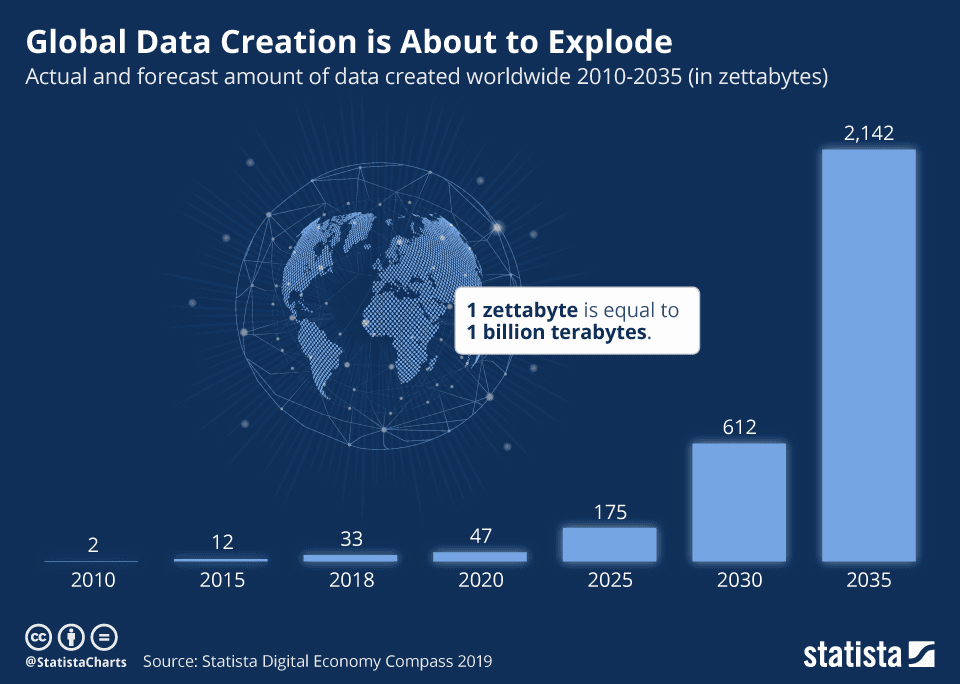
With massive data volumes growing at exponential rates, we need to find scalable methods to process them and find insights. The world of data entered the Zettabyte era several years ago. What’s a Zettabyte? Well, it is enough storage for 30 billion 4K movies, or 60 billion video games, or 7.5 trillion MP3 songs.
Today, the total amount of data created, captured, copied, and consumed globally is in the order of 100 Zettabytes and just keeps growing.
Although this might seem overwhelming, the good news is that we can turn to machines for help: There are many different Machine Learning algorithms to discover patterns in big data that lead to actionable insights.
Depending on the way the algorithm “learns” about data to make predictions, we classify them into two groups, each proving one different type of learning:
- Supervised learning: existing data is already labeled and you know which behavior you want to predict in the new data you obtain.
- Unsupervised learning: there is no output variable to guide the learning process,and data is explored by algorithms to find patterns. Since the data has no labels, the algorithm identifies similarities on the data points and groups them into clusters.
Under unsupervised learning, all the objects in the same group (cluster) should be more similar to each other than to those in other clusters; data points from different clusters should be as different as possible. Clustering allows you to find and organize data into groups that have been formed organically, rather than defining groups before looking at the data.
While this article will focus most closely on K-means, there are other powerful types of clustering that can be used as well. Let’s take a look at the main ones like hierarchical, density-based, and partitional clustering.
Hierarchical Clustering
Cluster assignments are determined by building a hierarchy. This is implemented by either a bottom-up or a top-down approach:
- The bottom-up approach is called agglomerative clustering and merges the two points that are the most similar until all points have been merged into a single cluster.
- The top-down approach is divisive clustering and starts with all points as one cluster and splits the least similar clusters at each step until only single data points remain.
