Hybrid Search and Learning-to-Rank with Metarank
As more advanced Large Language Models (LLMs) are released, the dream of an accurate semantic search comes closer to reality. But a classical term search is still hard to beat, even with the largest LLMs. So what if you don’t need to choose between two approaches and combine them within a single hybrid multi-retriever system?
In this article, we’re going to discuss a case when Elasticsearch, Opensearch, Solr, and Pinecone are used together to get the best from both words, with the final combined ranking produced with Metarank.
A Multiple Retrievers Problem
A typical scenario for the multi-retriever setup is to have a traditional Lucene-based term search and a vector search engine installed side-by-side for the same collection of documents and query both in parallel. A classical term search will return BM25-scored documents, and a vector search engine will try to produce a more semantically correct set of results.
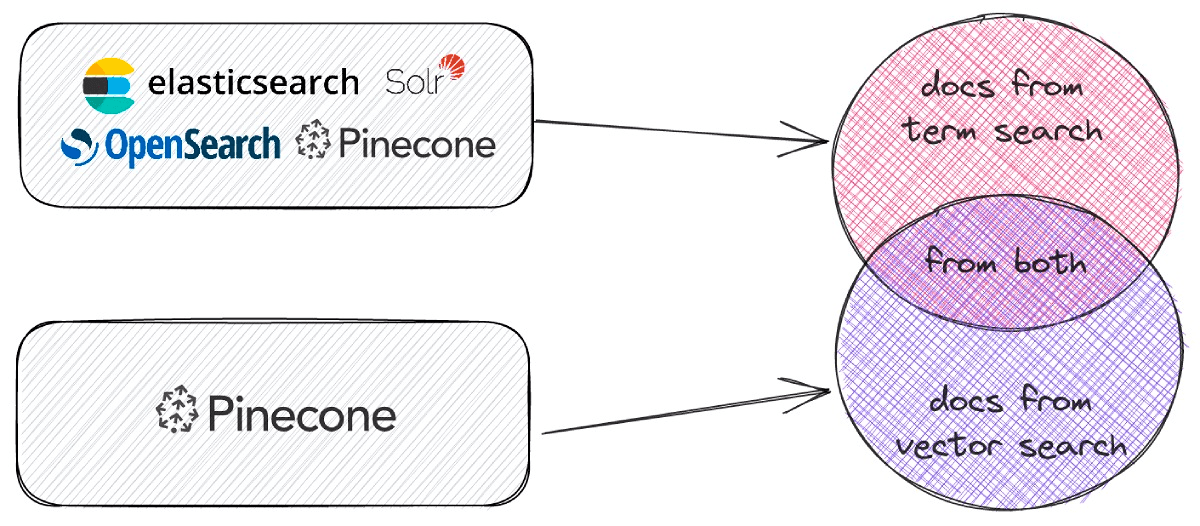
However, when you have multiple sources of documents to merge into a single search page, it may not be obvious how to combine them:
- Different retrievers use non-comparable score types, like BM25 and cosine similarity.
- Documents may come from single or multiple sources at the same time. There should be a way to deal with duplicates in the final ranking.
In a beautiful world where BM25 and cosine similarity have the same scale and statistical distribution, a final ranking can be done by just adding both scores together.
BM25 Score Distribution
Lucene-based classical search engines like Elastic, SOLR, and OpenSearch use BM25 as a scoring function to rank multiple found documents for a single search result listing. The BM25 formula depends on the lengths of query, document, and term frequencies, and its values are usually distributed within the low double-digits range.
