
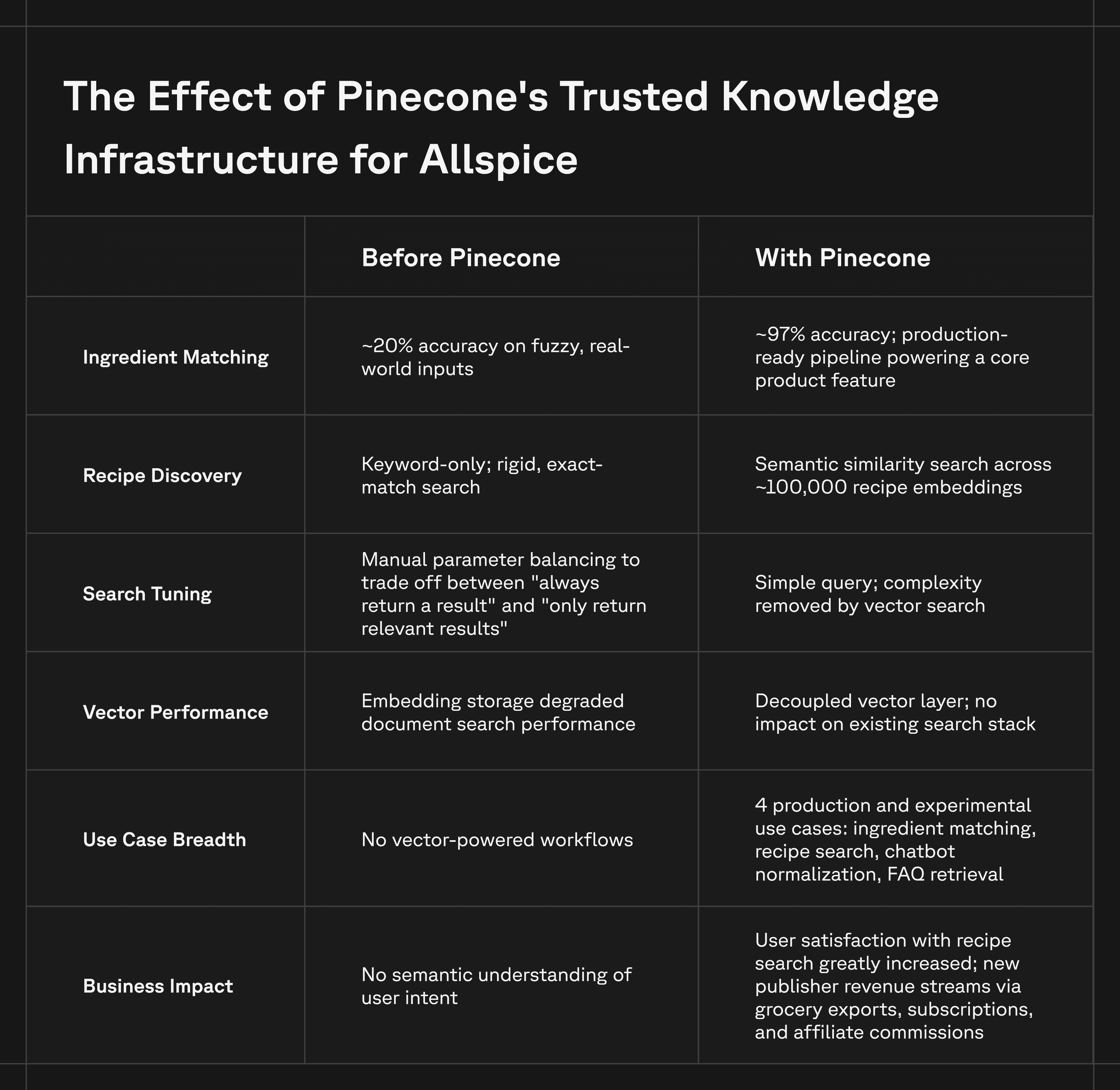
20% → 97%
accuracy in ingredient matching
↑
user satisfaction and publisher revenue opportunities
1 afternoon
time to set up Pinecone and validate a working pipeline
Allspice is a food technology company building a comprehensive "kitchen operating system". Serving both consumers (B2C) and recipe publishers (B2B), the platform helps home cooks discover recipes, manage pantry inventory, and generate automated, deduplicated shopping lists. For publishers, Allspice provides interactive tools that enhance user engagement and unlock new revenue streams beyond traditional display advertising.