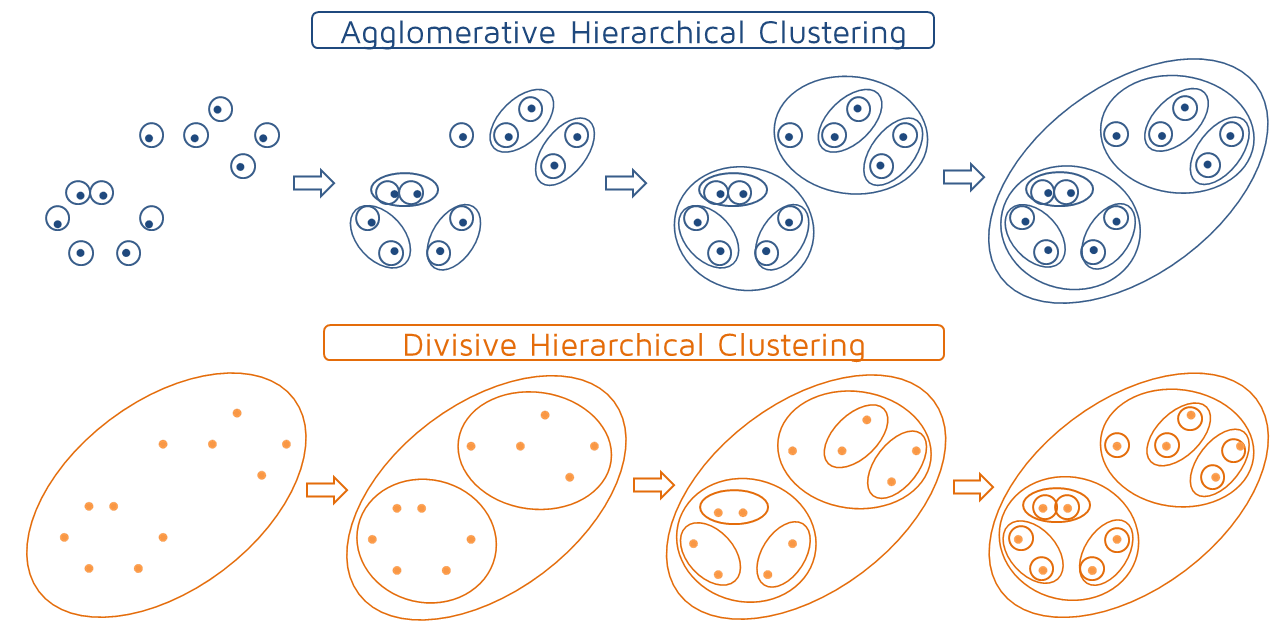
These methods produce a tree-based hierarchy of points called a dendrogram. The number of clusters “k” is often predetermined by the user, and clusters are assigned by cutting the dendrogram at a specified depth that results in “k” groups of smaller dendrograms.
Unlike other clustering techniques, hierarchical clustering is a deterministic process, which means that assignments won’t change when you run an algorithm multiple times on the same input data. Hierarchical clustering methods often reveal the finer details about the relationships between data objects and provide interpretable dendrograms. On the other hand, they’re computationally expensive with respect to algorithm complexity and sensitive to noise and outliers.
Density-Based Clustering
Under this category, cluster assignments are determined based on the density of data points in a region and assigned where there are high densities of data points separated by low-density regions.
Unlike other clustering categories, this approach doesn’t require the user to specify the number of clusters. Instead, there is a distance-based parameter that acts as a tunable threshold and determines how close points must be to be considered a cluster member.
Density-based clustering methods excel at identifying clusters of nonspherical shapes, and they are resistant to outliers. Nevertheless, they aren’t well suited for clustering in high-dimensional spaces (since density of data points is very low in those spaces), and they are not able to produce clusters of differing density.
Partitional clustering
With this method, data objects are divided into non-overlapping groups: No object can be a member of more than one cluster, and every cluster must have at least one object.