A practical example of BM25 values distribution is the MSRD dataset: 28320 unique movie search queries over a database of 10k TMDB movie descriptions. In the diagram below, you can see how BM25 scores are distributed across different positions within search results:
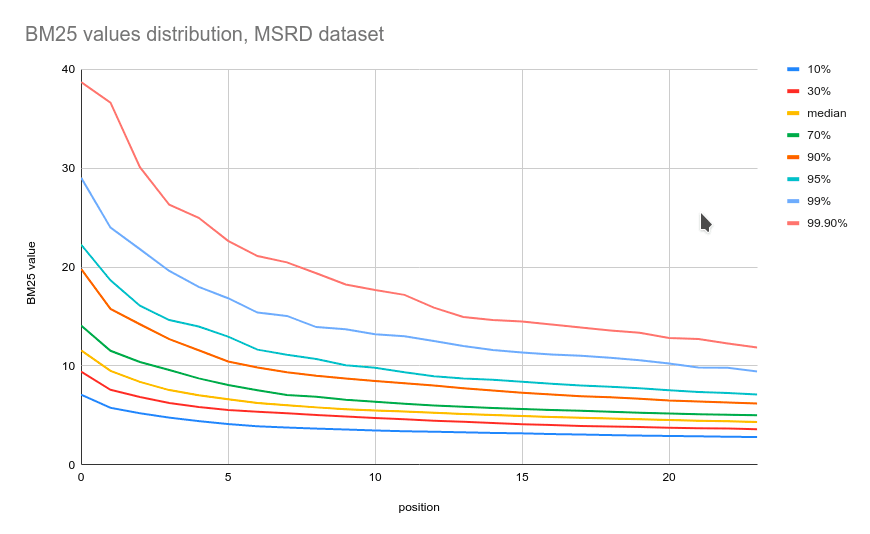
From another perspective, BM25 scores of items in the first position have a non-even distribution, as you can see from the graph below:
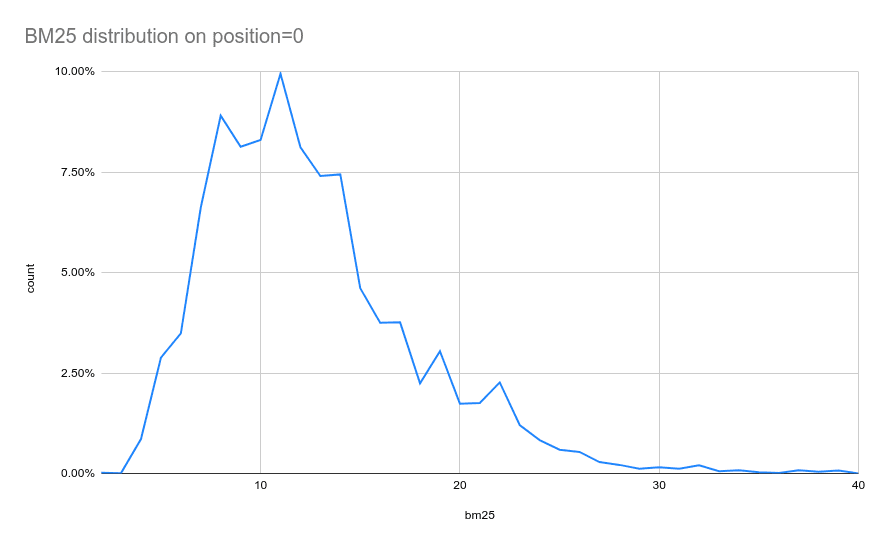
So in a real-world situation, the BM25 scores you may get from an Elasticsearch are unbound and non-evenly distributed, which is perfectly fine until you try to merge it with another non-even distribution.
Cosine Similarity Value Distribution
Does text embedding similarity from a vector search also have a non-even distribution? Let’s take the same MSRD dataset of queries and movies, and push it through an all-MiniLM-L6-v2 LLM with SBERT to compute text embeddings. These embeddings can be later used inside a vector search engine like Pinecone. Still, to simplify things, we’re only going to perform an in-memory k-NN search between queries and movie documents and compute the same cosine similarity distribution for top-N documents.
