
Last week we announced a major update. The incredible work that led to the launch and the reaction from our users — a combination of delight and curiosity — inspired me to write this post. This is a glimpse into the journey of building a database company up to this point, some of the internal debates and decisions we made along the way (bad and good alike), and on-going innovation at the core of Pinecone that I find exciting.
In-memory graph-based index
In May 2010, I wrote Professor Yuval Rabani an email. Yuval is one of the inventors of approximate nearest neighbor (ANN) search as a concept. I suggested we work together on answering a seemingly simple question:
“Why are graph based data structures so good at vector search?”
You see, they were much better in practice than the theory predicted they should be. This hinted that we were lacking some fundamental understanding of either vector search or graph based indexes (or both). We decided to analyze the behavior of vector search with graphs using mathematical machinery from a different domain. Specifically, those spearheaded by Dan Speilman for bounding the running time of solving systems of linear equations (for the CS theoreticians, think about max-dot product search and its similarity to the simplex method, and it will make more sense). We made some progress with this approach, but never quite got a full answer. Graph based vector search still seemed to be “too good”.
Fast forward twelve years, graph based techniques now take center stage for vector search software. These include HNSW by Yuri Malkov (an advisor to Pinecone), implementations in Faiss, and a flurry of further research and software progress. It was therefore only natural for Pinecone to consider using graph indexes for its vector database.
Bringing graph based search into a production-grade database, however, was not going to be simple. As a managed database, we have to make sure our systems always work and without the user tweaking and experimenting with different configurations. We could not afford to have best-effort-heuristics and magic-constants floating around. We also knew we needed to efficiently combine metadata filtering and graph traversal, optimize updates and deletes, and other functionality which HNSW or Faiss do not provide.
In the end, we did it. It took many months of work by Pinecone’s technical leaders Marek Galovic, Roei Mutay, and Ram Sriharsha along with Yuri Malkov. We now have a high-performance, stable, fully dynamic, and filterable graph index!
However, my curiosity from twelve years ago hasn’t diminished one bit. There is still so much we don’t know. Under what conditions can we guarantee the convergence of the search method? Can we check in advance what datasets are good for graph based indexes? Can we reliably prune graphs and keep their search effectiveness? I truly hope to be able to make some progress on these questions soon.
A new storage engine for vectors
Because Pinecone is a managed vector database and not just an index, we need to take care of storage and persistence of the data in every index. We also need to constantly update and fetch thousands of raw vectors in milliseconds. Think about batch updates (upserts), raw vector-metadata fetch operations, and most importantly, raw exact comparisons between queries and candidate matches suggested by the ANN vector search index. We need an object storage engine.
We originally chose RocksDB for that. RocksDB is commonly used as an embedded layer in other database offerings. And, developing a completely new storage engine seemed like an insurmountable effort; the specter of data-loss looms big in our collective psyche.
We were very happy with our decision. We loved RocksDB. It is a great piece of software. It was 100% the right choice, until it wasn’t…
When we tried to vertically scale our pods, we started hitting RocksDB limits. Write throughput became a big issue. Simultaneous fetches of thousands (sometimes tens of thousands) of objects started becoming inefficient, especially when fetching from collections of tens of millions of objects. The fetch latency variance also grew. Higher p99 latencies started leaking into our p50s when operating horizontally distributed indexes. Write amplification started really hurting our pods’ capacities… To make matters worse, we were also spending a ton of time and energy grappling with RocksDB trying to maximize our performance.
Late last year, our VP of Engineering, Ram Sriharsha, came up with a brillant bitcask-like design for a completely new vector store that is optimized for random multigets and updates, low fetch variance, minimal storage overhead, and maximal operational simplicity.
Marek and Ram took on the herculean challenge to build the initial new vector store (internally nicknamed memkey). The resulting object store is up to 10x faster than RocksDB on large datasets. It reduces our overall operating costs 30-50%. We passed these improvements on to our customers when we updated p1 and s1 pods to use the new vector store. Customers will seamlessly get more capacity and lower latency without changing a single line of code on their end. How cool is that?
