Announcing the Pinecone Vector Database and $10M in Seed Funding
Today we are launching the Pinecone vector database as a public beta, and announcing $10M in seed funding led by Wing Venture Capital.
The Problems and Promises of Vectors
Machine Learning (ML) represents everything as vectors, from documents, to videos, to user behaviors. This representation makes it possible to accurately search, retrieve, rank, and classify different items by similarity and relevance. This is useful in many applications such as product recommendations, semantic search, image search, anomaly detection, fraud detection, face recognition, and many more.
Edo Liberty led the creation of Amazon SageMaker at AWS, when he realized the main difficulty companies were facing in leveraging machine learning wasn’t in training or deploying models. The main difficulty was in working with large amounts of vector data in real-time.
What’s so difficult about working with vector data? For starters, the vectors need to be stored and indexed somewhere. Also, the index needs to be updated every time the data is changed. Next, there needs to be a way to search the index and retrieve the most similar items. This is computationally intensive — especially if the results are needed in real-time — so it needs to run on a distributed compute system. Finally, this entire system needs to be operational which means it needs to be monitored and maintained.
There are many solutions that do this for columnar, JSON, document, and other kinds of data, but not for the dense, high-dimensional vectors used in ML and especially in Deep Learning. As a result, companies have been forced to either compromise on accuracy and speed of the application, or to build and maintain their own complex infrastructure for supporting vector data.
It was obvious to Edo this challenge would become widespread as companies launch or expand their AI/ML initiatives, so in 2019 he founded Pinecone and built the vector index — the core of the vector database.
Introducing the Vector Database
Pinecone is a managed database for working with vectors. It provides the infrastructure for ML applications that need to search and rank results based on similarity. With Pinecone, engineers and data scientists can build vector-based applications that are accurate, fast, and scalable, all with a simple API and zero maintenance.
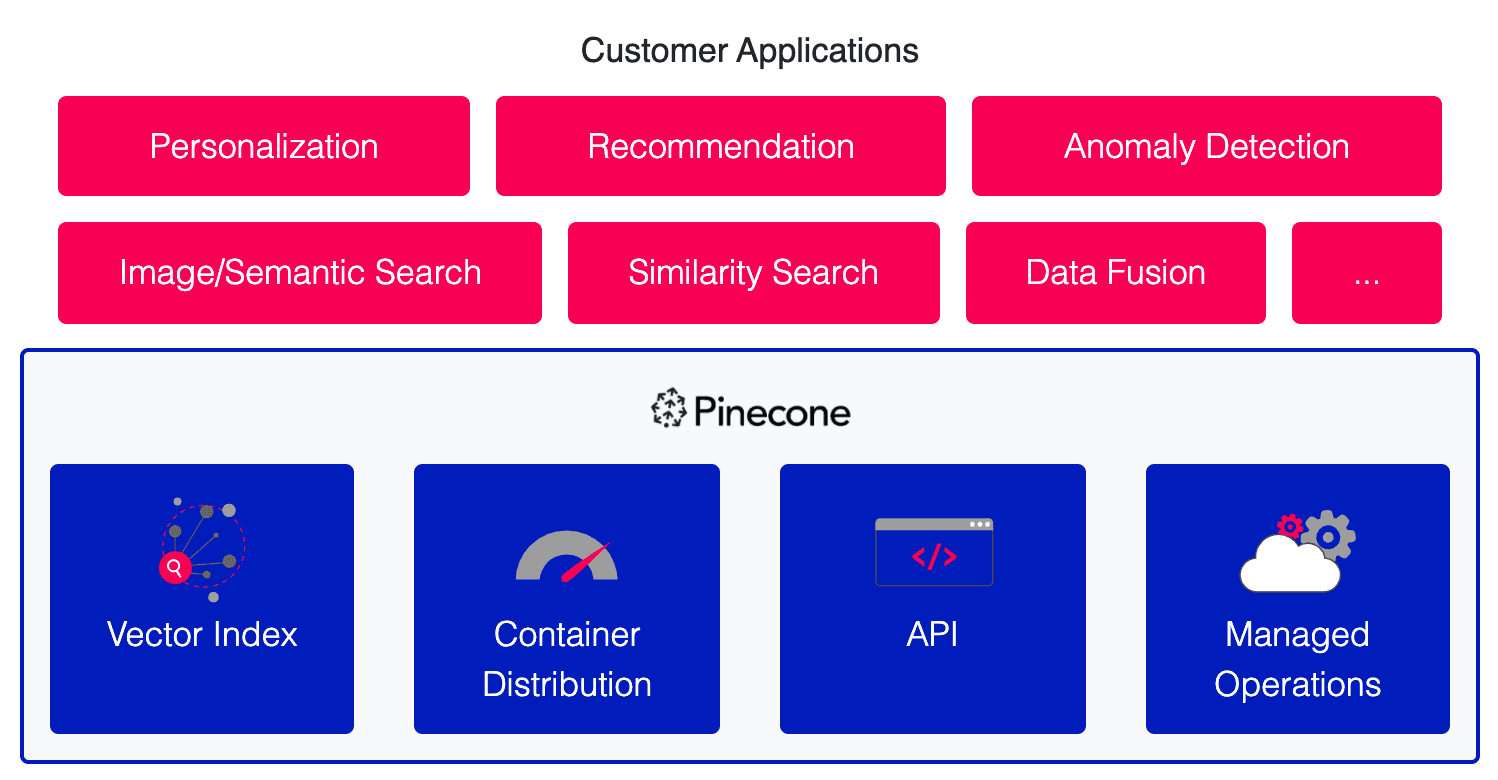
There are four components of the vector database:
- The vector index provides blazing-fast indexing and efficient storage for high-dimensional vectors. It uses a proprietary nearest-neighbor search algorithm that is faster and more accurate than any open-source library. (Benchmarks will be published soon.)
- Container distribution ensures exceptional performance regardless of scale, with dynamic load balancing, replication, name-spacing, sharding, and more.
- The API enables updating and querying vector indexes from anywhere, including Jupyter notebooks. It is also used for managing artifacts such as models, indexes, and services.
- Managed operations provide hands-free (for users) resource allocation, observability, SLA guarantees, security, and more.
Since Pinecone is a fully managed service, there is no need to configure open-source software or set up and maintain any infrastructure.
See the product overview for a complete list of features.
Funding for Growth and Development
In addition to the product launch, we are also announcing that we raised $10M in seed funding led by Wing Venture Capital, whose founding partner Peter Wagner has joined our board. Peter is a visionary in the cloud, data, and machine learning spaces, as evidenced by his early investment in Snowflake. We can’t imagine a better partner for us than Peter, and we are beyond excited to have him onboard.
Try Pinecone or Join Us
Pinecone is available as a public beta starting today. Try it free for 30 days.
Following the free trial, Pinecone comes with transparent, consumption-based pricing. Companies that require additional operational control, tighter security and governance, guaranteed performance and resilience, and 24/7 on-call operational support can contact us to learn more and to see a demo.
Companies are only beginning to see the potential of machine learning, and we are excited to help them achieve that potential sooner. For any engineers also excited by this: We are hiring!
Was this article helpful?