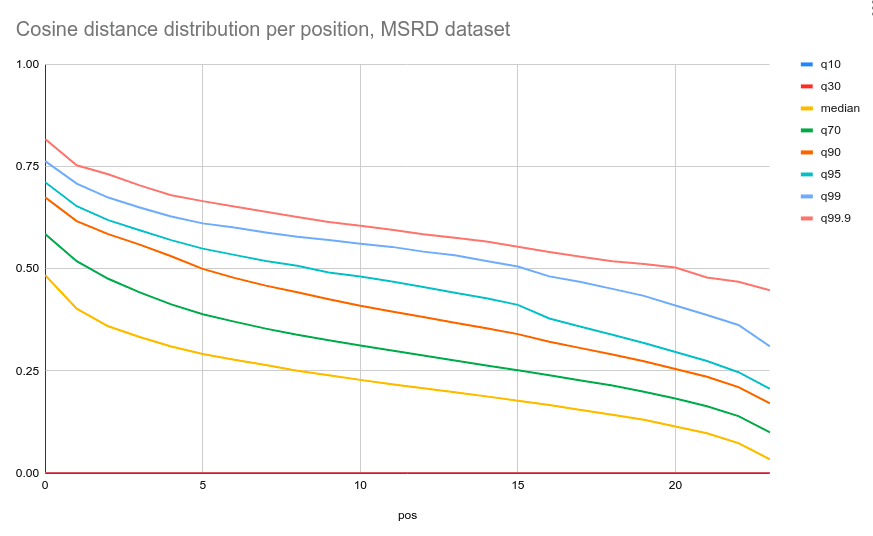
As you can see from the graphs above, the cosine similarity distribution between query-item embeddings is also not that even and differs quite a lot from the BM25 one:
- Thick-tailed,
- Has finite upper and lower bounds,
- Much smaller peak on position-0.
So, what should we do if there’s no simple way to combine multiple rankings in a statistically correct way?
Learning-to-Rank for Multiple Retrievers
From another perspective, BM25 scores and cosine similarity can be treated as input ranking features for a ranking-focused ML model like LambdaMART and implicit customer feedback as labels.
If a visitor clicks on a document, it’s a positive signal; if ignored, it is negative. So we can ask this ML model to figure out the best way to merge both document sets into a single ranking to maximize a standard search relevance metric like NDCG.
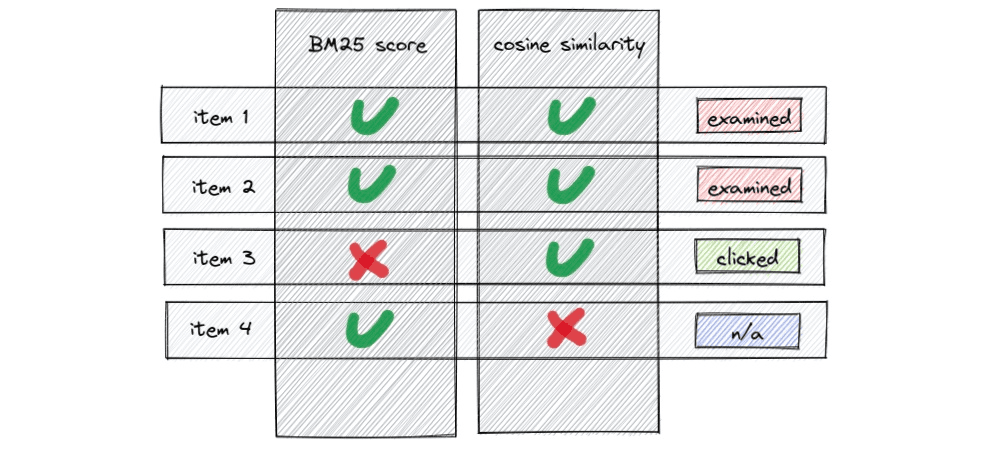
But how does the underlying ML model handle holes in the data when a document comes only from a single source and, for example, has only a BM25 score but not the cosine similarity? There are multiple approaches to solving this problem:
- Replace all null values with an average or median value across the dataset/ranking.
