When building your own AI infrastructure stops being a strength and starts slowing you down
Oded Sagie is VP of R&D for Aquant, an agentic AI platform purpose-built for professionals servicing complex equipment at large manufacturing companies. He has spent nearly two decades leading teams that transform data into intelligent, scalable systems. While his engineering instincts drive him to build, his leadership experience has taught him when building becomes a distraction from creating business value.
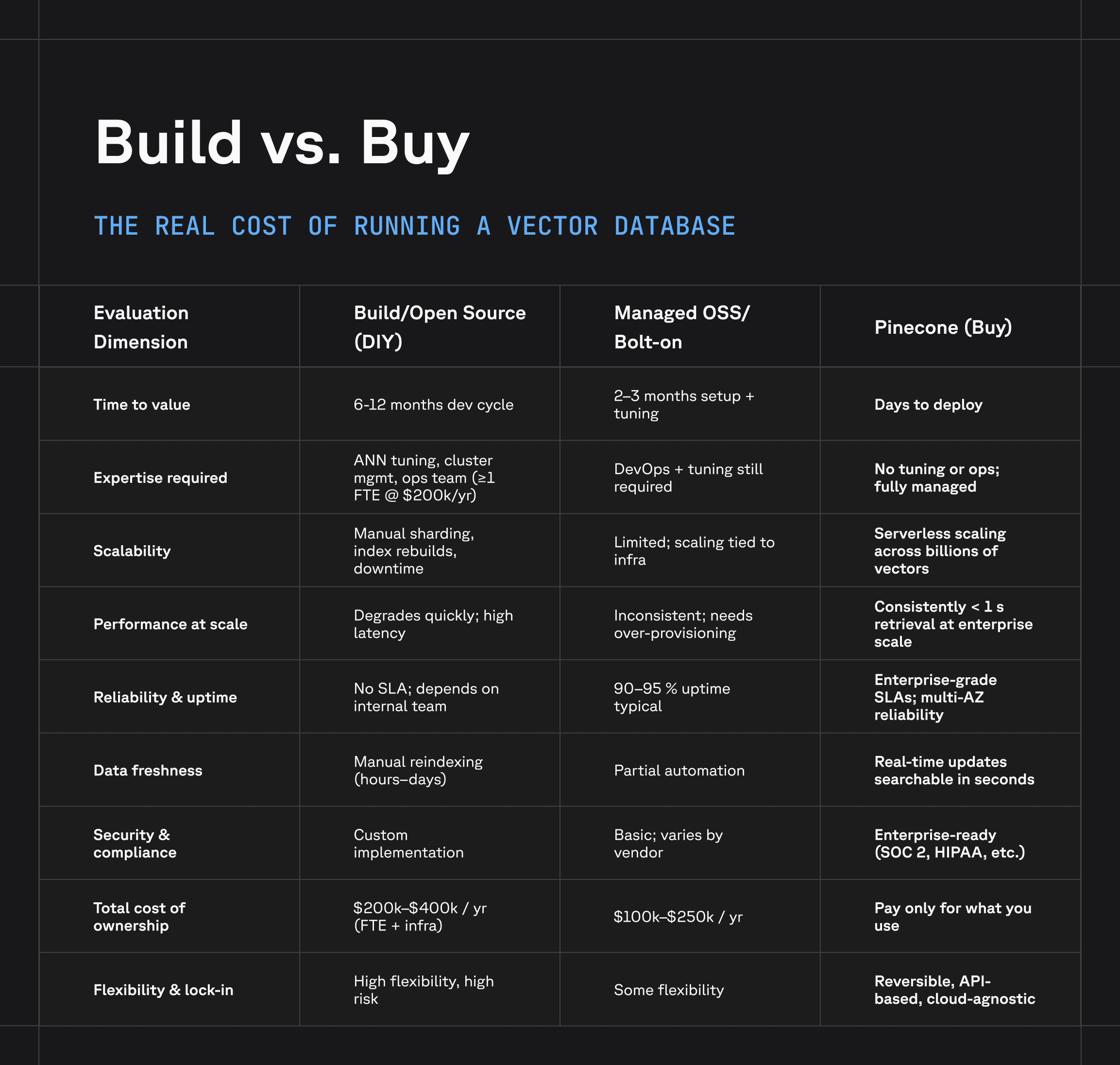
When Aquant began scaling its AI-driven service solutions, Oded faced a decision that every technical leader eventually confronts: Should we build our own vector database, or buy one?
