Exploring the Pinecone AWS Reference Architecture
The Pinecone AWS Reference Architecture is the best way to go to production with a high-scale system using Pinecone’s vector database. It has been tested with hundreds of thousands to millions of records and is an excellent starting point for your next cloud system that needs to embed and query large amounts of data.
This post covers our primary technical considerations while building the Reference Architecture. You can find our Reference Architecture launch announcement post here.
We will also explain each component in detail and how they all work in concert to expose a live-updating semantic search example application to end users.
Pinecone AWS Reference Architecture goals
The primary goal of our Reference Architecture project is to be the ideal starting point for teams who want to go to production with a non-trivial, high-scale application that leverages Pinecone’s vector database.
While our many open-source Jupyter notebooks and example applications are ideal for learning new AI techniques, understanding how to implement them in code, and getting started with similar use cases, the Reference Architecture is designed for production and teams that use Infrastructure as Code to deploy their systems to AWS.
The Reference Architecture must also be easy to deploy and as easy as possible to understand and change so that users can tweak the stack to their liking or fork our starting point to more quickly and easily deploy a new system.

The Reference Architecture attempts to strike the right balance between demonstrating a non-trivial use case end-to-end and best practices for Pinecone and AWS while being generic enough that it’s modifiable to fit most use cases.
We defined our first AWS Reference Architecture using Pulumi and TypeScript for these reasons.
What does the Pinecone AWS Reference Architecture deploy?
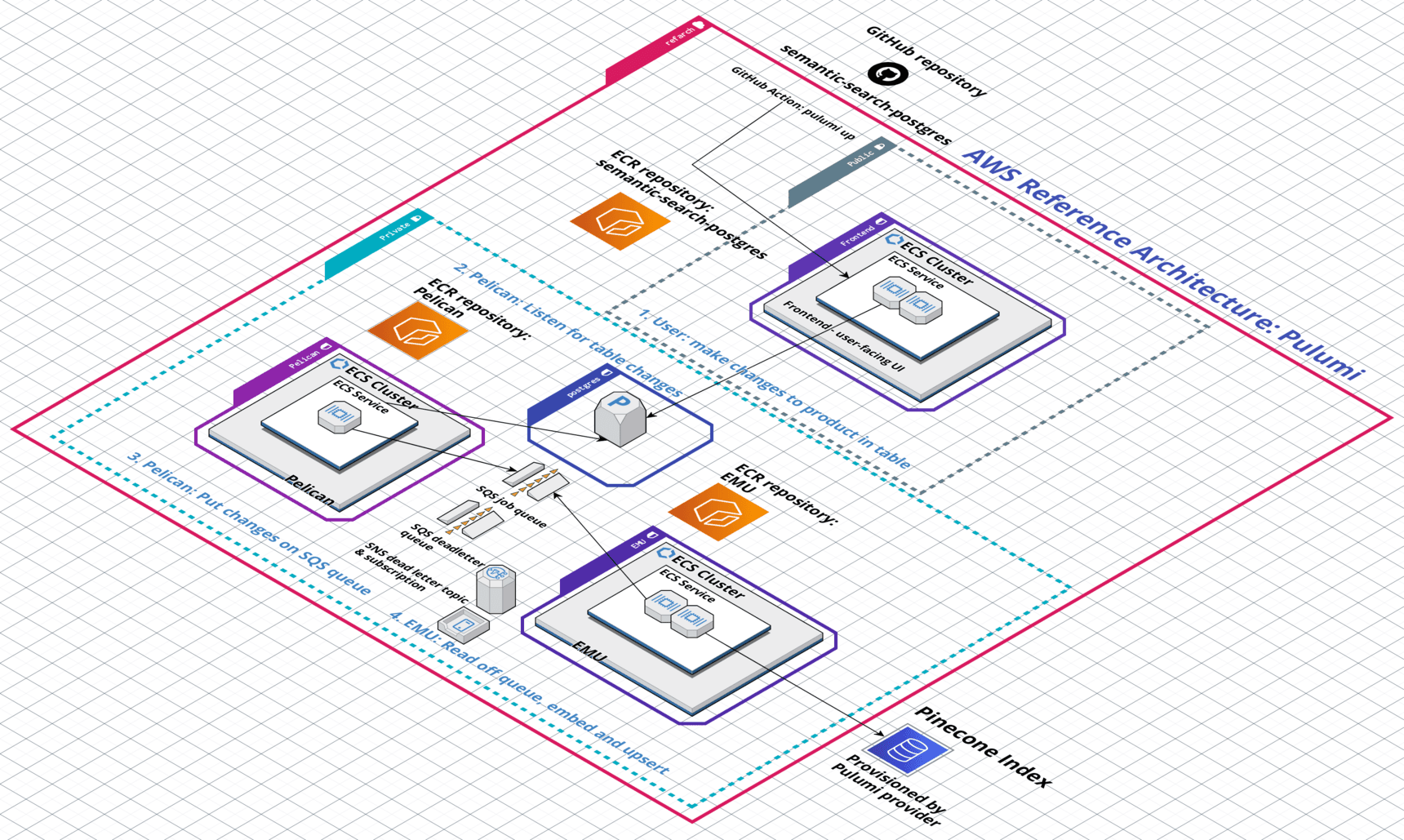
The Reference Architecture’s example application is a semantic search interface over a Postgres database of product records, leveraging Pinecone’s vector database for queries and instant index updates.
This architecture allows end users to efficiently search through large volumes of database records using ambiguous natural language queries.
Pinecone’s index stores vectors representing the product descriptions in Postgres and contains the Postgres record ID for each product in their metadata, connecting the end-user’s ambiguous natural language queries with the structured data of the Postgres products database.
The microservices
The Reference Architecture comprises three microservices:
- a frontend service that exposes the user-facing semantic search user interface
- a database-change-monitoring microservice named Pelican
- a dedicated embedding and upserting microservice named Emu
The front end exposes a table view to end users, allowing them to search over and live-edit a corpus of fake product information stored in a central RDS Postgres database.