- Use a ranking algorithm that can handle missing values natively, like decision trees - which is a core building block of the LambdaMART Learn-to-Rank algorithm.
All major LambdaMART algorithms implementations like XGBoost, LightGBM, and CatBoost all handle missing values in a very similar fashion. A null is a separate, distinct feature value, which can also be part of a split while building yet another decision tree. In other words, each feature split has a default go-to route for a case when the value is missing.
This approach results in much more stable results for cases when the feature value is sparse, so the majority of its values are missing.
Metarank as a Secondary Re-ranker
Implementing an in-house solution for a LambdaMART-style multi-retriever problem will require you to build a couple of data pipelines:
- Collecting visitor feedback to log all clicks happening in search results.
- Query logging: we should also collect both search queries and all the documents from all retrievers.
- Feature logging: we should persist BM25 and cosine similarity scores for all query-document combinations to use it later during ML model training.
It takes time to build such a system in-house, and such an adventure is not always possible without a team with proper expertise in ranking optimization. But instead of doing everything from scratch, we suggest using existing open-source tools as it may save us quite some time in the whole journey.
Metarank is an open-source project focused on solving common ranking problems. It is flexible enough to be used as a secondary re-ranker for the multi-retriever use case we’re discussing.
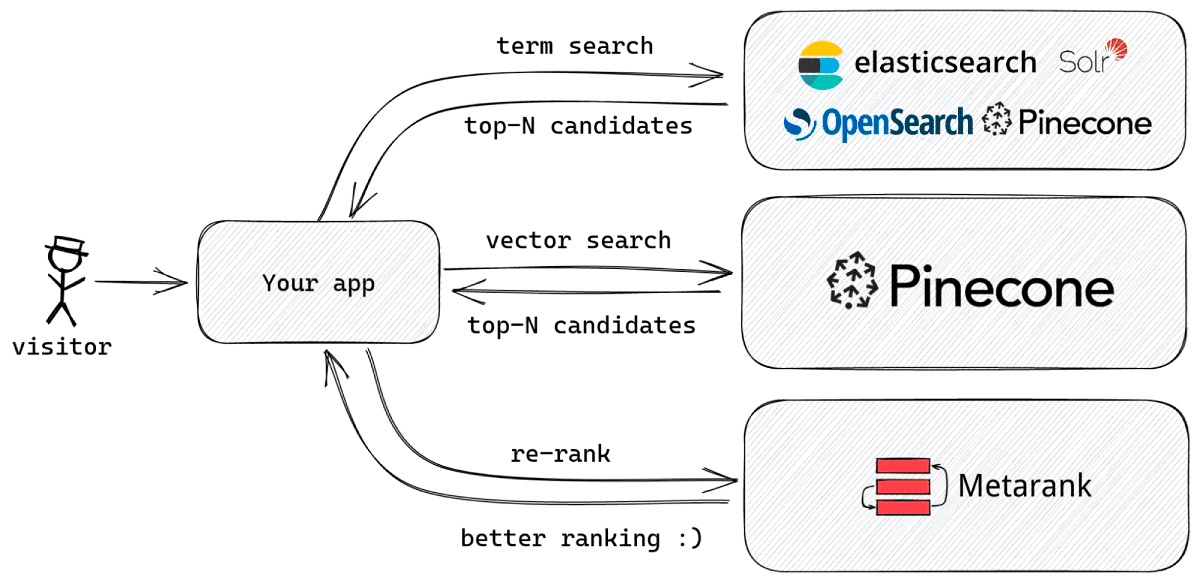
A recent release of Pinecone also supports traditional term search natively, so in some cases you don’t need to configure two separate search engines and just use two different retrieval methods from only a single Pinecone instance.
