As humans, we don’t learn tasks in isolation. As we move our knowledge path forward, we build on previously learned and related challenges, which accelerates the learning process.
If you already know a particular musical, cooking, or dance style, you will not forget that knowledge and start from scratch when learning a different style; you will reuse the knowledge you already have and finetune it to absorb the new features. This is an incredible human capability, which can also be applied to machines through the use of Transfer Learning (TL).
This way, what has been learned in one setting is built upon to improve generalization on a related setting, which is a huge advantage over traditional approaches that don’t capture this benefit. Traditional Machine Learning models require training from scratch, which is computationally expensive and requires a large amount of data to achieve high performance. They also involve isolated training, where each model is independently trained for a specific purpose without any dependency on past knowledge.
Transfer Learning (TL) is a Machine Learning method where a model developed for a task is reused as the starting point for a model in another task.
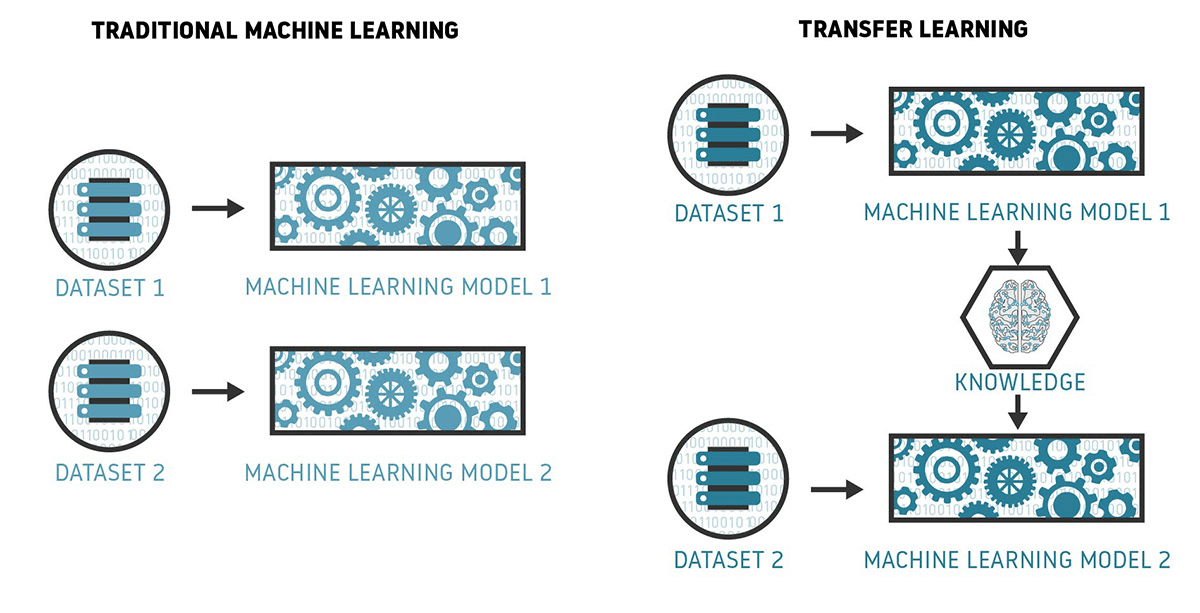
TL has become highly popular given the enormous resources required to train Deep Learning models, especially in the areas of:
- Natural Language Processing (NLP) to solve problems that use text as input or output. In this discipline, there are several effective algorithms that generate distributed representations or text, such as words or sentences. These solutions are commonly released as pretrained models which are trained on a very large corpus of text documents.
- Computer Vision (CV) in which it’s very unusual to train an entire Convolutional Neural Network (CNN) from scratch (with random initialization), since it’s relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a CNN on a very large dataset and then use that model either as an initialization or a fixed feature extractor for the task of interest. This way, the majority of the pretrained CNN can be employed on new models through TL, just retraining a section of it.