When a user searches for a type of product, for example, by typing “AI,” - their query is converted to a query vector, then passed to the Pinecone index to search for matching records.
When the Reference Architecture is first deployed, the Pelican database-change-monitoring microservice wakes up and determines that it needs to load all records from Postgres into Pinecone, which it does by adding all Postgres records onto the shared SQS jobs queue.
This causes the Emu microservice to pick up the jobs and begin processing them, converting each record’s description into embeddings and upserting the whole record into the Pinecone index, along with metadata that stores the original Postgres record’s ID in the Postgres database.

This metadata link allows the system to instantly translate between the end user’s ambiguous natural language queries, such as “AI,” to the exact product records in the RDS Postgres database that might have “artificial intelligence” in their descriptions.
Once this initial data bootstrapping routine is complete and all the Postgres records are stored as embeddings in the Pinecone index, the Pelican microservice shifts into monitoring mode.
Whenever an end-user modifies a product record in the UI table view, that change is sent to Postgres, triggering a notification via pg_notify which Pelican is listening for. Pelican takes the changed record and places it on the SQS queue, so that the Emu microservice can pick it up, embed the product description and upsert the vector and associated metadata to the Pinecone index, keeping everything in sync.
Docker builds for ultimate portability
Each microservice has its own ECR repository defined, and the Docker images and their respective builds are defined in Infrastructure as Code and managed via Pulumi so that end users do not need to perform Docker builds manually or even log into ECR repositories to push the finished images - Pulumi handles all of this under the hood.

Each of the three microservices, frontend, pelican, and emu, are defined within the AWS Reference Architecture’s monorepo so that users can easily read or modify their application code as desired.
The applications are also defined as Docker images so they can be easily swapped between cloud providers, running in ECS for AWS, locally for anyone wishing to modify or debug them, and, eventually, deploy them on other cloud providers.
AWS Best practice: separating infrastructure and applications according to their concerns
The Pinecone AWS Reference Architecture exposes a frontend UI that is end-user-facing. This UI is defined as an ECS service with a load balancer that allows ingress from the public internet, making the UI available to anyone.
Meanwhile, the AWS VPC that the Reference Architecture deploys separates the frontend UI microservice into the VPC’s public subnets and the RDS Postgres database and microservices into private subnets.