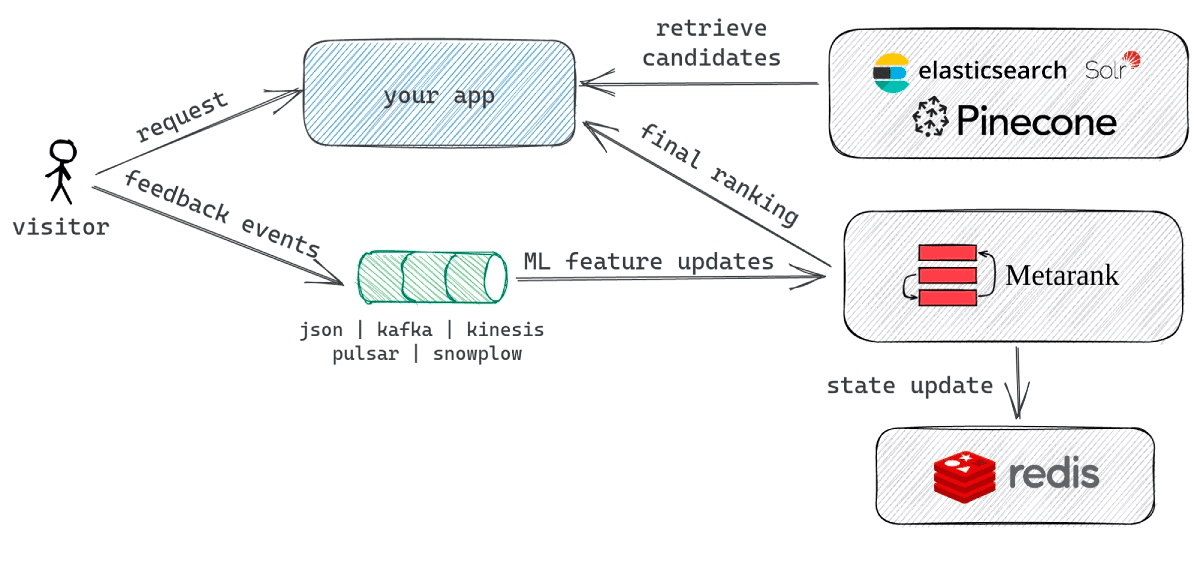
A typical Metarank integration flow consists of three main processes:
- Metarank receives feedback events with visitor behavior, like clicks and search impressions. Historical feedback events are used for ML model training and real-time events for online model inference and re-ranking.
- A backend application receives a search request from a visitor and forwards it to Elasticsearch and Pinecone. Both search result sets are concatenated together without specific ordering and then sent to Metarank for a final ranking.
- Metarank runs the LambdaMART model over the candidate document set and produces the final ranking, which is later presented to the visitor.
Historical Click-through Events
Metarank has a serious limitation (which is not a limitation per se, but more like a functional requirement) that you need to have a history of behavioral data of your visitors to start working on ranking optimization. But like with a chicken-and-egg problem, you need to implement some basic initial unified ranking over multiple retrievers to collect visitor clicks and impressions.
A common approach to this task is interleaving: both result sets are sorted by relevance score and then merged into a single ranking one by one, like a zip line.
