Falcon 180B is a 180-billion-parameter Large Language Model (LLM). It has comparable performance to Google's PaLM 2 (Bard) and is not far behind GPT-4.
It is touted as the "Llama 2" killer due to its higher performance as a pretrained-only model. As of September 2023, Falcon 180B ranked as the highest-performing pretrained LLM on the Hugging Face Open LLM Leaderboard.
The model is big. Inference requires 640GB of memory — a mere eight A100 80GB GPUs — when quantized to half-precision (FP16). Alternatively, we can quantize down to int4, requiring eight A100 40GB GPUs (320GB memory). That can easily put you back $20K / month if you keep it online.
For some, this price tag may be worth it. Falcon 180B's license permits commercial usage and allows organizations to keep their data on their chosen infrastructure, control training, and maintain more ownership over their model than alternatives like OpenAI's GPT-4 can provide.
Performance-wise, Falcon 180B is impressive. It is the highest-performing open-access LLM and is comparable the PaLM-2 Large (which powers Bard).
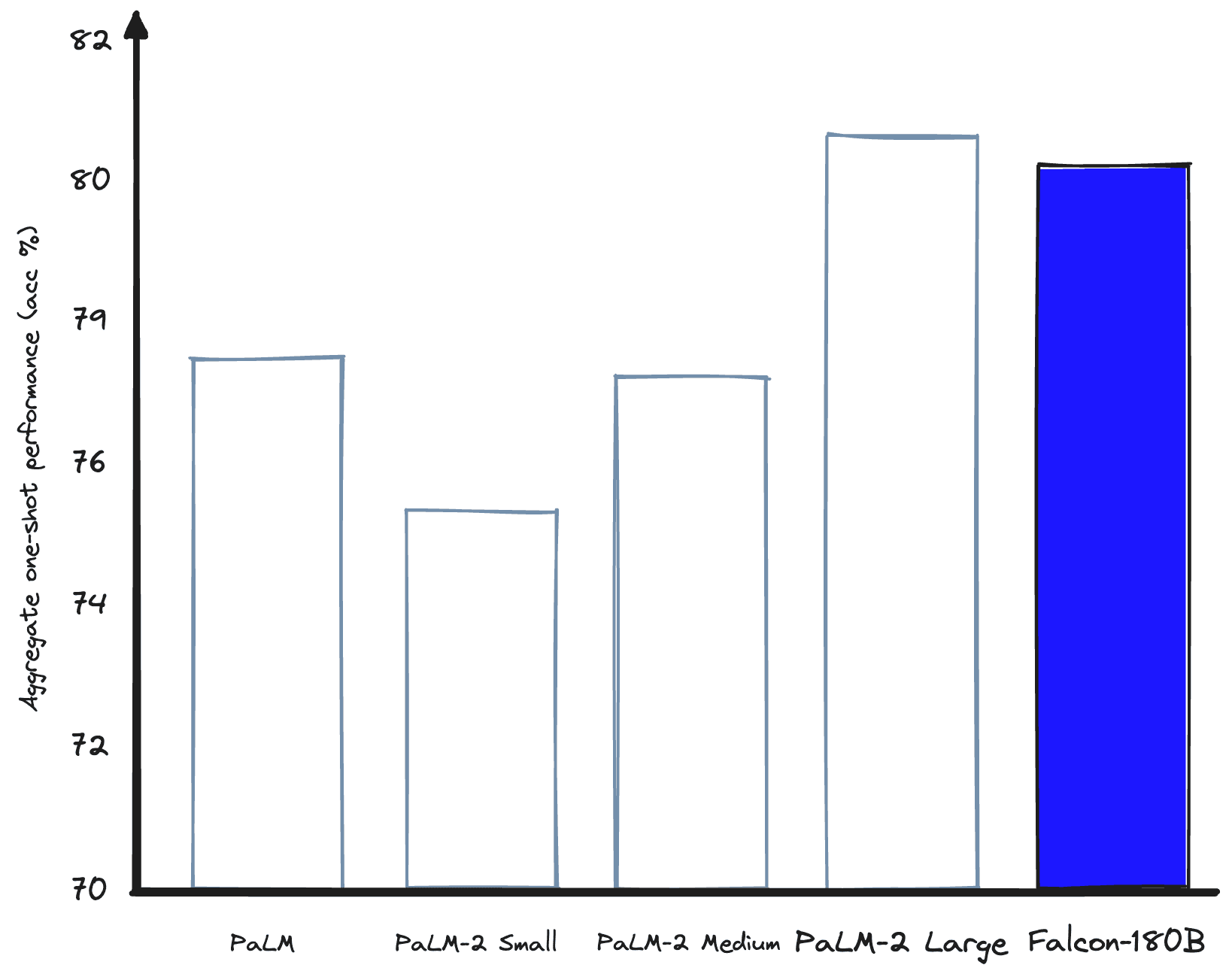
Compared to OpenAI's models, Falcon 180B outperforms GPT-3.5 on some benchmarks. For the majority of benchmarks, Falcon 180B scores between GPT-3.5 and GPT-4 [1].
We will be adding further information and guides surrounding Falcon 180B to this page — so stay tuned!
References
[1] P. Schmid, O. Sanseviero, P. Cuenca, L. von Werra, J. Launay, Spread Your Wings: Falcon 180B is here (2023), Hugging Face Blog
Was this article helpful?