This prevents direct access to the persistence tier so that only the UI and backend microservices can connect to the database directly.
AWS Best practice: elastically scaling out and back in according to workloads
The Emu microservice has an app autoscaling policy, which kicks in whenever the Emu microservice is processing load at scale.
For example, when the Pelican microservice first wakes up in a freshly deployed Reference Architecture, it determines that it needs to put every record from the RDS Postgres instance on the SQS queue so that the Emu microservice will pick them up and embed and upsert all the Postgres product records into the Pinecone index.
This causes the autoscaling policy to kick in and spin up six additional Emu workers for a total of 8, which allows the Emu microservice to rapidly process the 10,000-message-long queue that results from this initial data bootstrapping sequence.
Once this work is complete, the same autoscaling policy detects that Emu is no longer under heavy load and proceeds to scale-in workers back down to the initial count of two.
Pinecone AWS Reference Architecture microservices at a glance
The Reference Architecture comprises three separate microservices and the supporting infrastructure that allows them to work together.
We’ll now look at each microservice individually and see how its functionality contributes to the system as a whole.
Frontend microservice
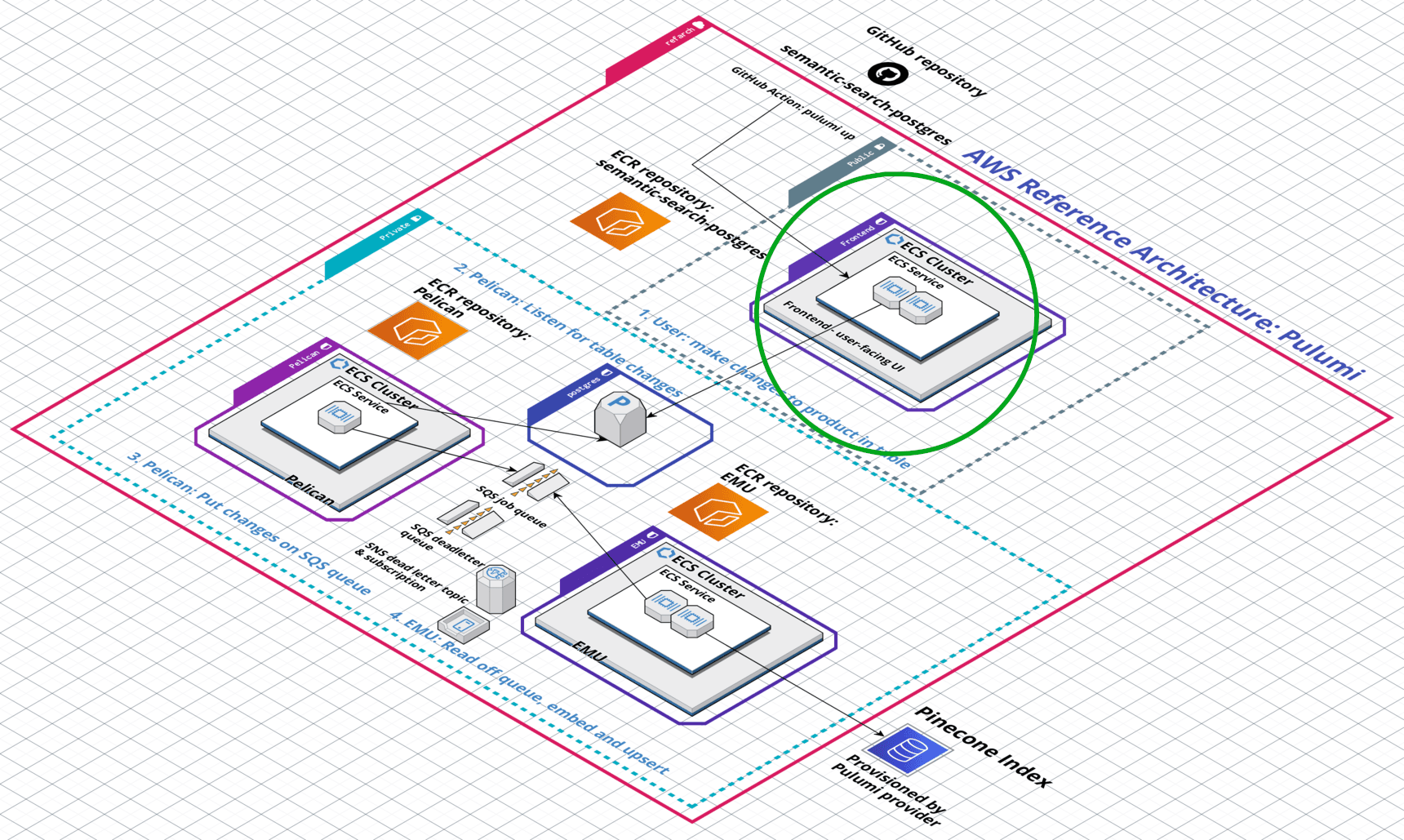
The frontend microservice exposes a table-based semantic search interface to end users, accessible over the public internet.
