
>100M
vectors stored across thousands of customers
100ms
P95 query latency
<30%
of total response time spent on retrieval
Delphi helps coaches, creators, and experts turn their knowledge into live, interactive “Digital Minds.” These AI agents draw on unstructured content sources like books, podcasts, videos, and social posts to have meaningful conversations with end users. As Delphi expanded from a proof of concept to a commercial platform, two critical requirements emerged: they needed to serve thousands of simultaneous chats with sub-second response times, and they needed to isolate each creator’s data for privacy and compliance. At the same time, they were building a product for a broad audience—from individual coaches to enterprise training teams—which meant they had to balance technical rigor with an intuitive, low-maintenance experience for their customers.
Before Pinecone, Delphi’s small (but rapidly growing) engineering team spent weeks tuning open-source vector stores, wrestling with index fragmentation, and building sharding logic to meet performance targets. Each new customer added operational complexity. Meanwhile, variable loads such as live events or new content releases caused latency spikes that risked frustrating end users. Delphi needed a vector database that would deliver consistent low-latency retrievals, scale seamlessly under load, and free their team to focus on features, not infrastructure.
Balancing massive scale, low latency, and data governance
Delphi set out to productize Digital Minds at enterprise scale. That meant having the ability to support millions of isolated namespaces across billions of vectors. Each creator brings unique content, from social posts to long-form transcripts, and Delphi anticipated onboarding tens of thousands of them with widely varying usage patterns.
Early pilots of open-source vector stores revealed three critical pain points:
- Unbounded index growth: HNSW-based indexes grew too large to support stable, predictable retrievals at scale.
- Inefficient ANN under load: Similarity searches slowed significantly as data volumes increased, jeopardizing sub-second response targets.
- Partition-count limits: Hard caps on the number of partitions complicated scaling beyond initial capacity and added operational complexity.
These limitations posed both performance and reliability risks. Delphi’s use cases include live interactions, such as phone calls and video chats, where any delay in retrieval can disrupt the flow of conversation. To maintain a high-quality user experience, they established a 1-second end-to-end latency target for their system. When vector retrieval began consuming too much of that budget, it threatened their ability to meet that bar.
At the same time, Delphi had to uphold strict data governance for their creator customers. Each Digital Mind needed to be fully isolated from others, with support for encrypted storage, rapid data deletion, and auditability to meet enterprise expectations and evolving compliance standards.
Delphi needed a vector database that could scale with growth, maintain low latency and retrieval accuracy under variable load, and meet rigorous security standards without adding operational overhead.
A foundation built to grow with the platform
Delphi selected Pinecone to power agentic retrieval for every Digital Mind on their platform. Pinecone’s fully managed, cloud-native vector database removed the infrastructure burden of open-source alternatives.
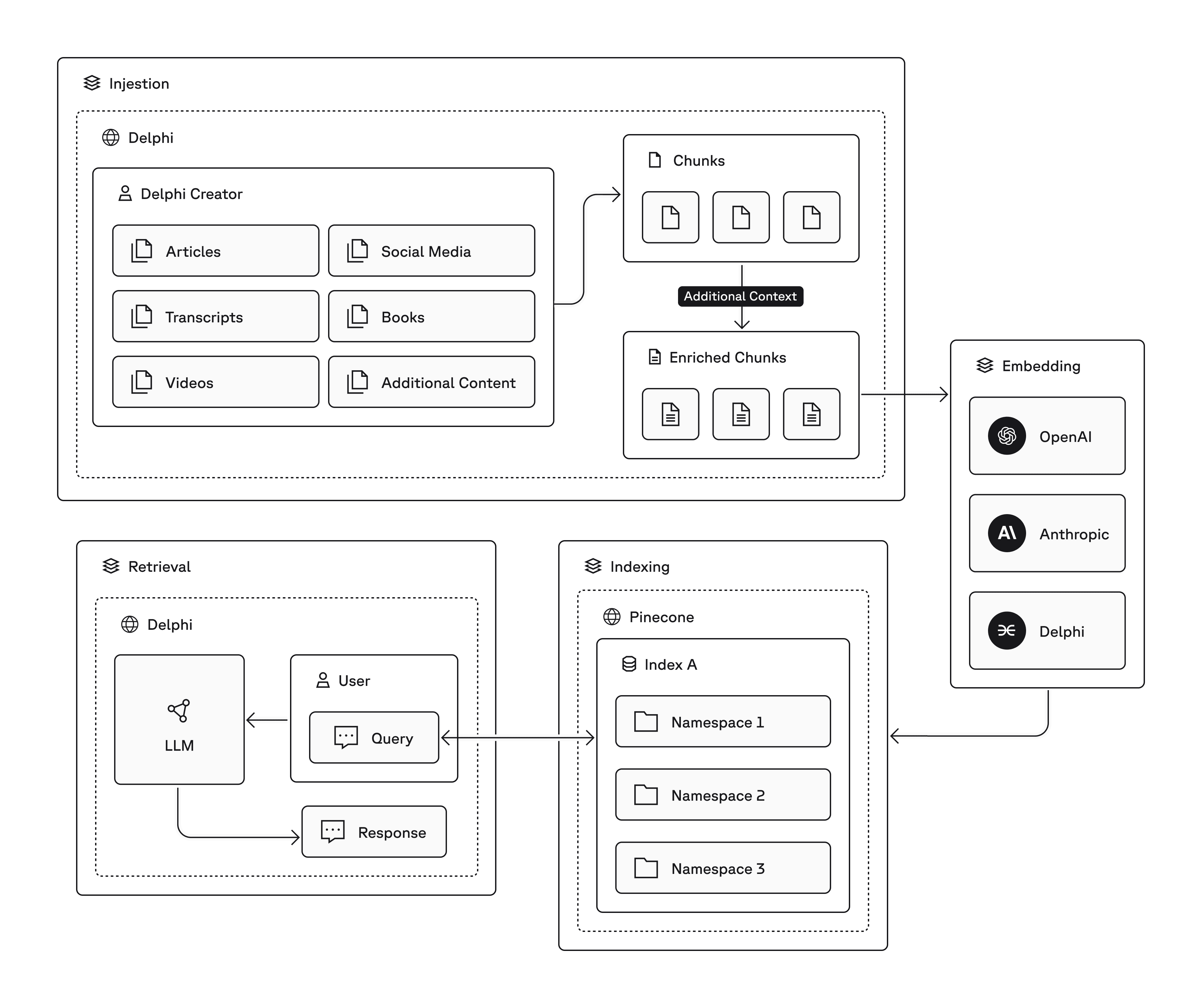
Each Digital Mind lives in its own namespace, or group of namespaces, within Pinecone. This approach provides natural data isolation and reduces search surface area, improving both performance and privacy. Namespaces also simplify compliance: Delphi can delete all of a creator’s data with a single API call, satisfying on-demand deletion requests with minimal engineering effort.
Pinecone now sits at the core of Delphi’s retrieval-augmented generation (RAG) pipeline:
