
> 400M
> 400M
vectors stored
< 20ms
< 20ms
P50 query latency
# 1
# 1
ranking in RAG accuracy benchmark*
CustomGPT.ai is a pioneering no-code SaaS platform that democratizes Retrieval-Augmented Generation (RAG) technology. By enabling businesses to effortlessly build domain-specific GPTs integrated with their own data for use cases like employee training, helpdesk automation, custom content generation, and general knowledge management, CustomGPT.ai empowers organizations to unlock real-time, accurate insights with minimal technical overhead.
CustomGPT.ai’s platform is built with one goal in mind: making business-specific generative AI accessible for all. The company advises its customers to “focus on what you do best.” CustomGPT.ai itself focuses on making GenAI more accessible by creating a best-in-class RAG-as-a-Service offering, rather than building and maintaining the underlying data storage infrastructure. That is why CustomGPT.ai turned to Pinecone, the leading vector database for building accurate and performant AI applications like theirs, at scale and in production.
Confronting the demands of high-performance vector retrieval for RAG and agent integration
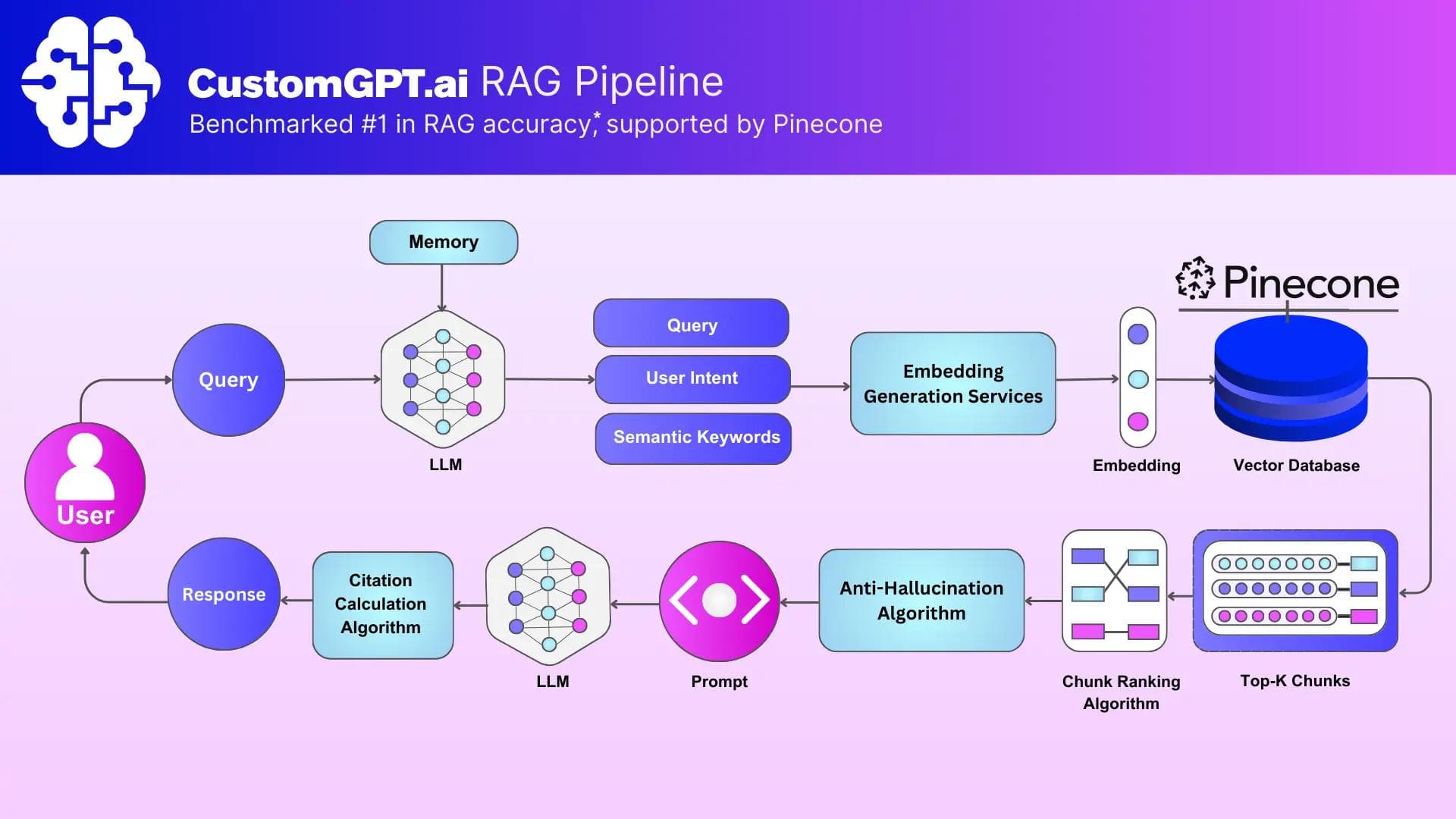
CustomGPT.ai knew that in order to build a successful business, they needed to focus on the hundreds of considerations in the RAG pipeline rather than the underlying infrastructure. That meant investing in the areas where they could uniquely add value such as building no-code tools that enable non-technical users to launch domain-specific GPTs; delivering high-fidelity answer generation with context management and attribution; and supporting dynamic integrations with data sources like Google Drive, Notion, and Confluence. Their platform also needed to give developers a flexible RAG API, chat UI widgets, and real-time persona control to fine-tune how agents behave, all while syncing continuously with evolving business content.