The table is populated with product records from the central RDS Postgres database. The frontend microservice runs in the public subnets of the custom virtual private cloud (VPC), which the Reference Architecture deploys.
The frontend microservice runs in a unique security group, specifically granted access by the RDS Postgres database’s security group, allowing the frontend to issue SQL queries to Postgres.
The RDS Postgres database runs in the same VPC’s private subnets, so only the UI and two other backend microservices can access it directly. This prevents malicious bots and users from connecting to our database directly.
To support the semantic search functionality, the frontend automatically converts any user queries, such as “AI” in the following example, into query embeddings that can be passed to the Pinecone index in a query via API:
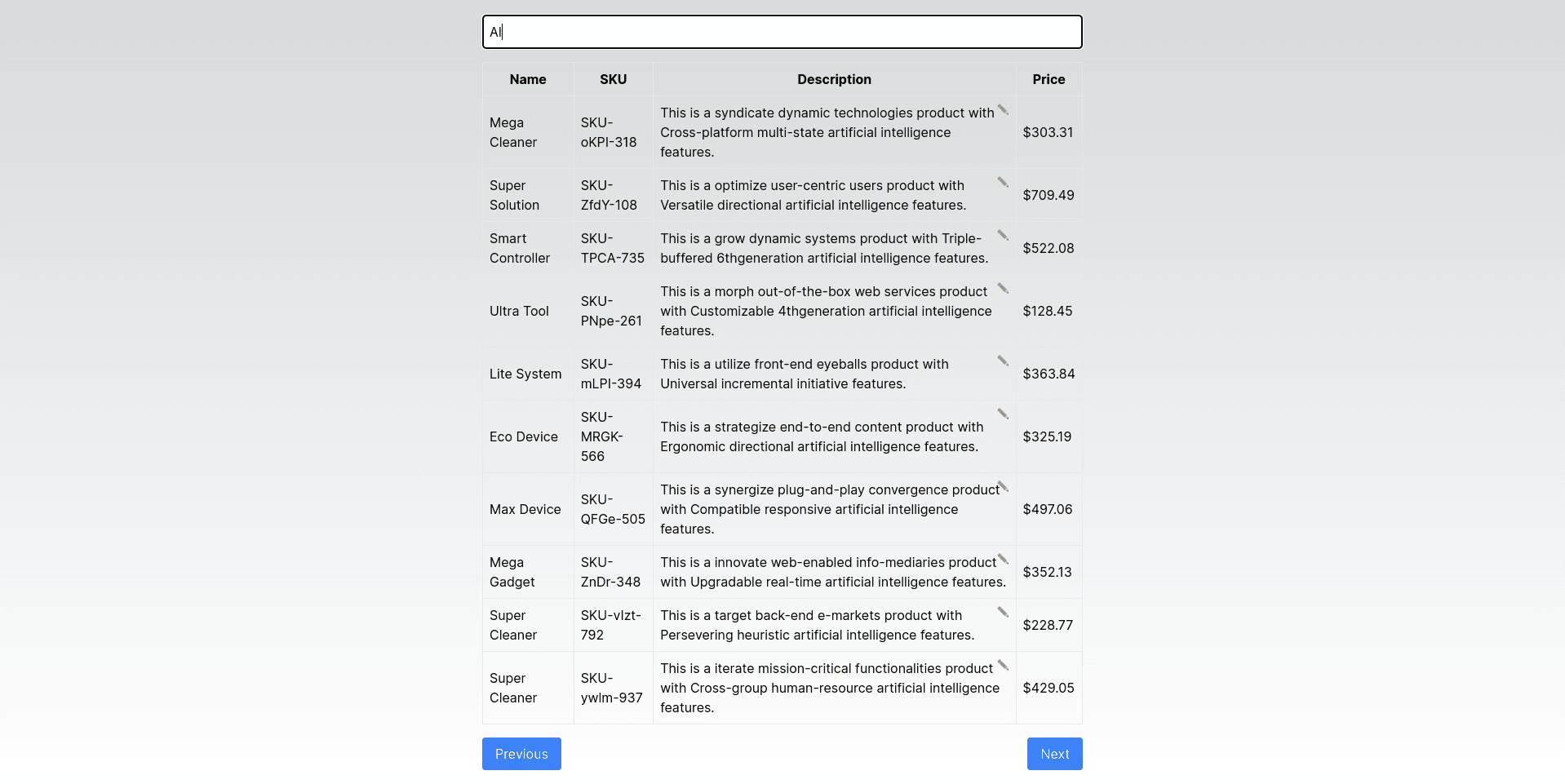
In this example, we can see that even though the user entered “AI” - the system is smart enough to understand that they’re talking about Artificial Intelligence and to retrieve any product records that discuss artificial intelligence in their descriptions.
Pelican microservice
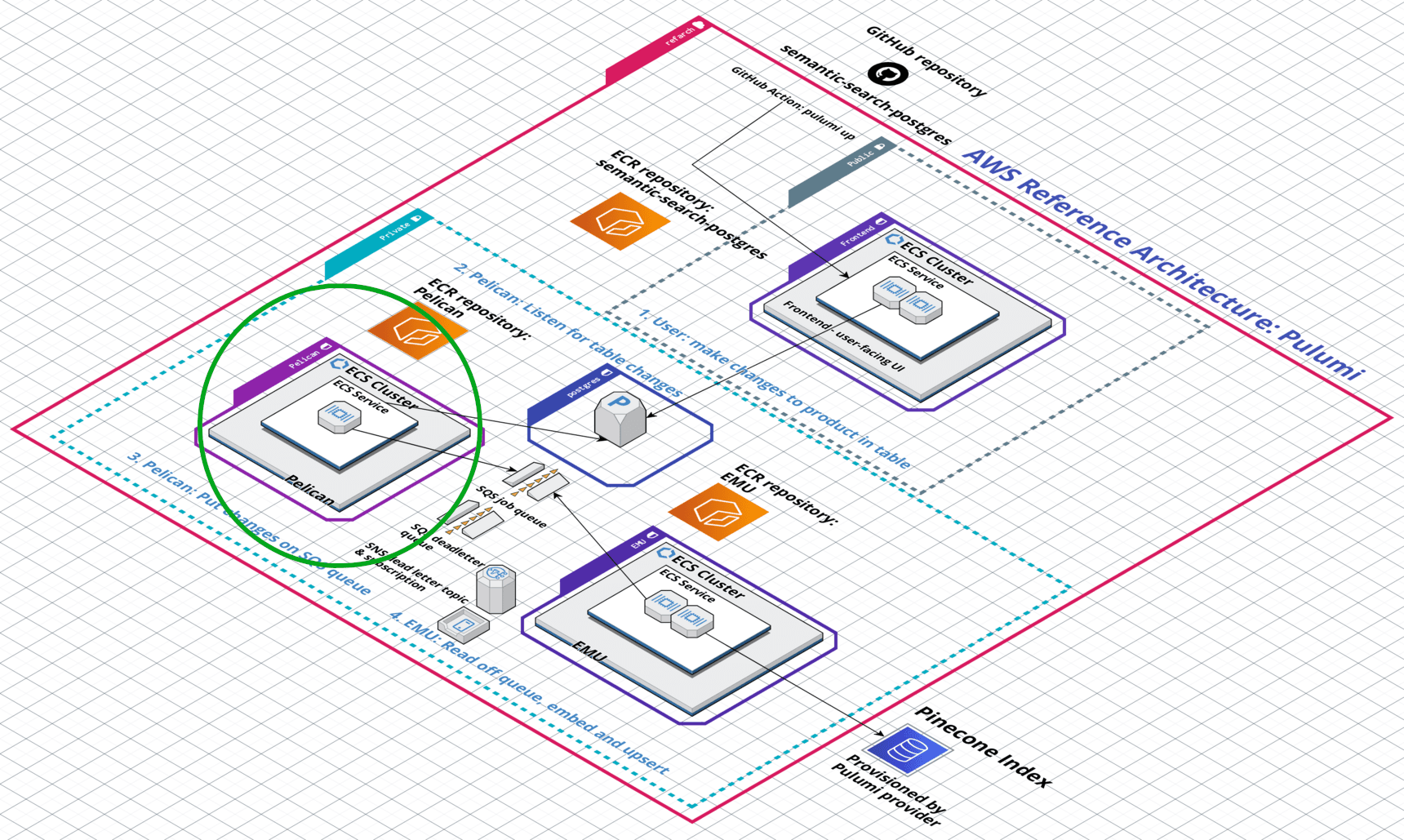
The Pelican microservice has two concerns:
- Perform the initial data bootstrapping procedure for a freshly deployed Reference Architecture, which moves all the Postgres records into the Pinecone index as embeddings to support the frontend UI’s semantic search functionality