Like in hierarchical clustering, the user needs to define the number of clusters “k”, which ultimately produces non-deterministic results: Partitional clustering produces different results from two or more separate runs even if the runs were based on the same input.
This clustering method works very well when clusters have a spherical shape (due to its fixed distance norm), and they’re scalable with respect to algorithm complexity. However, they’re not well suited for clusters with complex shapes and different sizes, and they break down when used with clusters of different densities, since it doesn’t employ density parameters.
K-means is an example of a partitional clustering algorithm. Once the algorithm has been run and the groups are defined, any new data can be easily assigned to the existing groups. K-means is an extremely popular clustering algorithm, widely used in tasks like behavioral segmentation, inventory categorization, sorting sensor measurements, and detecting bots or anomalies.
K-means clustering
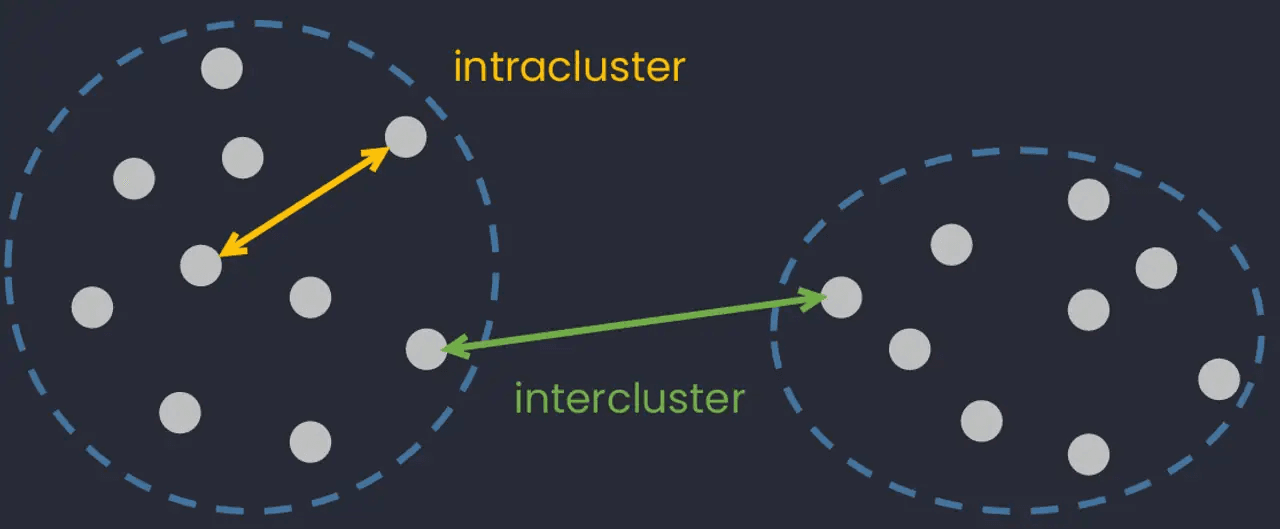
From the universe of unsupervised learning algorithms, K-means is probably the most recognized one. This algorithm has a clear objective: partition the data space in such a way so that data points within the same cluster are as similar as possible (intra-class similarity), while data points from different clusters are as dissimilar as possible (inter-class similarity).
In K-means, each cluster is represented by its center (called a “centroid”), which corresponds to the arithmetic mean of data points assigned to the cluster. A centroid is a data point that represents the center of the cluster (the mean), and it might not necessarily be a member of the dataset. This way, the algorithm works through an iterative process until each data point is closer to its own cluster’s centroid than to other clusters’ centroids, minimizing intra-cluster distance at each step. But how?
K-means searches for a predetermined number of clusters within an unlabelled dataset by using an iterative method to produce a final clustering based on the number of clusters defined by the user (represented by the variable K). For example, by setting “k” equal to 2, your dataset will be grouped in 2 clusters, while if you set “k” equal to 4 you will group the data in 4 clusters.