Transfer Learning in action
How does the transfer learning process work? Although there are different approaches, two of the main ones are:
- Feature-based, which does not modify the original model and allows new tasks to benefit from complex features learned from previous tasks. However, these features are not specialized for the new task and can often be improved by fine-tuning.
- Fine-tuning, which modifies the parameters of an existing model to train a new task. The original model is “unfrozen” and retrained on new data, increasing the performance for the new task.
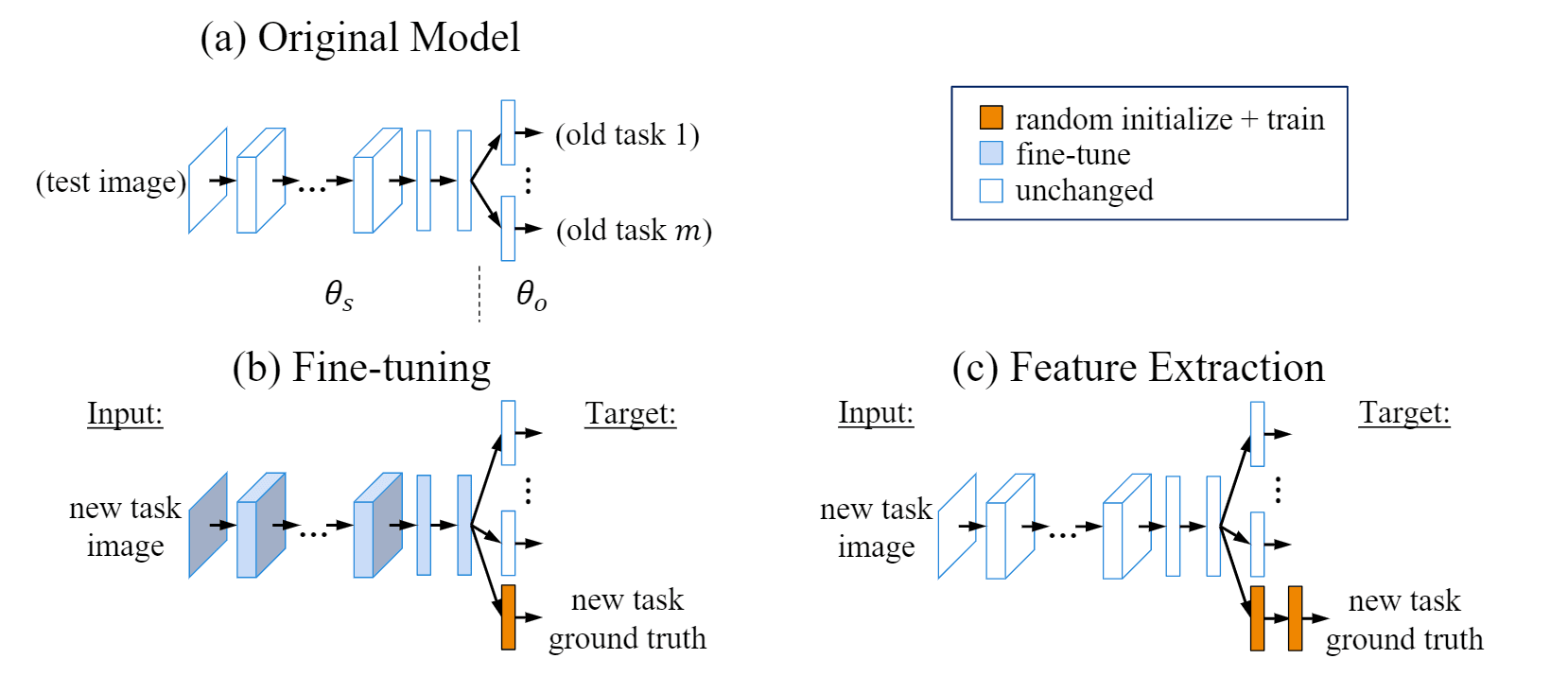
These approaches can be integrated in TL, producing the following workflow:
- Take layers from a previously trained model.
