Putting the Pieces Together
LLMs are getting better, faster, and smarter, and as they do, we need new ways to use them.
Applications people build with them have transitioned from asking LLMs to write to letting LLMs drive actions. With that, comes new challenges in developing what are called agentic applications.
Context engineering is a term that attempts to describe the architecting necessary to support building accurate LLM applications. But what does context engineering involve?
Hallucinations Constrain AI Applications
Much has been made of the potential of agents to complete tasks and revolutionize industries. Still, if there’s one thing that has passed the test of time, it’s that LLM applications will always fail without the relevant information. And in those failures, come hallucinations.
Multiple tool calls, messages, and competing objectives blur instructions in agentic applications. Due to these diverse integrations all competing for a fixed (literal!) attention span for a model, a need arises for engineering their integration. Absent this, models default to their world knowledge and information to generate results, which can result in unintended consequences.
Context engineering is an umbrella term for a series of techniques to maintain the necessary information needed for an agent to complete tasks successfully. Harrison Chase from LangChain breaks down context engineering into a few parts:
- actions the LLM can take (tool use)
- instructions from the user (prompt engineering)
- data related to the task at hand, like code, documents, produced artifacts, etc (retrieval)
- historical artifacts like conversation memory or user facts (long and short term memory)
- data produced by subagents, or other intermediate task or tool outputs (agentic architectures)
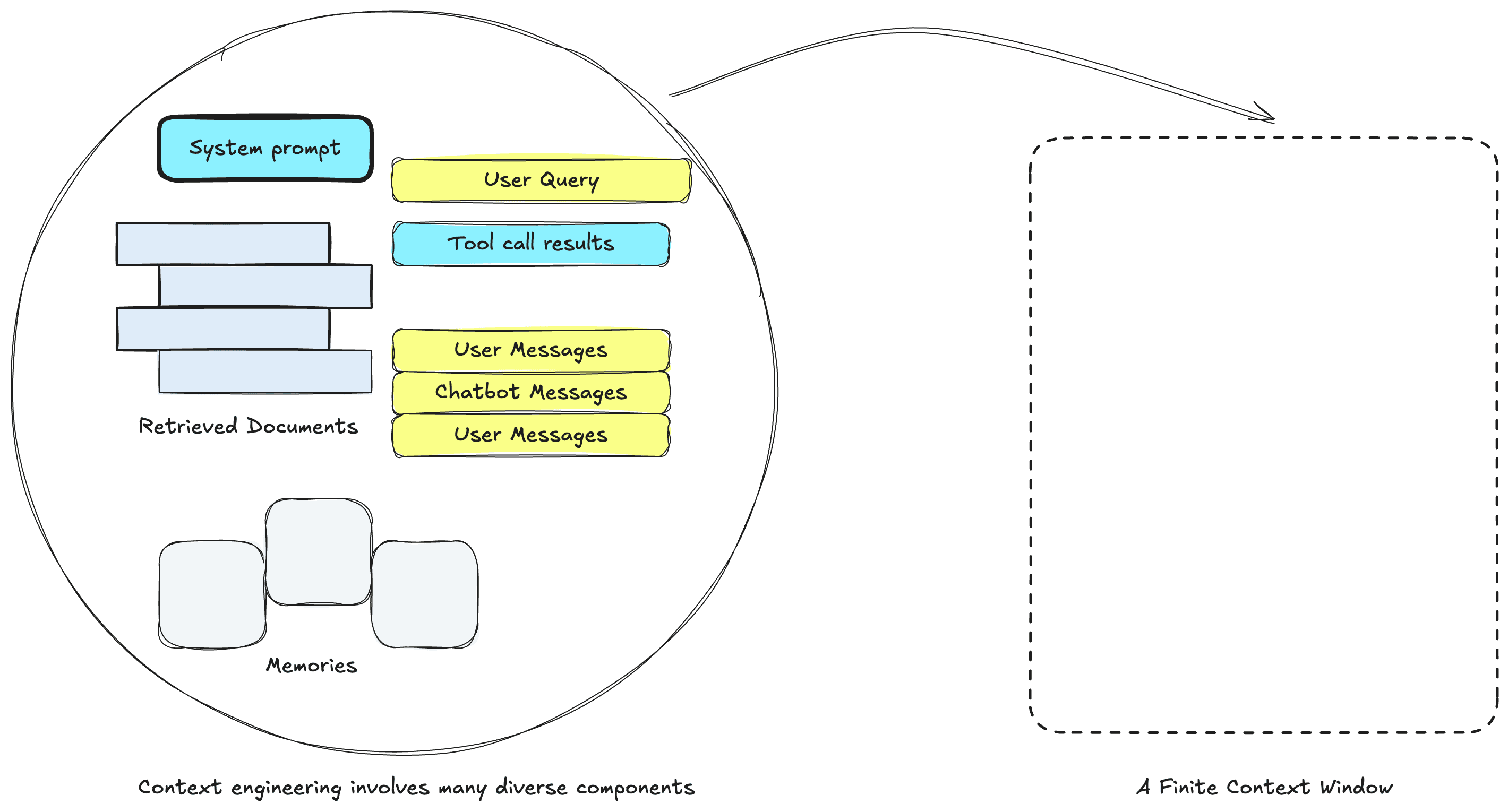
All of these must fit into a finite context window for applications to succeed.