At the heart of this experience is the ability to understand food the way a human does, recognizing that "one bunch of cilantro" and "fresh cilantro, chopped" refer to the same item despite the different wording. The platform works with structured and semi-structured data at its core. Recipe ingestion begins with RecipeLD JSON extracted from scraped HTML pages, processed through a proprietary pipeline into Allspice's internal schema. Underneath it all is a proprietary ingredient database that powers ingredient matching, pantry tracking, shopping list generation, and recipe intelligence. That ingredient data layer is central to nearly everything the platform does.
As Allspice expanded recipe importing into a primary feature, the company hit a wall: matching ingredients reliably across thousands of recipes required a level of semantic understanding that its existing search infrastructure could not deliver.
Traditional search couldn't handle how people talk about food
Before Pinecone, Allspice ran a fully NoSQL stack: Google Cloud Firestore for document storage and Typesense for recipe and content search across the platform.
Typesense worked well for traditional search. But once recipe importing became a core product feature, the team ran into a fundamental problem: ingredient matching. Ingredient data is inherently messy. Variations in descriptions, misspellings, parsing inconsistencies, and modifier-heavy phrases (like "large farm-fresh eggs, beaten") make deterministic matching difficult. Traditional text search, even with synonym handling, could not reliably bridge the gap between how ingredients appear in source recipes and how they are represented in Allspice's structured database.
The team also discovered performance limitations when attempting to use Typesense's vector support. Storing large embeddings alongside relatively small documents created inefficiencies. Because document size significantly impacts performance in that model, embedding vectors directly into search documents slowed parts of the system that were otherwise lightweight.
Allspice needed a dedicated semantic layer — one that could introduce fuzziness while preserving accuracy, without degrading the performance of the rest of the search stack. Without reliable ingredient matching, Allspice could not launch recipe importing, one of its core product features, blocking a key revenue stream for publishers and stalling platform growth. Every failed match meant a recipe that couldn't be imported, a user who couldn't generate a shopping list, and a publisher missing out on engagement and monetization. The longer the problem persisted, the more it constrained the company's ability to expand its publisher network and deliver on its B2B value proposition.
A semantic layer that bridges messy language and structured data
When Allspice determined it needed a dedicated vector database, the team turned to Pinecone. A key requirement was developer friendliness and speed of implementation. The team was in a phase where rapidly testing ideas and moving from prototype to validation was critical. Pinecone's documentation and setup workflows made it easy to integrate vector search into the existing architecture and begin experimenting immediately.
The benefit of vectors has always been flexibility. Instead of carefully managing search params in Typesense, trying to balance always receiving a result with only receiving relevant results, Pinecone removes all that complexity with a simple query. — William Templeton, co-founder and CTO at Allspice
Unlike bolt-on vector capabilities in traditional search engines, where storing large embeddings alongside small documents degrades overall system performance, Pinecone's purpose-built, serverless vector infrastructure keeps semantic search fully decoupled from the rest of Allspice's stack. This meant the team could scale vector workloads independently without rearchitecting their existing search and storage layers.
The first implementation focused on ingredient embeddings within the recipe-matching flow. This served as a proof of concept for vector search in the architecture. Using OpenAI's text-embedding-3-large model, the team embedded their proprietary ingredient database — approximately 10,000 ingredient embeddings — and immediately saw results that validated the approach.
From there, adoption expanded iteratively across the platform:
- Ingredient matching and recipe similarity: The foundational use case. These systems would not function without embeddings. A "more recipes like this" experience using recipe-level embeddings was straightforward to build and immediately resonated with users.
- Fuzzy recipe search: Pinecone acts as a complementary layer alongside traditional filtering and structured search, providing the most flexible retrieval experience when user intent is less precise. The platform now indexes approximately 100,000 recipe embeddings.