- Freeze them to avoid altering any of the information they contain during future training rounds.
- Add some new, trainable layers on top of the frozen layers. They will learn to turn old features into predictions on a new dataset.
- Train the new layers on your dataset.
As a last step, one can perform a fine-tuning of the model: unfreezing the entire model obtained above (or part of it) and re-training it on the new data with a very low learning rate. This can potentially achieve meaningful improvements by incrementally adapting the pretrained features to the new data.
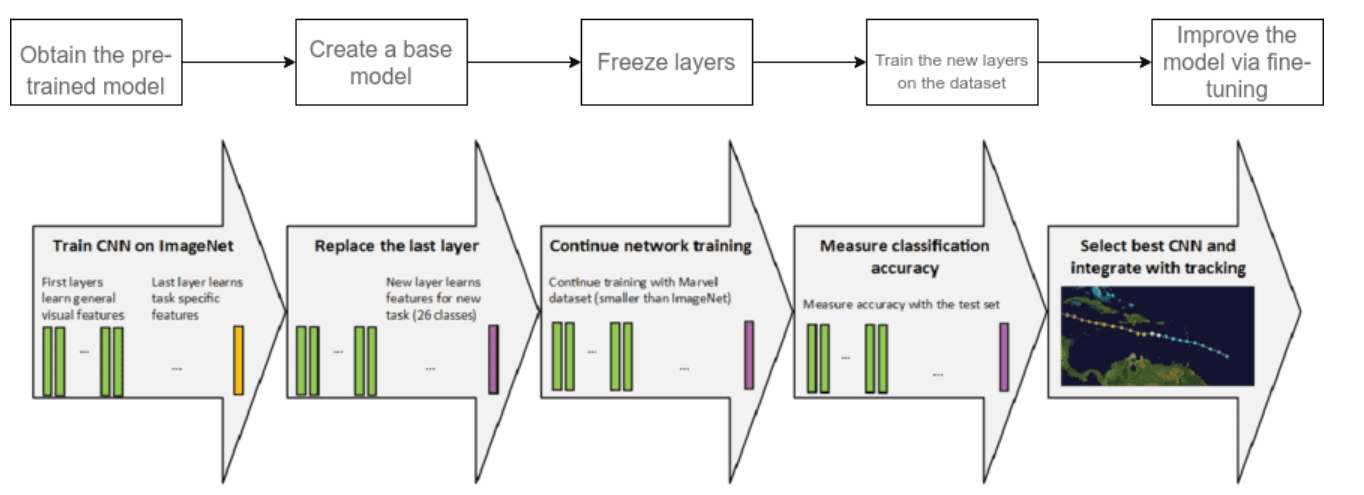
Using this workflow as a generic approach to perform TL, let’s see how specific pretrained models can be used to solve different challenges.
Computer Vision
In Computer Vision, the intuition is that if a model is trained on a large and general enough dataset, it will effectively serve as a generic model of the visual world. Some of the main pretrained models used in Computer Vision for TL are:
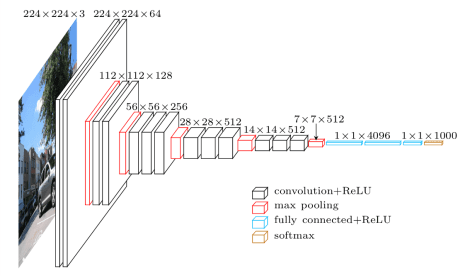
- Visual Geometry Group (VGG) and all its variants like the VGG16 model, which is a CNN of 16 layers trained on a subset of the ImageNet dataset, a collection of over 14 million images belonging to 22,000 categories. Characterized by its simplicity, VGG was developed to increase the depth of such CNNs in order to increase the model performance. The VGG model is the basis of ground-breaking object recognition models and became one of the most popular architectures.