Retrieval and vector databases are uniquely impactful for these applications, as they help retrieve the external information in various modalities and representations necessary to ground responses with context. But just having the context isn’t enough.
Organizing, filtering, deleting, and processing this information so that an LLM can continue to focus on the task at hand is context engineering.
Applying Lessons from Retrieval-augmented Generation to Context Engineering
Now if you’re reading this far, you might think, oh no!! Another technique for the aspiring AI engineer to learn, the horror! How will you ever catch up!?!
Not to fear. If you’ve built any search or retrieval-augmented generation application before, you already know a lot of the principles for context engineering! In fact, we can make the argument that context engineering is just a step-up abstraction of prompt engineering for RAG applications.
How, you ask?
Imagine you’ve built an application for helping answer incoming customer support tickets. It’s architected as follows:
- Take an incoming user query, and query your semantic search which indexes documents from your company
- pass the retrieved context to an LLM, like Claude or OpenAI
- Answer user queries using the context
Accordingly, the application has access to a knowledge base of information that might include previous support tickets, company documentation, and other information critical to respond to users.
You might use a prompt like this:
You are a customer support agent tasked with helping users solve their problems.
You have access to a knowledge base containing documentation, FAQs, and previous support tickets.
Given the information below, please help the user with their query.
If you don't know the answer, say so and offer to create a support ticket.
INSTRUCTIONS:
Always be polite and professional
Use the provided context to answer questions accurately
If the information needed is not in the context, acknowledge this and offer to create a support ticket
If creating a ticket, collect: user name, email, issue description, and priority level
For technical questions, provide step-by-step instructions when possible
CONTEXT: <retrieved docs>
USER QUERY: <user query>
Please respond in a helpful, conversational manner while remaining factual and concise.In that prompt, you’d balance how to drive the LLM’s behavior, manage the documents retrieved from the user query, and provide any additional information necessary for the task at hand.
It’s a great proof-of-concept that quickly delivers answers to frustrated users. But, you have a new requirement now:
Build a chatbot that can manage support tickets given user queries
Specifically, the chatbot must be turned into an agent that can:
- Maintain a conversation with users and extract key information from them for the tickets
- Open, write to, update, and close support tickets
- Answer tickets that are in-domain or available in a knowledge base or previous tickets
- Route the tickets to an appropriate customer support personnel for follow-up
The LLM must reason and act instead of just responding. It must also maintain information about a given set of tickets over time to provide a personalized user experience.
So, how do we go about doing this?
We might need some of the following:
- Tool Use, to enable writing and closing tickets
- Memory, to understand user needs and maintain key information over time, as well as to summarize and manage information over time
- Retrieval, to modify user queries to find documentation and information over time
- Structured Generation, to properly extract information for tickets, or to classify and route tickets to employees
- Compaction, Deletion, and Scratchpads to maintain, remove, and persist temporary information over time
All of these additional capabilities consume significant context over time, and warrant additional data structures, mechanisms, programming, and prompt engineering to smooth out capabilities.
Fortunately, prompt engineering for RAG incorporates many lessons you’d need to help tackle this problem.
We know that all embedding models and LLMs have limits to the amount of information they can process in their context window, and that the best way to budget this window is via chunking.
Furthermore, you may be familiar with reranking, which allows you to refine relevant documents sets down to more manageable sizes, to reduce cost, latency and hallucination rates.
Here, we can see how summarization and reranking can prune context down for future conversational turns.
