February Release: Performance at Scale, Predictability, and Control
The latest version of Pinecone gives you greater performance, predictability, and control of your vector search applications.
Low-latency vector search at scale is one of the biggest reasons engineering teams choose Pinecone. This update significantly lowers search latency for large indexes even further. For example, an index with 100M vectors is now 3.4x faster than before.
Engineers also choose Pinecone because they can start and scale a vector search service during their lunch break, without any infrastructure or algorithm hassles. This release provides more predictability and control while minimizing overhead, with a redesigned user console and additional deployment options across GCP and AWS.
This update is effective on all new indexes starting today. Indexes created before today will be automatically updated one month from now, on March 15. If you’d like your existing indexes updated sooner, we can perform a zero-downtime update for you by request.
Continue reading to learn more, then try it and join us for a live demo and Q&A on Tuesday, February 22nd.
Performance at scale
You’ve always had fast vector search with Pinecone, and now it stays remarkably fast even as you scale. Previously, as you added pods to accommodate a growing index, you experienced increasing search latencies. This release flattens the impact of scaling, so the search latency stays low even with hundreds of millions of vectors.
In our benchmark tests, indexes running on our performance-optimized pods (p1) maintain search speeds well below 120ms (p95) as they scale from zero to tens of millions of vectors. At 10M 768-dimensional vectors, Pinecone is now 1.6x faster than before, and at 20M vectors it is a whopping 2.5x faster than before.
Note: These tests used the minimum number of pods required. This is best case in terms of cost (fewer pods) and the “worst case” in terms of performance (each pod is at full capacity). Users can reduce latencies by adding more pods, and/or applying filters to queries. In practice, many customers see sub-100ms latencies from Pinecone. Since Pinecone is a cloud service, these latencies include network overhead.
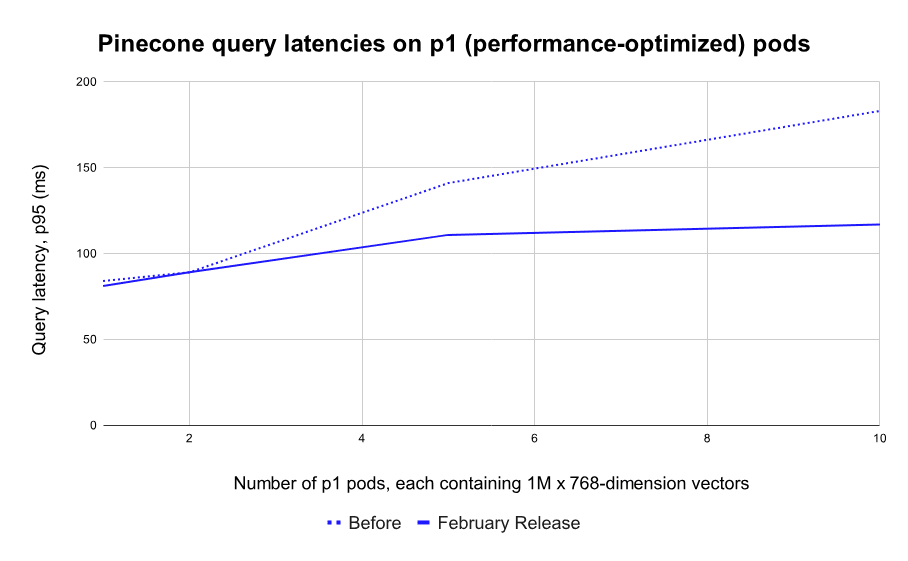
The difference is even starker for indexes running on our storage-optimized pods (s1). These pods were designed as a cost-efficient option for teams with larger catalogs and a tolerance for higher latency. However, their progressively slower search speeds at larger index sizes made them impractical for real-time applications… Until today.
With this release, indexes running on s1 pods maintain search latencies under 500ms (p95) even as you scale to 100M+ vectors. At 50M vectors, Pinecone is 2x faster than before, and at 100M vectors (20 pods) it’s an incredible 3.4x faster than before.
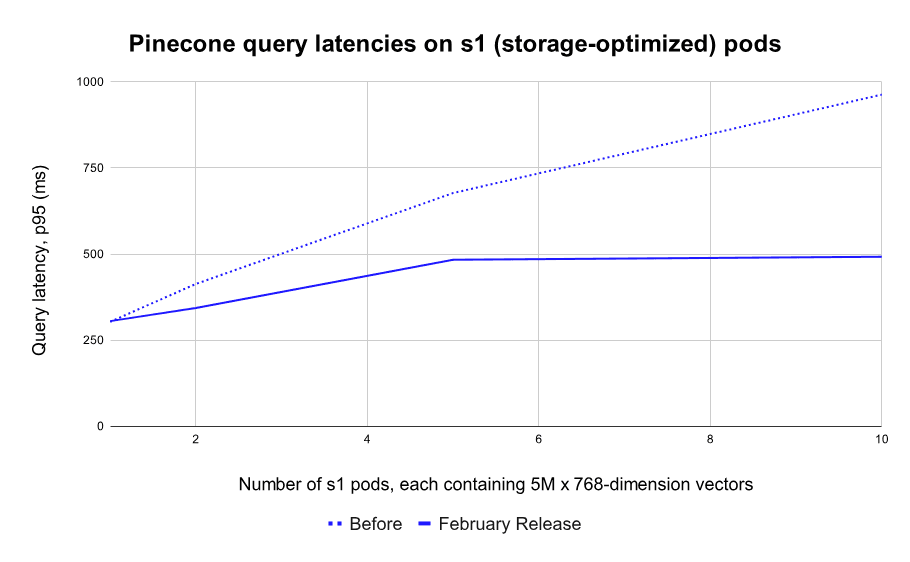
It doesn’t stop there. If you need to index billions of vectors while keeping sub-second latencies — like some of our customers — contact us for help in setting up your index.