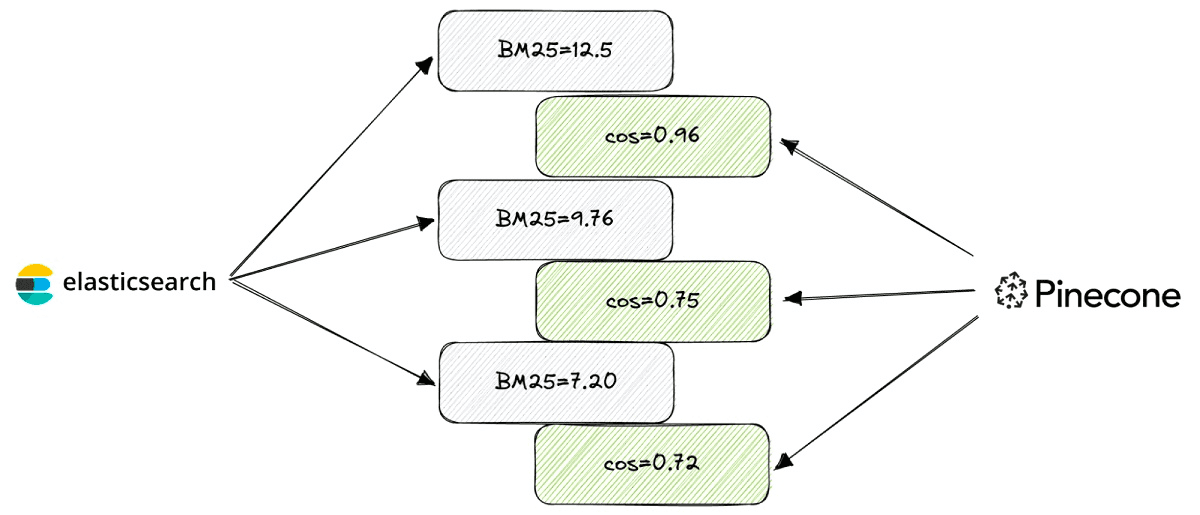
The interleaving process is a great baseline approach: simple enough to implement and hard enough to beat. It can also be extended to support multiple sampling probabilities so that a document may be taken from one of the result sets more frequently than from another.
With a baseline merging strategy, we can start collecting visitor click-through data. Metarank expects to receive three types of events:
- Metadata events about users and items. As we’re not using any user/item-specific information in the ranking process, we can skip emitting these.
- Ranking events: what was presented to a visitor.
- Interaction events: how the visitor reacted to the ranking.
An example ranking event is a JSON object with query information and per-document scores taken from primary search requests. All per-item fields are optional, so in a case when a document was retrieved only by Pinecone and has no BM25 score, skip the field:
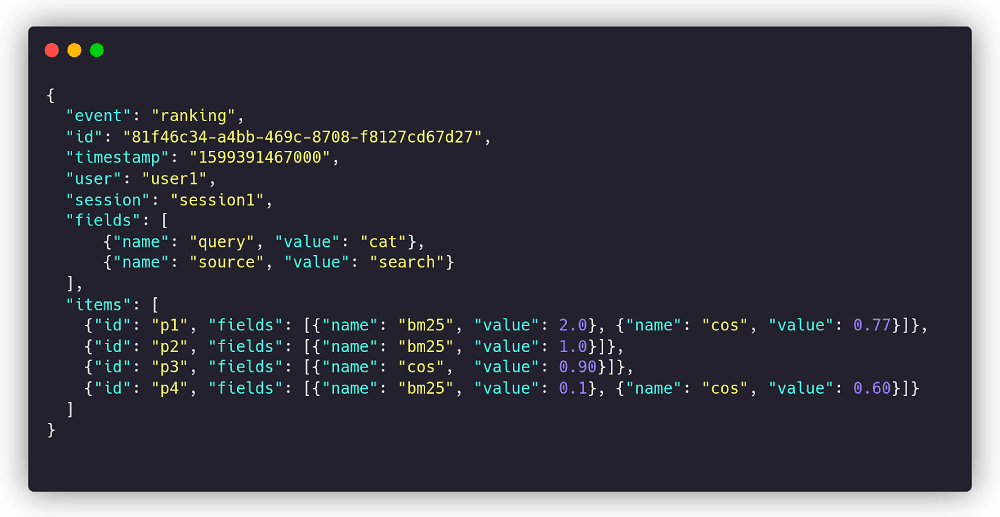
When a visitor makes a click on a document after seeing the ranking, we have to emit an “interaction” event. It describes what was clicked and within which context:
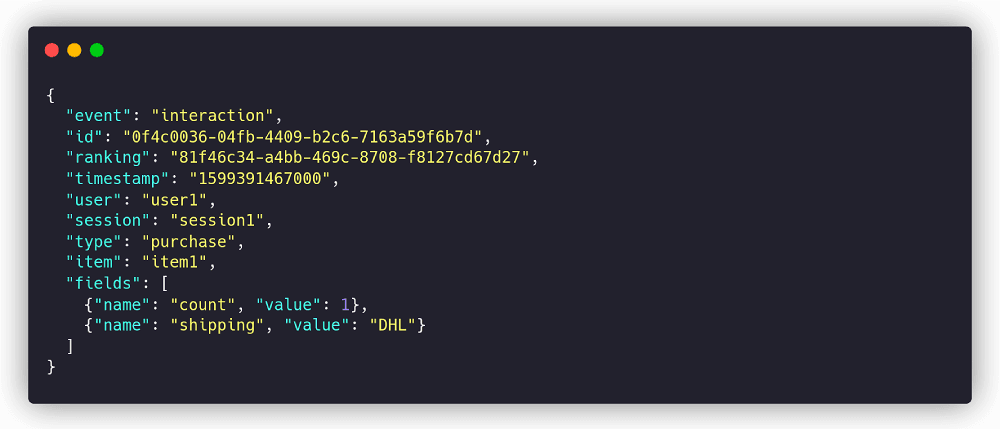
Metarank can pull historical ranking and interaction events from multiple sources (S3 files, Apache Kafka, Apache Pulsar, AWS Kinesis, and GCP Pubsub are supported), so you’re free to choose the best method to collect and store them. There is also an option to use Snowplow Analytics telemetry collector instead of setting up your analytical collection pipeline.
Re-ranking Setup
With click-through event collection in place, we can create a Metarank configuration. The config file consists of four main parts: state, click-through, feature, and model sub-sections.
