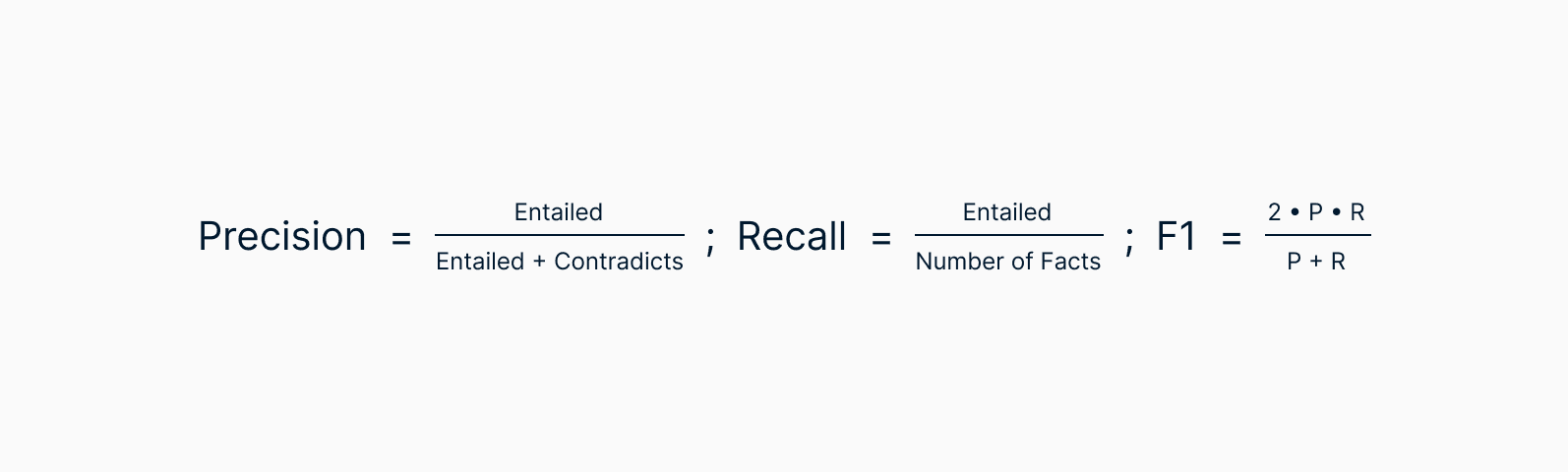
When using our developed metrics, we see much higher accordance with human judgment—we reduced the false-positive rate from 0.94 to 0.027 while maintaining a low false-negative rate. These metrics can also capture hallucinations much more effectively.

Gathering ground truth answers is a resource-intensive task. However, we think that alignment is the most important trait of an evaluation system, even with the complex process of gathering the datasets. We also continue our research on partially synthetic annotations and implicit annotations from human feedback, with additional updates to follow.
Datasets
To evaluate a knowledge-intensive assistant, we gathered different datasets, each focusing on various aspects of retrieval and generation. First, we began with different domains and found that a typical pattern among developers today was to use retrieval and language models to analyze financial and legal documents and to build general Q&A systems built on private data. The table below provides an overview of the 3 datasets we used for evaluation.
| Dataset Name | FinanceBench | Open Australian Legal | NQ-HARD |
|---|---|---|---|
| Domain | Financial Analysis | Legal | General Q&A |
| Type of Task | Multi step, complex reasoning | Long form documents needle-in-the-haystack | Long form documents (non self-contained) |
| Description | 10K, 10Q and other filings of American corporations. Questions involve information retrieval from multiple pages and complex reasoning. | A sample* of 300 questions and answers out of 2124 synthesized by gpt-4 from the Open Australian Legal Corpus. | A sample* of 301 questions from 479 originated from the Natural Questions dataset and selected such that multiple retrievers score zero NDCG@10 and questions are not self-contained in a single passage. |
| Number of Documents/pages | 79 / 23K | 5,300* / 110K | 9,705*/ 100K |
| Number of Queries | 138 | 300 | 300 |
| Ground Truth Origin | Human | GPT-4 | Human |
| Source | SEC Filing | Public Information | Wikipedia |
Table 3: evaluation datasets, including FinanceBench, Open Australian Legal, and NQ-HARD.