We used to build our own vector DB. But you end up with an elephant you’re stuck with for years. — Oded Sagie, vice president of product and R&D at Aquant
That single sentence captures a truth many AI teams discover too late: what feels like freedom at the start — building your own stack — can become a long-term liability when the system succeeds.
The appeal (and illusion) of building
At first glance, building seems like the obvious choice. Open-source vector databases are available, seemingly for free, and every engineer wants to tailor systems precisely to their needs.
But there’s a gap between standing something up and running it in production at scale.
Building your own means taking responsibility for:
- Infrastructure management: tuning, scaling, and maintaining distributed clusters
- Search optimization: tweaking ANN indexes and query planning for latency and recall
- Reliability: designing redundancy, monitoring, and recovery systems
- Talent: hiring and retaining specialized engineers who can maintain it all
For most teams, these tasks add up to at least one full-time engineer (~$200K/year), and that’s before counting opportunity cost. Every hour spent debugging distributed search is an hour not spent improving the product.
You can only get so far when you’re developing something that’s not your core business. Our real innovation happens when our engineers are free to focus on problems unique to our domain — not reinventing infrastructure. — Oded Sagie, vice president of product and R&D at Aquant
Hidden costs compound over time
In the early stages, the cost of building seems manageable. But as workloads grow, those costs compound invisibly:
- Complexity debt: each customization becomes another dependency that someone must understand
- Knowledge loss: when key engineers leave, the system’s tribal knowledge leaves with them
- Time debt: new product features slow down because data pipelines, indexes, or retrieval code must be rebuilt
Eventually, what began as a small internal project evolves into what Oded calls “an elephant” that’s large, immovable, and expensive to feed.
At enterprise scale, these burdens directly impact business performance. Retrieval latency rises, engineering agility drops, and customer-facing AI experiences degrade.
The business cost of “free”
Open-source systems are rarely free. They simply move the cost from a vendor invoice to a payroll line item.
For Aquant, and many others, this realization came when they ran the numbers:
- Infrastructure costs for hosting vector workloads at scale
- Engineering headcount to manage and tune systems
- Delayed time-to-market for every new use case
The total cost of ownership is only visible after you pick the solution, pilot it, and deploy it. Then you start to see what it really costs to maintain. The challenge — and opportunity — is to see those patterns early and make data-driven platform decisions before scale magnifies the pain. — Oded Sagie, vice president of product and R&D at Aquant
In contrast, buying a managed vector database shifts those hidden costs into a predictable, usage-based model. You pay for what you use, not for the expertise and infrastructure you have to maintain yourself.
The case for buying — and when it makes sense
Oded isn’t dogmatic. Aquant still builds where it makes sense, especially for small, non-core components that don’t risk production reliability.
When the feature isn’t significant to the infrastructure, open source is perfect. But for foundational building blocks, I’d rather trust an enterprise-ready tool. That balance — knowing what to build, what to buy, and when to pivot is one of the most critical calls in scaling AI systems. — Oded Sagie, vice president of product and R&D at Aquant
That’s how Aquant came to see Pinecone as an exception. It’s one of the few “table-stakes” vendors they trust at the foundation of their AI stack.
By partnering with Pinecone, Aquant’s team shifted its focus back to what truly differentiates their business: applying nearly a decade of service AI expertise to deliver faster answers and smarter recommendations for customers.
Aquant delivers scalable, expert-level service intelligence with Pinecone
A pattern across the industry
Aquant’s decision isn’t unique. Across industries, teams that begin with open source often reach the same inflection point:
- Early-stage: Building is flexible and fast
- Growth stage: Maintenance and reliability consume time and headcount
- Enterprise stage: Compliance, uptime, and performance requirements outgrow DIY systems
That’s when buying becomes not just easier, but smarter.
The real question isn’t “build or buy” — it’s what’s the cost of building?
When choosing infrastructure for AI workloads, cost isn’t only measured in dollars. It’s measured in time, expertise, opportunity, and momentum.
The hidden cost of building is the distance between where your engineers spend their time and where your business creates value.
And as Aquant learned, that distance can be the difference between an AI prototype and an AI-powered product that scales.
Building feels empowering, until it’s all you’re doing.
The fastest way to create value from your data is to partner with those who’ve already solved the hardest problems.
Was this article helpful?