- Residual Network (ResNet), which relies on the fact that as the number of layers increases in a CNN, the ability of the model to fit more complex functions also increases. ResNet introduces a so-called “identity shortcut connection” that skips one or more layers in the CNN architecture, gaining accuracy from considerably increases in depth. This way, the model ensures that the higher layers of the model do not perform any worse than the lower layers, improving the efficiency while minimizing the percentage of errors. Models like Resnet150 can work with more than 150 neural network layers, as deep models generalize well to different datasets.
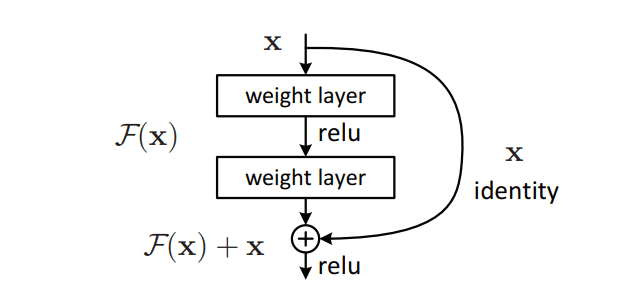
Natural Language Processing (NLP)
Like in Computer Vision, you can take advantage of the learned features from NLP pretrained models without having to start from scratch by training a large model on a large dataset. Some of the main pretrained models used in NLP for TL are:
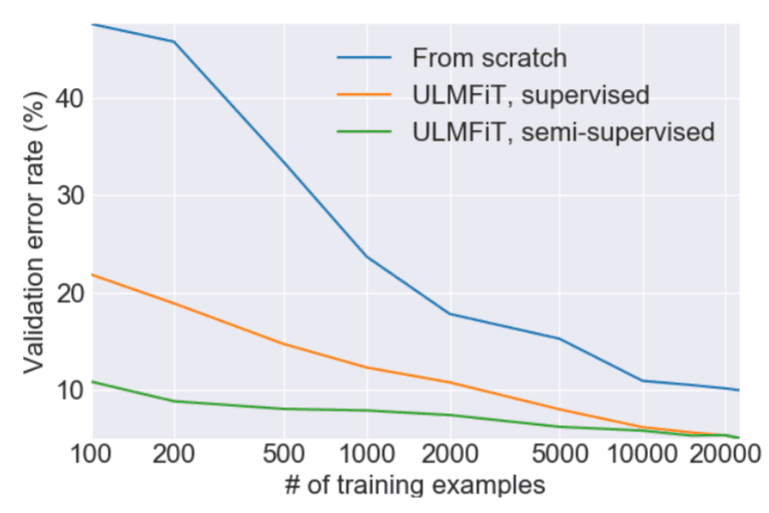
- Universal Language Model Fine-tuning for Text Classification (ULMFiT), an AWD-LSTM model that was trained on the Wikitext-103 dataset and showed incredible performance on tasks like finding documents relevant to a legal case, identifying spam and offensive comments, classifying reviews of a product, grouping articles by political orientation, and much more. ULMFiT introduces different techniques like discriminative fine-tuning (which allows us to tune each layer with different learning rates), slanted triangular learning rates (a learning rate schedule that first linearly increases the learning rate and then linearly decays it), and gradual unfreezing (unfreezing one layer per epoch) to retain previous knowledge.
- Bidirectional Encoder Representations from Transformers (BERT), a model that significantly altered the NLP landscape, became a new benchmark useful for almost any task. BERT is a transformer-based model trained on 2.5 billion words with the ability to consider the context from both the left and right sides of each word. Its popularity came after breaking several records for how well it can handle language-based tasks like question answering, text summarization, sentence prediction, word sense disambiguation, natural language inference, and sentiment classification, among others.