State configuration. The place where all ranking state about users and items should be stored. Ironically, in our case, all the ranking features are present directly in the re-ranking request. There is no user/item state apart from the ML model itself.
In this guide, we’re going to use an in-memory store, but it’s only useful for demonstrational and development purposes. In a production environment, you should prefer Redis.
Click-through store configuration. Metarank persists a complete click-chain when a visitor clicks on a document. It includes a list of items presented to the visitor, performed interactions, and ranking features used to build the original ranking event. Such events are quite large, and instead of saving all of them in Redis, there are other more cost-effective alternatives.
The click-through store section is optional and by default, uses the main state store to persist click-throughs, so for the sake of simplicity, we’ll omit this.
Feature extractor configuration. How to map semi-structured incoming metadata/ranking/interaction events to the actual ML ranking features.
In our use case, we have only two ranking features, using BM25 and cosine scores supplied by the backend app directly in the ranking request:
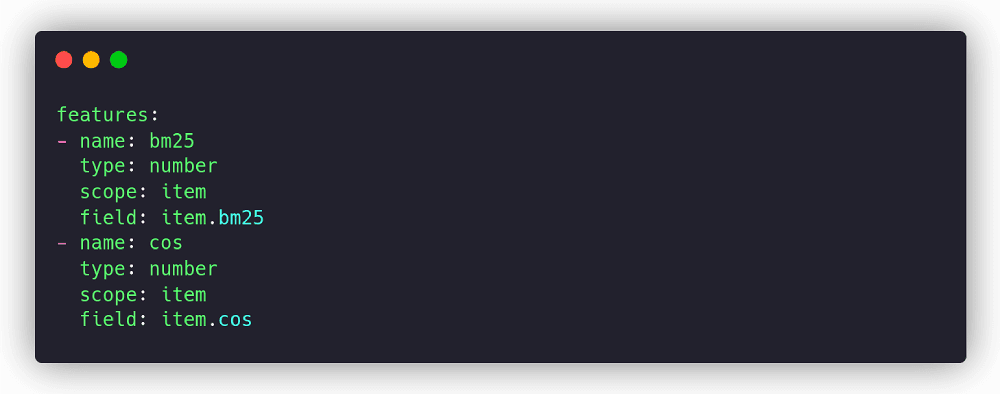
Model configuration. ML model options and used features. Metarank can serve multiple models at once, but in this guide we’ll define only a single “xgboost” model:

Import and Model Training
With a configuration file in place, we can finally invoke Metarank to process the historical data and build the ML ranking model. Metarank can be run as a JVM application with the java -jar command line or as a docker container. We will use the latter in this guide, as it’s more common (but a bit more complicated due to a volume setup).