- Ingestion: Users upload content such as articles, podcast transcripts, or course videos. Delphi’s pipelines clean and structure this content into chunks and augment it with additional context (like summaries and hypothetical questions).
- Embedding: Each enriched chunk is embedded using models from OpenAI, Anthropic, or Delphi’s own infrastructure.
- Indexing: Embeddings are stored in Pinecone under the appropriate namespace.
- Retrieval: Delphi transforms the user’s query at runtime and sends it to Pinecone. Highly relevant, accurate context returns in under 100ms (P95), then feeds into the LLM to generate a response.
Pinecone’s serverless architecture enables Delphi to efficiently and massively scale, thanks to:
- Separation of storage and compute: Indexes are stored in blob storage and only relevant segments are loaded into memory on demand, enabling cost-efficient scaling to billions of vectors.
- Hierarchical partitioning and dynamic index construction: Pinecone incrementally builds indexes and uses geometric partitioning to load only what’s needed for each query, preserving speed as data grows.
- Built-in freshness layer: Recent writes are made searchable within seconds, ensuring Digital Minds always reflect the latest content updates.
- Efficient multi-tenancy through namespaces: Pinecone caches frequently accessed tenants for low-latency performance and pages out less active ones to storage—then loads them back into memory on demand to support Delphi’s highly segmented, agent-based use case.
- Optimized filtering and memory efficiency: Disk-based metadata filtering and memory-optimized execution keep resource usage low even with rich, filter-heavy queries across large workloads.
Pinecone’s enterprise readiness, including SOC 2 compliance; encryption in transit and at rest; and native controls for data deletion and access separation, were also key for Delphi.
The ability to scale quickly, without re-architecting or running into cost or performance cliffs, has been huge for us. Pinecone just works, which lets us grow without hesitation.
— Sarosh Khan, Head of AI at Delphi
Pinecone removed the need for Delphi to manage indexing, tuning, or infrastructure scaling. Instead, their team could focus on what mattered most: improving agent performance, adding new features, and onboarding more creators.
Reliable performance at scale, with room to grow
With Pinecone in production, Delphi supports more than 100 million vectors across 12,000+ namespaces. Real-time, high-accuracy vector search consistently returns results in under 100ms at P95, keeping overall response time well within their 1-second end-to-end target and ensuring conversations feel natural and responsive.
Of Delphi’s 1-second response target, retrieval accounts for <30% of that time, leaving ample headroom for query transformation and response generation.
Delphi also achieves 20 queries per second (QPS) globally across customer deployments, supporting concurrent conversations across time zones and zero scaling incidents, even during traffic spikes triggered by live events or high-volume content imports.
This consistency gave us the confidence to scale aggressively. As we adopted a more advanced architecture, Pinecone remained the clear choice. The reliability of their product and the quality of their support reaffirmed our decision to work with them as a trusted partner.
— Alvin Alaphat, Founding Engineer at Delphi
A Million Digital Minds
Delphi’s vision includes supporting millions of Digital Minds (i.e., conversational agents), each powered by unique content, audiences, and conversational use cases. With Pinecone, Delphi is confident they can seamlessly scale to meet that demand, which would include at least five million namespaces in a single index, without changing how they build or architect their platform.
As they expand, Delphi plans to explore more advanced retrieval workflows, richer content representations, and tighter integration of retrieval and generation. Whether building tools for professional development, personalized education, or AI-driven coaching, Pinecone remains a core part of Delphi’s infrastructure for fast, accurate retrieval at scale.