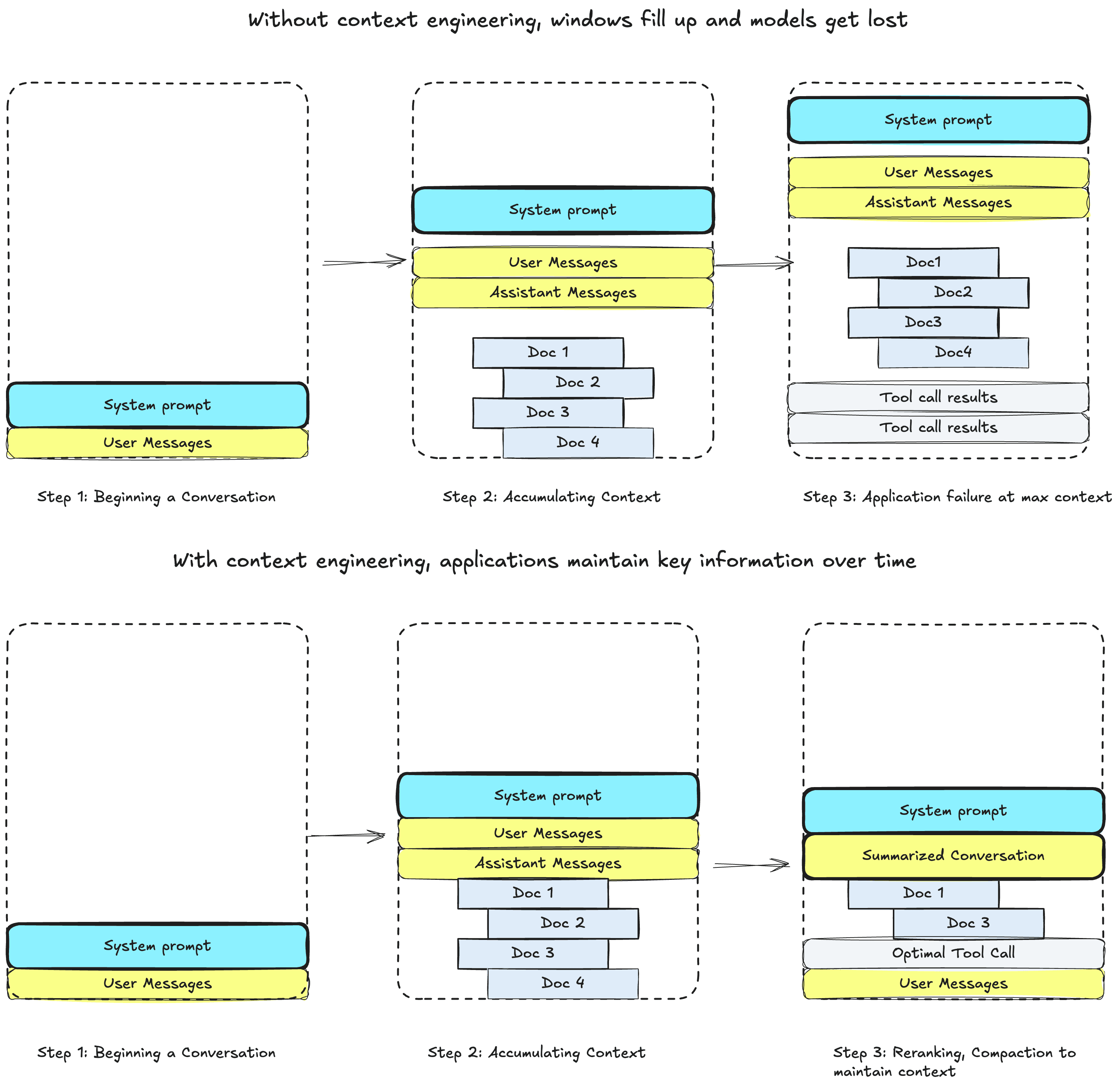
And, if you are building agents, you might even know about the importance of letting your agent control queries to an external vector database via a tool or MCP server, which lets it determine the appropriate questions to ask for the task at hand.
All of these techniques help you generate accurate responses given a user’s query. For more examples of how this is achieved in practice, read Dexter Horthy’s great writeup on context engineering in prompts, or Drew Breunig’s write up on fixing context issues here.
But, user’s might make multiple queries. They might ask for revisions on existing information, or for you to get new information for the current task. They want their problems solved, not just explained. This is where an agentic architecture becomes necessary, and context engineering starts to become a useful concept.
How Context Engineering informs Agentic Architectures
As you build this system, you get some feedback from your coworkers:
Your current implementation relies on a single agent interacting with the user. This creates a bottleneck where the agent must wait on tool calls or user input to do certain things. What if we implemented a subagent architecture instead?
In other words, instead of having a single LLM instance make tickets, route requests, and maintain a conversation with users, our LLM could delegate tasks to other agents to complete asynchronously.
This would free up our “driving” LLM instance to continue conversing with our frustrated customer, ensuring lower latencies in a domain where every second matters.
Great idea! But, context engineering gives us a framework to think about the benefits of these kinds of parallelized architectures versus sequential ones.
Anthropic and Cognition both wrote about the tradeoffs that come with these, concluding that for read-heavy applications (like research agents) or certain technical ones (code agents), a sequential agentic architecture may be easier to maintain context with than one that involves subagents. This mostly comes down to engineering the context gained and lost over the course of the agent’s work, as well as eschewing multi-agent architectures due to the difficulty of maintaining context over multiple agent runs.
Try your hand at context engineering with Pinecone
Only after perfecting the art of optimizing this information can you focus on architecting agentic applications.
Prompt engineering for RAG helps you answer a user’s initial query well. Context engineering ensures users have great experiences with subsequent queries and tasks.
Ready to practice your context engineering skills? Take a look at our example notebooks, such as our LangGraph retrieval agent located here to get started learning!
Was this article helpful?