Metarank has a set of separate sub-commands for data import, model training, and serving (todo: links), but there is a shortcut to run all of them sequentially together, the standalone mode. It’s also not very well suited for production but is extremely useful in simple demos and prototype projects.
docker run -i -t -p 8080:8080 -v <YOUR DIR WITH CONFIG>:/opt/metarank metarank/metarank:latest standalone --config /opt/metarank/config.yml --data /opt/metarank/events.jsonl.gz
Metarank in the standalone mode will import the historical data, train the ranking ML model and switch to the inference mode to serve real-time re-ranking requests.
Sending Requests
When the visitor-facing backend app receives a search request, the request needs to be passed through to the underlying retrievers. So, for example, we can translate a “terminator” query to the following Elasticsearch request:
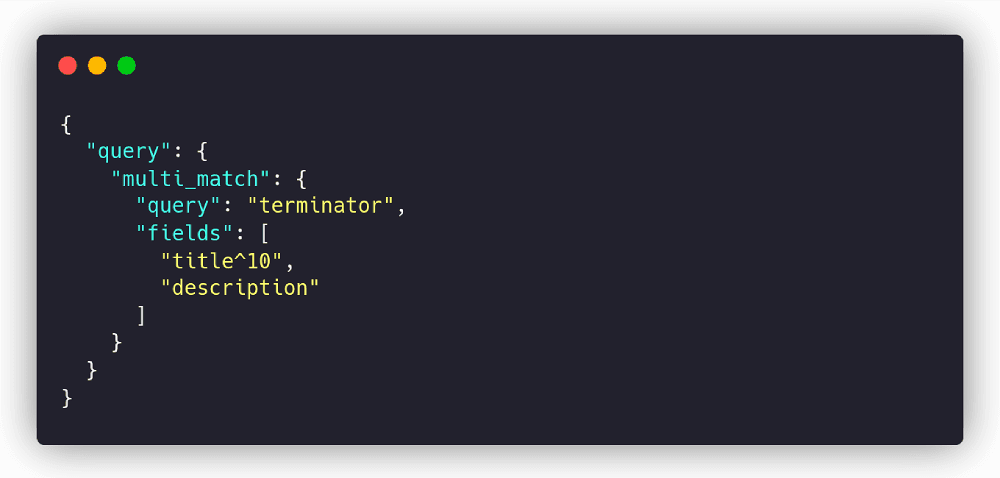
The request must first be converted into a vector representation for a semantic search using your favorite text embedding method. For example, the term “terminator” embedding for a MiniLM model looks like this 384-dimensional vector:
With this vector, we can then query a Pinecone vector search engine for semantically close documents:
Elasticsearch and Pinecone search responses share some of the found documents. We concatenate these responses and send them to Metarank for a final ranking:
And finally Metarank will respond with the final ranking:
Big success!
Next steps
In this article, we attempted to highlight a typical re-ranking setup with Metarank, adapted for a hybrid search with multiple diverse retrievers.
But in the multi-retriever example here, we only used two specific ranking features: BM25 and cosine similarity scores supplied by search engines. Metarank can also do much more, as it can also compute complex behavioral features like:
- Rates: CTR, conversion rate.
- User: User-Agent, GeoIP and Referer
- Profile: interaction history
- Item: price and category.
These ranking features can improve the relevance of the final ranking but require a bit more complicated infrastructure setup: the re-ranking process may become stateful (e.g., the next response depends on the previous one).
Was this article helpful?