The good and the bad
Transfer learning is a shortcut to saving time, resources and getting better performance. Although it’s not obvious that there will be a benefit to using TL in the domain until after the model has been developed and evaluated, there are some possible advantages like:
- Higher start. The initial skill (before refining the model) on the source model is higher than it otherwise would be.
- Higher slope. The rate of improvement of skill during training of the source model is steeper than it otherwise would be.
- Higher asymptote. The converged skill of the trained model is better than it otherwise would be.
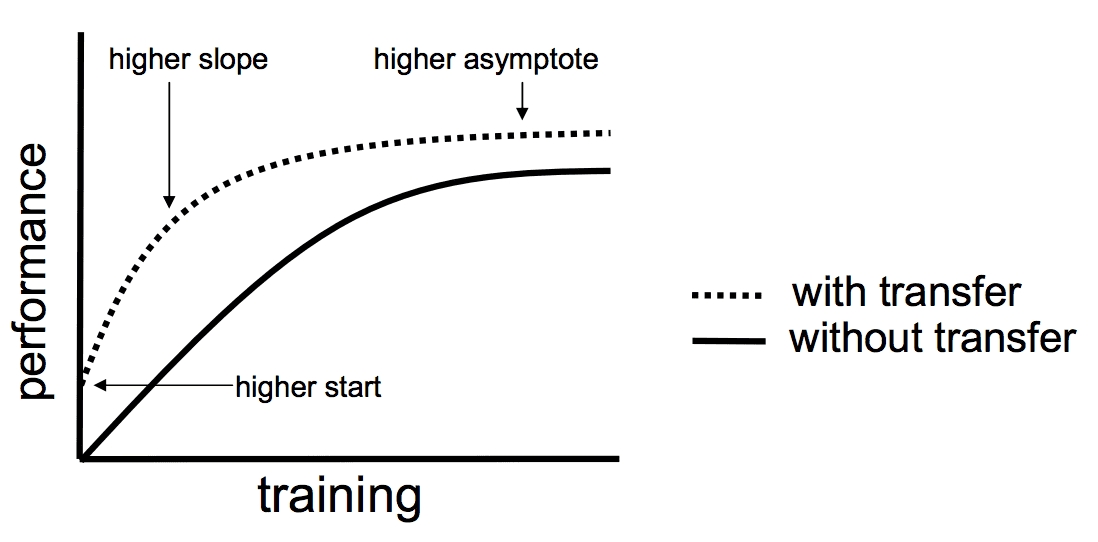
Ideally, you would see all three benefits from a successful application of TL, which in practical terms, you can try to seek if:
- You identify a related task with abundant data and you have the resources to develop a model for that task and reuse it on your problem, or
- There is a pre-trained model available that you can use as a starting point for your own model.
This all sounds great, but although the goal of TL is to improve a model’s performance, it can also degrade it. If the TL task ends up with a decrease in the performance or accuracy of the new model, then it produces an effect called negative transfer. Negative transfer can be caused by too high a dissimilarity of the problem domains or the inability of the model to train for the new domain’s data set (in addition to the new data set itself).
Transfer learning can also induce overfitting, which happens when the new model learns details and noises from the training data that negatively impact its outputs.
Transfer learning can come with a variety of serious problems, including distributional biases, social stereotypes, potentially revealing training samples, and other possible harms. In the case of NLP language pretrained models, one particular type of harm is the generation of toxic language, which includes hate speech, insults, profanities, and threats.
There’s no such thing as free lunch. Although transfer learning has several limitations, it allows for repurposing models for new problems with less data for training, gaining efficiencies in time and resources.
Besides the obvious economic benefits of using TL, some people believe it might also be the gateway to more impactful advancements in AI. As Demis Hassabis (CEO and co-founder of DeepMind) said:
I think Transfer Learning is the key to General Intelligence. And I think the key to doing Transfer Learning will be the acquisition of conceptual knowledge that is abstracted away from perceptual details of where you learned it from.
Was this article helpful?