* Datasets were sampled down in order to fit within OpenAI Assistants max file limits.
** While the original paper notes 150 questions, 12 questions have broken URLs and could not be used in this evaluation
*** We used only questions containing short answers (see NQ paper).
Results
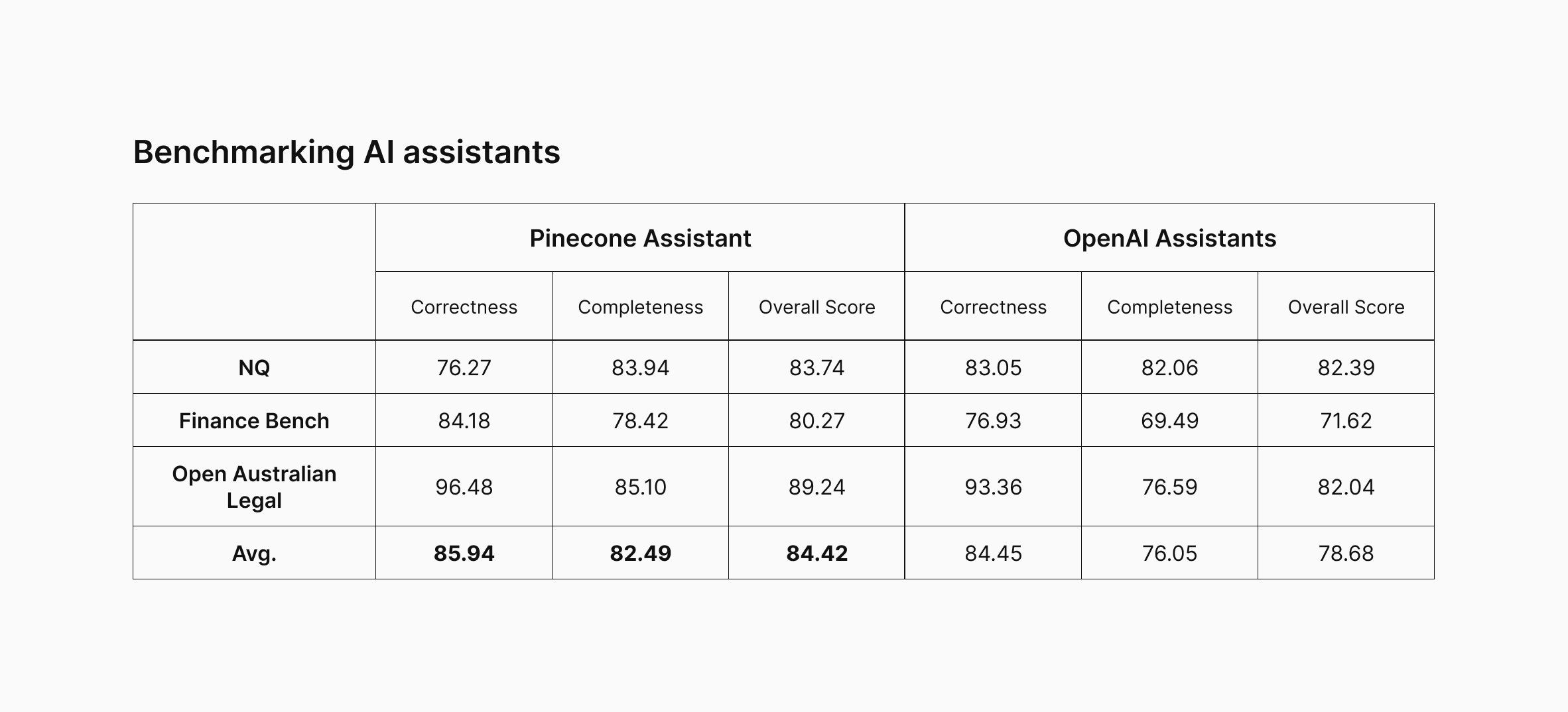
What’s next
The Pinecone Assistant architecture includes a new benchmarking scheme that provides a way to measure generated answers for a dataset in a way that strongly correlates with human preferences. Future directions for this research are to expand the number of datasets, with a goal of generating automated benchmark results using the Answer Alignment Score metric for an arbitrary or user-defined dataset, without the need for expensive ground truth collection.
Was this article helpful?