Millions at Stake: How Melange's High-Recall Retrieval Prevents Litigation Collapse
Patent litigation leaves no room for uncertainty. When legal teams build a case, they rely on a complete historical record; a single overlooked document can redirect months of strategy and millions of dollars in potential outcomes. For companies that provide prior art search—the process of locating pre-existing evidence that an invention already existed—the margin for error is effectively zero. Their value comes from finding what others miss, and doing so consistently.
Melange, a patent analytics company, built its business on a clear premise: AI can examine far more data, in far less time, than human reviewers while accurately surfacing the 6–10 documents that determine the direction of a lawsuit. But delivering this outcome requires more than strong models. It requires an infrastructure layer that can reliably search across hundreds of millions of global patents and academic papers, and do so without failure.
What Melange discovered early is that the cost of inaccuracy is not just legal risk for their customers. It is operational risk, engineering cost, and time lost. It also opens the possibility of losing clients when competing firms find documents they might miss.
To avoid that outcome, Melange turned to Pinecone.
When Accuracy Determines the Outcome of a Lawsuit
Melange works at the demanding intersection of AI, legal expertise, and vast technical data.
Every case begins with a single question: Did this invention already exist before the patent was filed? Answering that requires combing through decades of global patent filings, machine-translated foreign documents, technical manuals, obscure academic papers, and the collective written record of innovation across hundreds of categories.
If Melange’s system misses even one key document, the consequences cascade:
- A litigating team may pursue an argument built on incomplete evidence
- A case strategy may shift, triggering millions in additional discovery or expert analysis
- The firm’s trust in Melange’s system weakens, jeopardizing future business
- Competing search firms may find what Melange didn’t
When we find that one killer piece of prior art that the customer thinks might win their case, we lock in the customer for life. — Joshua Beck, CEO at Melange
And the inverse is also true.
This is why accuracy, and the infrastructure that supports it, is central to Melange’s product and business.
The Infrastructure Problem Behind the Accuracy Problem
Before Pinecone, Melange ran a self-hosted Milvus cluster. It worked fine at ~40M vectors, but that’s where it ended.
The moment they tried to scale toward the full global patent corpus (~450M documents at the time), the system collapsed under memory pressure. Uptime was unreliable. Index rebuilds failed. Maintenance costs soared. And most importantly, Melange could not guarantee complete, high-recall search.
The business implications were clear:
- Partial recall = increased risk of inaccuracy.
- Inaccuracy = increased legal and financial risk for clients.
- Engineering time spent fighting databases = slower delivery and higher TCO.
Melange did not have the people or time to fix those issues. They are a search and analytics company—not an infrastructure company. They needed a vector database that could give them reliable recall at massive scale and operate with minimal engineering work. As they evaluated replacements, including hosted options like Turbopuffer, Melange found that Pinecone offered the strongest recall and the most responsive support, both of which were essential.
Why Pinecone: High-Recall Retrieval + Simplified Operations = Lower TCO
Melange’s business needs are demanding and specific:
- Very large datasets
- Moderate throughput
- 99% recall
- Zero tolerance for downtime
- Fast iteration on new embedding models
- A predictable, low-maintenance cost structure
Pinecone matched those requirements directly by removing operational overhead and delivering consistent performance across massive datasets.
1. High-recall retrieval at scale
Accuracy starts with complete recall. Pinecone’s architecture keeps index structures stable and query performance predictable as dataset sizes grow into the hundreds of millions—and soon, billions—of vectors.
For Melange, this consistency is crucial. They can’t afford model regressions or index failures that would hide relevant documents from search results. This need for dependable, high-recall retrieval was a core reason Melange chose Pinecone over alternatives including Turbopuffer.
2. Serverless design = lower TCO
The most expensive part of running vector search isn’t compute; it’s people. Pinecone’s serverless design eliminated the need for Melange to maintain nodes, tune memory, rebuild indexes, or design storage strategies. Their team interacts with Pinecone as an API instead of an infrastructure system.
Our KPI for Pinecone is straightforward: how little time we spend thinking about it. — Joshua Beck, CEO at Melange
That simplicity directly decreases Melange’s total cost of ownership (TCO). They estimate Pinecone saves them ~$75,000 per year, not including the value of faster model iteration and less operational friction.
3. Stable ingestion and fast model iteration
Accuracy depends on fresh data and updated embeddings. Pinecone’s Parquet-based ingestion pipeline lets Melange load new model versions, run comparisons, and test new strategies without downtime or re-architecting their system.
4. Reliability as a competitive advantage
Melange’s customers expect their results to be complete and defensible. Pinecone’s reliability underpins that expectation. Since migrating, Melange reports zero reliability issues, even as vector counts climbed beyond 600M.
Reliability is not only a technical requirement—it is a differentiator in a market that often relies on trust built over years of legal work.
Powering High-Stakes Patent Search at Scale: How Melange Built a Reliable AI System on Pinecone
The Financial Cost of Inaccuracy
Melange works on cases where:
- The average cost of litigation is between $2.3M and $4M
- The average damages awarded are ~$24M
Missing a single prior-art document can materially alter the trajectory of those numbers.