- Chatbot data normalization: For AI chatbot function calls, Pinecone maps free-form user inputs, such as diet preferences, to structured internal representations. This reduces input variability and cardinality. The team is also experimenting with Pinecone-hosted Llama embeddings for chat workflows, complementing the OpenAI embeddings used for ingredients and recipes.
- FAQ classification and retrieval: Early exploration of matching user questions against publisher-approved FAQ content and returning relevant answers, improving both chatbot reliability and publisher value.
Responsibilities are cleanly split across the stack: GCP handles Firestore, Cloud Run services, the recipe ingestion pipeline, chatbot backend, and deployment infrastructure. Pinecone handles vector storage and similarity search. Allspice's engineering team owns embeddings generation, normalization logic, ingredient intelligence, and retrieval workflows. Pinecone sits alongside multiple LLM providers in Allspice's stack, including Gemini 2.5 for the chatbot and a mix of GPT-4.1-mini and Gemini 2.5 for recipe processing, functioning as a model-agnostic retrieval layer that doesn't lock the team into a single AI provider.
Pinecone helps bridge a fundamental gap in modern AI systems between strictly structured data types and unstructured natural language input. It provides a semantic layer between those two worlds, allowing us to measure similarity and meaning without requiring exact matches or rigid schemas. This is especially valuable in domains like cooking, where users may describe ingredients, diets, or recipes in many different ways. — William Templeton, co-founder and CTO at Allspice
From 20% accuracy to a production-ready platform
The move to Pinecone fundamentally changed Allspice’s product viability. The most significant outcome was straightforward: Pinecone enabled Allspice's recipe importing pipeline to work. Without Pinecone’s vector search capabilities, the company would not have been able to launch one of its core product features. Before Pinecone, ingredient matching accuracy sat at roughly 20% — far too low to support a production feature. After implementation, accuracy jumped to 97%, with Pinecone serving as the core enabling piece of the matching system. The pipeline went from unusable to production-ready.
Beyond that foundational use case, Pinecone has become a semantic infrastructure layer across the Allspice platform. Their performance and ability to scale significantly improved: the platform now manages a growing library of 110,000 total embeddings with the flexibility to expand to billions as their publisher network grows. Users reported significantly improved satisfaction with recipe search. By reducing input variability and mapping messy real-world language into structured representations, Allspice built a tool that feels flexible to the consumer but remains reliable under the hood.
The team went from a single targeted workflow to multiple production and experimental use cases — spanning search, recommendations, data normalization, and conversational AI — without adding operational complexity. This enabled Allspice publishers to generate revenue directly from recipe interactions through mechanisms like grocery exports, subscriptions, and affiliate commissions. It also introduced new engagement surfaces for publishers, increasing time on site and overall revenue opportunities. Additionally, Allspice now provides analytics and data collection tools that help publishers better understand how users interact with their recipes.
Speed of iteration has been a key benefit for Allspice. Pinecone’s managed, serverless model meant the team could set up Pinecone in an afternoon, get a basic pipeline working, and evaluate the effectiveness of the solution against real problems. That speed was essential for a startup where validating ideas quickly determines what ships and what doesn't.
Now more than ever, it is crucial to iterate quickly. I would have never tried Pinecone without a cloud-hosted, serverless option. I needed something that I could set up in an afternoon and get working in a basic pipeline to evaluate the effectiveness of my solution to my problems. — William Templeton, co-founder and CTO at Allspice
Expanding Pinecone into AI agents and conversational cooking
Looking ahead, Allspice plans to expand Pinecone's role in its AI and chatbot systems. One key focus area is using Pinecone to support tool-driven normalization flows within the chatbot, where free-form language must be mapped to structured internal data reliably. The team is also building out FAQ classification and retrieval to match user questions against publisher-approved content, ensuring chatbot reliability and increasing value for B2B partners.
More broadly, Allspice plans to continue experimenting with Pinecone across its chatbot architecture to improve response quality, reduce operational and inference costs, and enhance the user experience. As chatbot query volume grows, the team expects vector retrieval to play a direct role in controlling LLM spend by reducing unnecessary token usage and improving the precision of context passed to models. Ultimately, with Allspice’s conversational systems maturing, Pinecone’s trusted knowledge infrastructure will become an increasingly important part of how users interact with recipes, cooking knowledge, and publisher content.