K-means triggers its process with arbitrarily chosen data points as proposed centroids of the groups and iteratively recalculates new centroids in order to converge to a final clustering of the data points. Specifically, the process works as follows:
- The algorithm randomly chooses a centroid for each cluster. For example, if we choose a “k” of 3, the algorithm randomly picks 3 centroids.
- K-means assigns every data point in the dataset to the nearest centroid, meaning that a data point is considered to be in a particular cluster if it is closer to that cluster’s centroid than any other centroid.
- For every cluster, the algorithm recomputes the centroid by taking the average of all points in the cluster, reducing the total intra-cluster variance in relation to the previous step. Since the centroids change, the algorithm re-assigns the points to the closest centroid.
- The algorithm repeats the calculation of centroids and assignment of points until the sum of distances between the data points and their corresponding centroid is minimized, a maximum number of iterations is reached, or no changes in centroids value are produced.
Finding the value of K
How do you choose the right value of “k”? When you define “k” you are telling the algorithm how many centroids you want, but how do you know how many clusters to produce?
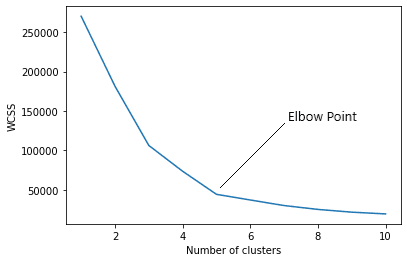
One popular approach is testing different numbers of clusters and measuring the resulting Sum of Squared Errors (SSE), choosing the “k” value at which an increase will cause a very small decrease in the error sum, while a decrease will sharply increase the error sum. This point that defines the optimal number of clusters is known as the “elbow point”.
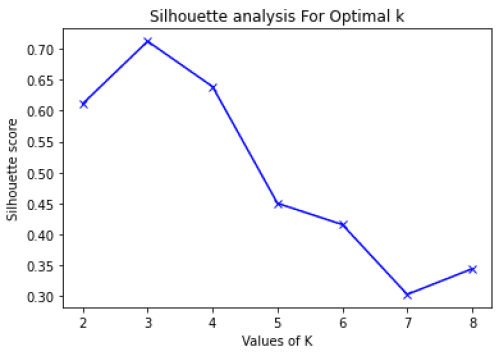
Another alternative is to use the Silhouette Coefficient metric. This coefficient is a measure of cluster cohesion and separation, frequently used in unsupervised learning problems. It quantifies how well a data point fits into its assigned cluster based on two factors:
- How close the data point is to other points in the cluster
- How far away the data point is from points in other clusters
Silhouette coefficient values range between -1 and 1, meaning that well-defined clusters result in positive values of this coefficient, while incorrect clusters will result in negative values.
We can use a Silhouette plot to display a measure of how close each point in one cluster is to a point in the neighboring clusters and thus provide a way to assess parameters like the number of clusters visually.
When to Use K-Means Clustering
K-means presents huge advantages, since it scales to large data sets, is relatively simple to implement, guarantees convergence, can warm-start the positions of centroids, it easily adapts to new examples, and generalizes to clusters of different shapes and sizes, such as elliptical clusters.
But as any other Machine Learning method, it also presents downsides. The most obvious one is that you need to define the number of clusters manually, and, although we showed some ways to find the optimal “k”, this is a decision that will deeply affect the results.
Also, K-means is highly dependent on initial values. For low values of “k”, you can mitigate this dependence by running K-means several times with different initial values and picking the best result. As “k” increases, you need advanced versions of K-means to pick better values of the initial centroids (called K-means seeding). K-means produces clusters with uniform sizes (in terms of density and quantity of observations), even though the underlying data might behave in a very different way. Finally, K-means is very sensitive to outliers, since centroids can be dragged in the presence of noisy data.
K-means is highly flexible and can be used to cluster data in lots of different domains. It also can be modified to adapt it to specific challenges, making it extremely powerful. Whether you’re dealing with structured data, embeddings, or any other data type, you should definitely consider using K-means.
Was this article helpful?