As always, your performance may vary and we encourage you to test with your own data. Latencies are dependent on vector dimensionality, metadata size, network connection, cloud provider (more on this below), and other factors.
This improvement came from months of engineering efforts to build the most performant, scalable, and reliable vector database. It included rewriting core parts of the Pinecone engine in Rust, optimizing I/O operations, implementing dynamic caching, re-configuring storage formats, and more. This effort is never-ending, so expect even more performance improvements very soon.
Predict performance and usage
You need to know what to expect from your search applications. How fast will it be? How consistent is that speed? How much hardware do I need? What will it cost? How long will it take you to upload your data? This release helps you answer all of these questions and puts your mind at ease.
The first thing you want to predict is how many pods you’ll need, what they’ll cost, and what’s the expected latency. We’ve made this planning easier with our new usage estimator tool.
Next, you need to know that search speed will be consistent for your users without erratic spikes from one query to the next. This update drastically lowers the variance between p50 and p95 search latencies: It is now within 20% for p1 pods, and just 10% for s1 pods.
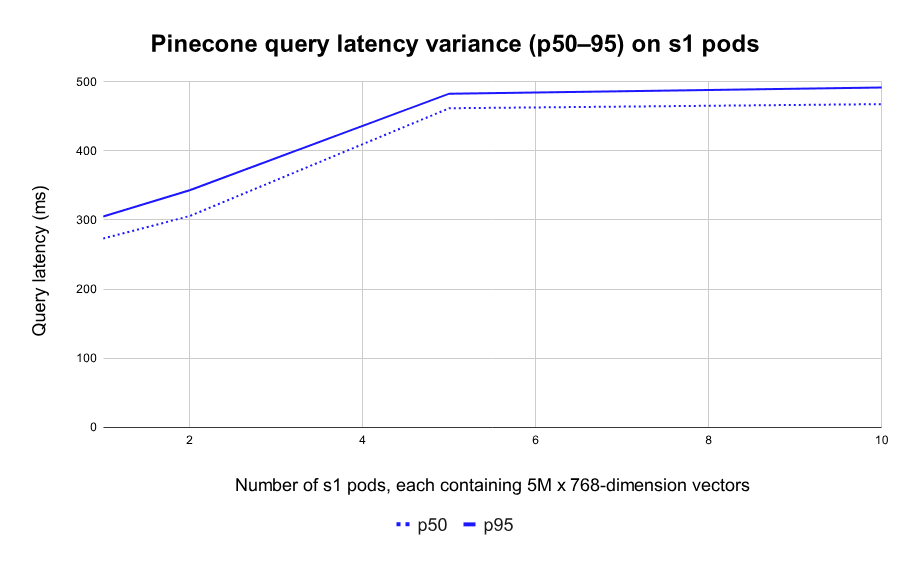
And finally, when you start loading data into Pinecone you want to know it’ll be indexed quickly and completely. We’ve made data ingestion faster and more reliable. Before, upserts slowed down as the index approached capacity, and if you exceeded capacity then the index would fail. Now, upserts stay fast all the way, and trying to upload beyond capacity will result in a gentle error message — the index will remain up.
Control projects and environments
Whether it’s to minimize latencies or to comply with data regulations, many Pinecone users asked for the ability to choose between cloud providers and regions. Now they have it.
Users on the Standard plan can now choose from GCP US-West, GCP EU-West (new), and AWS US-East (new). Even more regions are coming soon.
As before, users on the Dedicated plan get a single-tenant environment on GCP or AWS in any region of their choice.
GCP US-West remains the default environment for new projects, and the only one available for users on the Free plan. The environment is set when creating a project, and different projects can use different environments.
And now, creating and managing projects is even easier with the completely redesigned management console. It includes a new page for managing projects, along with a more powerful page for managing indexes and data.
And, let’s be honest, it’s also easier on the eyes. See it!
Get Started
For existing users:
- All new indexes starting from today come with this update.
- If you use the Python client, install the latest version with
pip install pinecone-client(see installation docs). - This is a non-breaking change. The updated API is backward compatible.
- Existing indexes will be rolled over by March 15th, with zero downtime.
- To update existing indexes before March 15, users on the Free plan should re-create the index, and users on the Standard or Dedicated plans should contact us with a preferred time when you want us to update your indexes.
For new users:
- Create a free account and start building vector-search applications.
- Register for the live office hour on Tuesday, Feb 22, to learn more, see a demo, and get your questions answered!
Was this article helpful?