But accuracy and inaccuracy also carry operational costs. These dynamics become clearer when you compare the costs of inaccuracy with the impact of a stable, high-recall retrieval system:
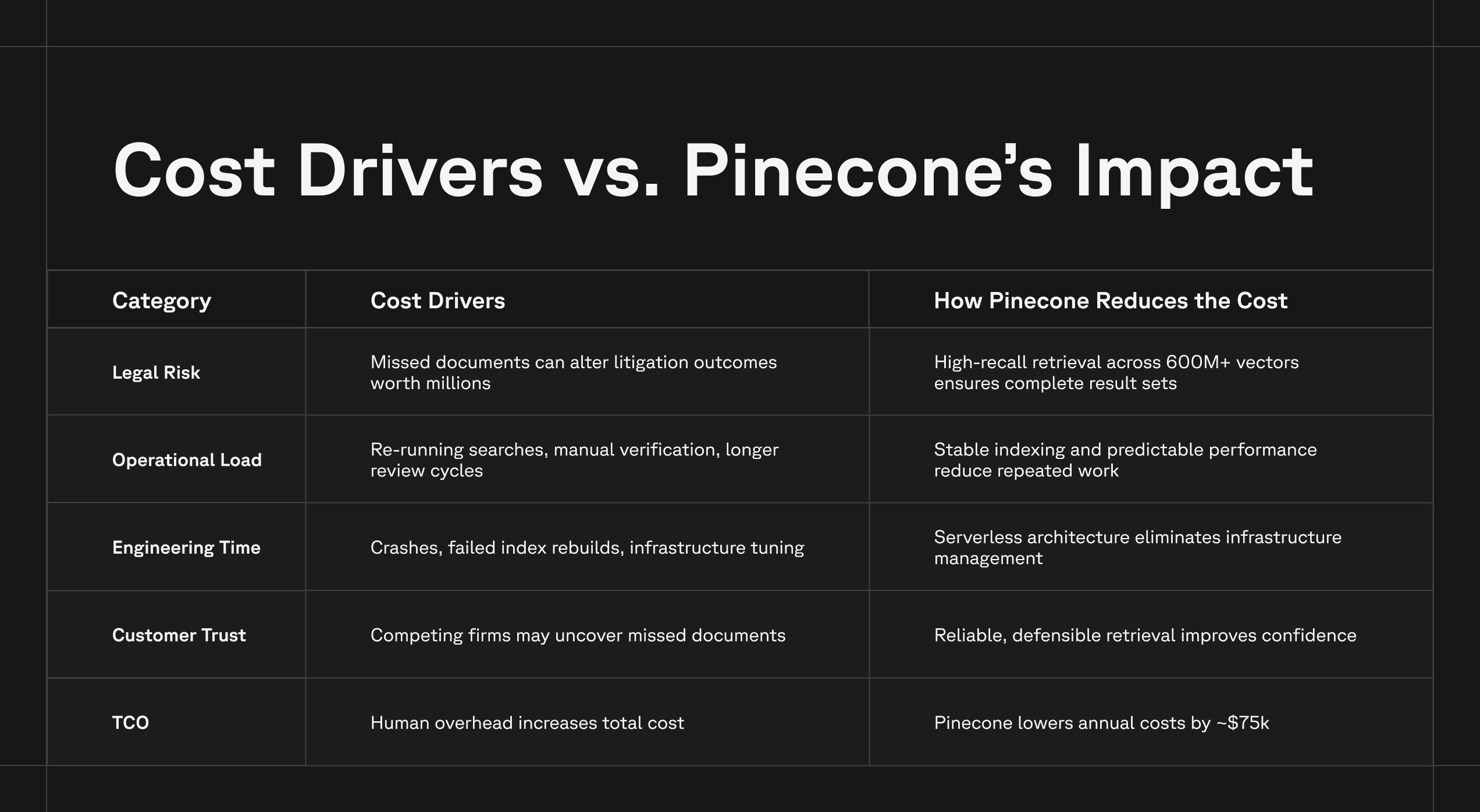
Accuracy at Scale Requires More Than a Model
A common misconception is that accuracy in retrieval systems comes solely from the embedding model. In reality, for companies like Melange, accuracy is a system property:
Model quality × index structure × search performance × freshness × completeness
Pinecone serves as the backbone of that system:
- Stable indexes mean Melange can trust their recall
- Predictable query behavior simplifies evaluation
- Serverless architecture ensures the system stays up, even as datasets grow
- High-performance storage formats keep ingestion fast and consistent
Accuracy emerges from the entire pipeline working in concert.
And because Pinecone removes complexity, the Melange team can focus on the parts of the system that directly improve accuracy: embedding strategies, ensemble models, and domain-specific ranking techniques.
The Stakes Are High and So Is the Value of Getting It Right
The cost of inaccuracy for Melange is real and quantifiable. In a world where a missed document can influence multi-million-dollar litigation, the retrieval system behind their AI must be both accurate and reliable.
Pinecone gives Melange a foundation where:
- High-recall retrieval scales to hundreds of millions of vectors
- Infrastructure disappears into the background
- Total cost of ownership stays low
- Engineers focus on the product, not the plumbing
- Accuracy—and trust—improves as the system grows
In an industry defined by high stakes and unforgiving margins, Melange uses Pinecone to deliver the one thing their customers care about most: Complete, reliable, defensible prior-art search—at scale.
Was this article helpful?