- Listen to Postgres for changed records, which occur whenever an end-user modifies and saves a record from the table in the frontend UI, and place the changed records on the SQS queue so that the Emu microservice can pick them up, embed, and upsert them to keep the Pinecone index in sync with the changes the user is making.
To handle its data bootstrapping responsibilities, Pelican uses row-level locking to select distinct "batches" of records so that individual workers don't step on one another's work.
Pelican workers will continue looping through batches of Postgres records and placing each row on the SQS queue as a JSON message until all records have been processed.
Once all records are processed, Pelican exits its data bootstrapping phrase and will LISTEN to the Postgres database using triggers set up via `pg_notify.`
Every time a user modifies a record in the frontend UI - that change will result in a table change notification that Pelican sees. Pelican will place the JSON containing the old and new records on the SQS queue, which Emu will pick up for processing downstream.
Emu: Embedding and upsert microservice
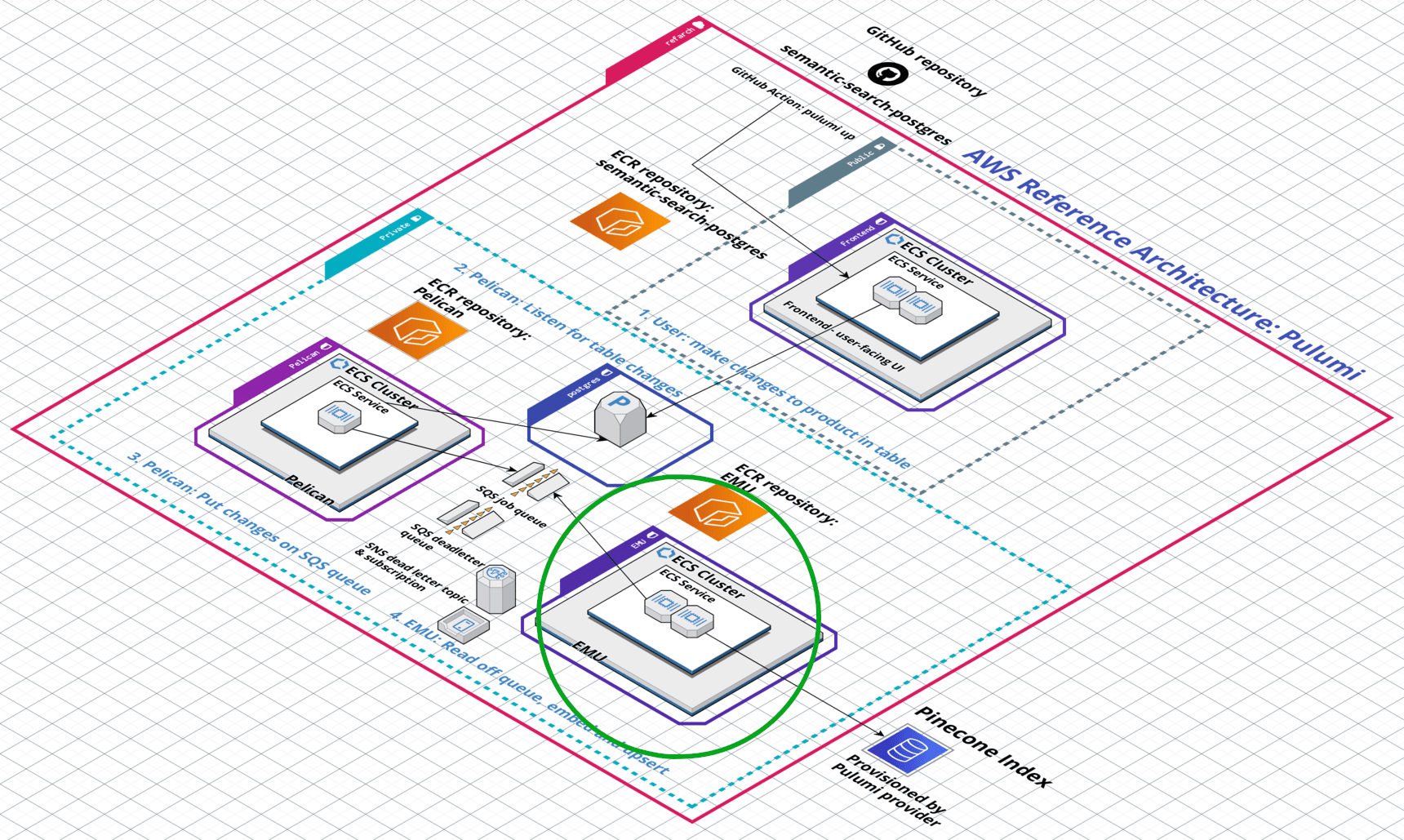
Emu reads jobs off the SQS queue and converts the product descriptions into embeddings, which it upserts to the Pinecone index. Along with the product description, metadata containing the record’s ID within the Postgres database is also upserted.