Managing a vector database in-house would have imposed a heavy operational cost—one that risked diverting critical engineering bandwidth away from these core challenges. Building for production also meant meeting stringent technical demands: retrieval accuracy, low-latency responses, high availability, fault tolerance, and the ability to scale across massive datasets and user bases.
For CustomGPT.ai to succeed, they needed a partner that could deliver this infrastructure out of the box—at scale, with minimal friction, and without compromising performance.
Infrastructure built to accelerate innovation
To support its ambitious vision for RAG-as-a-Service, CustomGPT.ai turned to Pinecone for a proven managed vector database built specifically for production use cases. Pinecone delivered exactly what CustomGPT.ai needed: a robust, scalable, cloud-native system optimized for vector search, freeing the team from having to manage core infrastructure themselves.
At the heart of Pinecone’s appeal was its ability to provide real-time, accurate search without the operational burdens of scaling or tuning index performance. As CustomGPT.ai’s customer base and data volumes grew, Pinecone enabled them to scale elastically without requiring any intervention.
Pinecone’s fully managed serverless infrastructure is designed to securely handle dynamic, high-throughput environments like CustomGPT.ai’s—where agents need to retrieve information quickly and accurately from constantly changing datasets. Key capabilities include:
- High data freshness: Pinecone's support for upserts and deletes with sub-second updates ensures that agents are always retrieving the most recent information, a must-have for CustomGPT.ai’s customers who rely on timely and accurate answers.
- Millisecond query latency at scale: Pinecone’s indexing engine is optimized for speed and efficiency, even across tens of millions of vectors and high QPS.
- Fault tolerance: Built-in redundancy and regional failover options help ensure uninterrupted service, which is critical to CustomGPT.ai’s production guarantees.
- API-first and framework-agnostic: Pinecone integrates seamlessly with CustomGPT.ai’s proprietary RAG stack and low-code developer APIs, with no dependency on third-party agent frameworks.
By offloading vector retrieval to Pinecone, CustomGPT.ai was able to focus entirely on building the differentiated components of their platform—from intuitive user-facing tools to fine-tuned LLM workflows.
Pinecone lets us focus on innovation and delivering customer value through our RAG-as-a-Service – without getting bogged down with vector database issues. We trust Pinecone to provide the foundational infrastructure we rely on for accurate, production-grade vector retrieval at scale. — Alden Do Rosario, CEO at CustomGPT.ai.
Scaling confidently without compromise
With Pinecone powering its vector search layer, CustomGPT.ai was able to accelerate product development, scale rapidly, and deliver enterprise-grade performance to its growing customer base. The ability to operate at scale without sacrificing accuracy, reliability, security, or developer velocity proved essential to CustomGPT.ai’s success.
Key outcomes include:
- Rapid scale and adoption: CustomGPT.ai grew to over 10,000 paying customers, each running custom GPT projects built on their own data—enabled by Pinecone’s ability to handle hundreds of millions of vectors across thousands of namespaces.
- Operational excellence: Pinecone supported <20ms P50 query latency and 99.95+% uptime, ensuring consistent performance even as query volumes surged.
- Developer productivity and velocity: With no need to manage vector infrastructure, CustomGPT.ai’s engineering team focused entirely on their proprietary RAG pipeline—shipping new features faster and supporting advanced use cases like ticket deflection for support, website assistants for lead generation, and knowledge management for creating expert customer GPTs.
- High-fidelity AI experiences: CustomGPT.ai’s domain-specific AI agents provided precise, context-rich responses with minimal hallucination—supported by Pinecone’s high recall accuracy and data freshness.
- Best-in-class retrieval accuracy: With Pinecone powering the vector layer, CustomGPT.ai achieved the #1 ranking in a RAG accuracy benchmark*, validating the strength of its retrieval pipeline and re-ranking logic in real-world performance testing.
By relying on Pinecone to handle the critical foundation of vector search, CustomGPT.ai was able to move faster, innovate meaningfully, and ultimately bring its RAG-as-a-Service vision to life at production scale.
Looking Ahead
CustomGPT.ai is evolving its platform to bring customers even greater value—combining the accuracy of its RAG technology with intelligent agentic workflows. This next phase empowers businesses to deploy autonomous agents that perform tasks with higher accuracy by leveraging RAG-powered insights from their own company data. Powered by Pinecone’s real-time vector search infrastructure, upcoming features like goal-driven agents, dynamic data integration, and natural language analytics will streamline workflows and drive faster, smarter outcomes across organizations.
*#1 ranking in RAG accuracy benchmark claim refers to an independent benchmark conducted by Tonic.ai. Full evaluation results on GitHub.