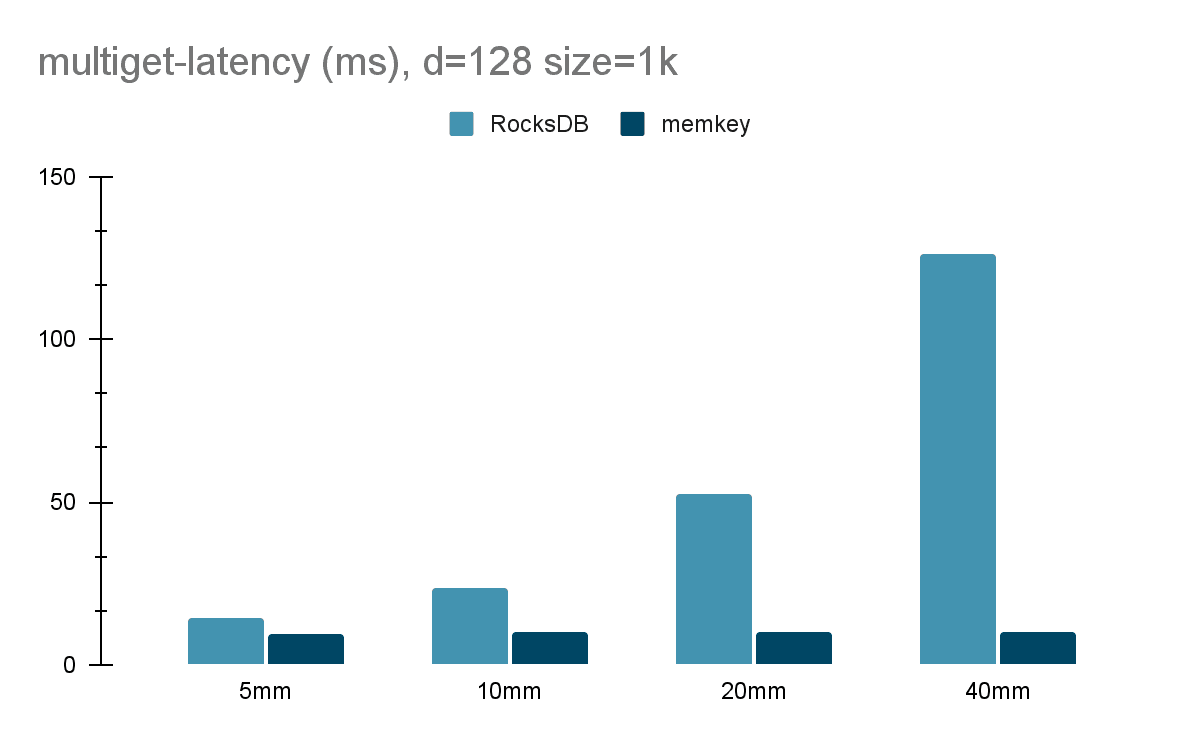
Memkey’s low (and flat!) multiget latency as collections grow compared to RocksDB. On the y-axis: Multiget times in milliseconds for fetching 1000 random objects (vectors) from local SSD. On the x-axis: Collection size being 5m, 10mm, 20m, and 40mm.
Rust: A hard decision pays off
Although this change was implemented inside Pinecone a while ago, this is the first time we’re talking about it publically.
In the beginning, Pinecone was built with a mix of C/C++ and Python. The argument for this went something like this: a C/C++ core will be highly efficient, and experienced C/C++ engineers are easy to find. Anything not at the core doesn’t have to be efficient. It can therefore be easily and quickly delivered in Python, which sacrifices running speed with easy development. It was, indeed, relatively easy to develop, and we got some impressive results pretty quickly. So, that seemed to be the winning formula. We went for it full tilt.
Not until a few weeks before a big release last year did the number of issues we had to fix begin to pile up. We kept fixing one issue only to discover (or create) another. Every few hours we would find some major bug or oversight in our codebase; and each cycle to fix and redeploy took hours of work. To make matters worse, we would discover issues only after deploying (or in production!) due to Python’s run time nature. Sometimes these would be minor bugs that any compiler would have easily flagged, and sometimes they were complex runtime issues which were almost impossible to reproduce or isolate.
That’s when internal murmurs about a complete rewrite started brewing…
I personally vehemently resisted the idea. Rewrites are notoriously dangerous. They feel exciting at first, but often turn sour. First, they always end up being much bigger projects than you plan for. This is especially dangerous in a startup where a significant delay in shipping new features could be your undoing. Second, rewrites often backfire in spectacular ways; the new codebase often produces completely new challenges, often much worse than those you originally had.
Nevertheless, we reached a tipping point. We decided to move our entire codebase to Rust (and Go for the k8s control plane). Rust seemed to give us all the capabilities we needed, however, there was still one minor problem - no one on the team knew Rust. It was (and still is) a hard-to-master, young language with a much smaller community than either C++ or Python.
We started with a small team of senior engineers and managers learning Rust and developing the skeleton of the DB and dev environment (for others to build on). Then, slowly, others joined in rewriting and contributing different components until we eventually got rid of the old codebase altogether (I still remember the day my original C modules, from the first days of Pinecone, were taken out). Unbeknownst to most Pinecone customers, the new Rust core was deployed in March this year. And in the process of taking over running workloads, we managed not to drop a single API call!
So, what did we learn? We all expect performance and dev processes to improve. Those indeed happened. What we didn’t expect was the extent to which dev velocity increased and operational incidents decreased. Dev velocity, which was supposed to be the claim to fame of Python, improved dramatically with Rust. Built-in testing, CI/CD, benchmarking, and an overzealous compiler increased engineers’ confidence in pushing changes, and enabled them to work on the same code sections and contribute simultaneously without breaking the code base. Most impressively though, real time operational events dropped almost to zero overnight after the original release. Sure, there are still surprises here and there but, by and large, the core engine has been shockingly stable and predictable.
Note: Interested in hearing more about our Rust rewrite? Don’t miss our talk at the NYC Rust meetup on August 31, and subscribe for updates at the bottom of this page to get notified when we post the full writeup.
Closing thoughts
While I could keep rambling on about more exciting developments within the space like vertical scaling, data collections, more advanced monitoring, and others, those will have to wait until the next post.
If building the best vector database in the world sounds exciting, give me a ping. We are hiring on all fronts. Also, if you are building on Pinecone and missing a feature or experiencing something other than expected, please don’t be shy and write to me directly (edo@pinecone.io).
Was this article helpful?