This metadata property is the link allowing the frontend UI to connect the end-user’s ambiguous natural language queries with the structured data stored in Postgres.
Emu is also configured to autoscale. When the SQS queue has a lot of work to process, the Emu workers automatically spin up to the maximum limit to chew through the work queue more expediently.
Once the work is complete and Emu is resting mostly idle again, the same autoscaling policy scales the Emu workers back in - to the default count of two to save on costs.
By leveraging a queue for all jobs and autoscaling for the microservice that is performing the resource-intensive work of processing each record, we can scale the Reference Architecture elastically in response to surges of work.
Why we chose Pulumi and Infrastructure as Code
We used Pulumi to define the entire Reference Architecture as code to make the architecture as easily reproducible as possible.

Users who want to deploy the Reference Architecture need only obtain credentials to their AWS account, set a few environment variables, and run the `pulumi up` command to have the entire distributed system deployed to their AWS account in minutes.
By defining the Reference Architecture in TypeScript, we expose an interface that many of our users are already familiar with, allowing users to modify the architecture to their requirements by editing the Pulumi TypeScript code.
Infrastructure as Code also helps to solve some of the largest common pain points around working with cloud infrastructure as a team, including managing shared state, fitting infrastructure changes into existing pull request and code review patterns, and tracking changes to cloud environments in version control.
Pulumi makes the developer experience of working with cloud infrastructure much more pleasant. For example, the Pinecone AWS Reference Architecture defines the docker image build processes and the target ECR repositories for built images in code.
Users do not need to build the Docker image for each microservice manually, authenticate to each ECR repository, tag images correctly, and push them because Pulumi handles all of this under the hood when you run the pulumi up command.
What's next
We’re monitoring the Pinecone AWS Reference Architecture GitHub repository for issues, questions, and discussion topics. We’re standing by to assist anyone with questions when deploying the Reference Architecture.
In the future, we plan to build and release additional “flavors” of the Reference Architecture, which may include support for additional Infrastructure as Code tools and different compute or persistence stacks.
Was this article helpful?