Cascading retrieval with multi-vector representations: balancing efficiency and effectiveness
Introduction
In recent years, multi-vector retrieval has emerged as a powerful approach for improving the accuracy of dense retrieval models. Methods like ColBERT, ColPali, and MUVERA allow retrieval systems to capture fine-grained multi-vector interactions, outperforming traditional single-vector dense retrieval or sparse retrieval approaches. However, this effectiveness comes at a cost—multi-vector models require significantly more storage and computational resources compared to single-vector approaches. Each document in the index is represented by multiple vectors, leading to higher memory usage and increased storage requirements. Additionally, multi-vector retrieval typically involves more complex query-time computations, which can result in higher latency compared to dense or sparse retrievers.
That said, it's crucial to highlight that despite the increased memory footprint, multi-vector retrieval is still orders of magnitude faster than cross-encoder rerankers. While cross-encoders compute full query-document attention at query time—making them computationally expensive and often impractical for large-scale search—multi-vector models precompute document representations and leverage efficient late interaction mechanisms, significantly reducing query-time latency. This makes multi-vector retrieval a practical middle ground between single-vector retrieval (fast but less effective) and cross-encoder reranking (highly effective but too slow for large-scale applications).
A natural question arises:
How can we make multi-vector retrieval scalable and effective?
Instead, we see multi-vector retrieval as a powerful intermediate step within a retrieval pipeline. The main concept is to apply progressively more sophisticated models at different stages — starting with a fast first-stage retriever, followed by multi-vector refinement, and finally, if needed, a high-precision reranker. This structured approach preserves efficiency while leveraging the strengths of multi-vector models in a way that remains computationally practical.
In this blog post, we will:
- Highlight the limitations of simple retrieve-and-rerank pipelines and the need for multi-vector models.
- Introduce the concept of a multi-step reranking approach that uses multi-vector embeddings at scale to increase accuracy, followed by cross-encoder re-ranking for the final step.
- Present ConstBERT, a constant-space multi-vector retrieval model, developed through a collaboration between Pinecone, Sean MacAvaney (University of Glasgow), and professor Nicola Tonellotto (University of Pisa), that reduces storage overhead while maintaining effectiveness.
- Show how to integrate ConstBERT, now available in open source, into Pinecone.
By the end of this post, you'll have a practical roadmap for implementing efficient and scalable multi-vector retrieval within Pinecone, ensuring that search remains both fast and accurate. 🚀
Challenges with Multi-Vector Approaches at Scale
A common approach to improving search effectiveness is to use multi-vector retrieval as a monolithic method, where it serves both as the retrieval and final reranking mechanism. While this can improve ranking quality, it often results in higher storage requirements and increased query latency, making it difficult to scale for large-scale applications.
Multi-vector retrieval methods like ColBERT achieve strong effectiveness but face major challenges in scalability. Each document is encoded as a set (of variable size) of token-level vectors, leading to serious issues in storage, retrieval, and memory usage.
The main challenge consists in memory and compute usage: a document with T tokens produces T vectors. At query time, each query vector retrieves its top-k matches from all the document term vectors. All the corresponding document identifiers are merged into a candidate set. These candidates, carefully filtered with heuristics, are then re-ranked by computing their full multi-vector score. At scale, this process requires a vast amount of memory which is accessed with random patterns, and performs a lot of computations to calculate the final scores.
While highly effective on small datasets, traditional multi-vector retrieval quickly becomes impractically expensive and less precise as data size grows.
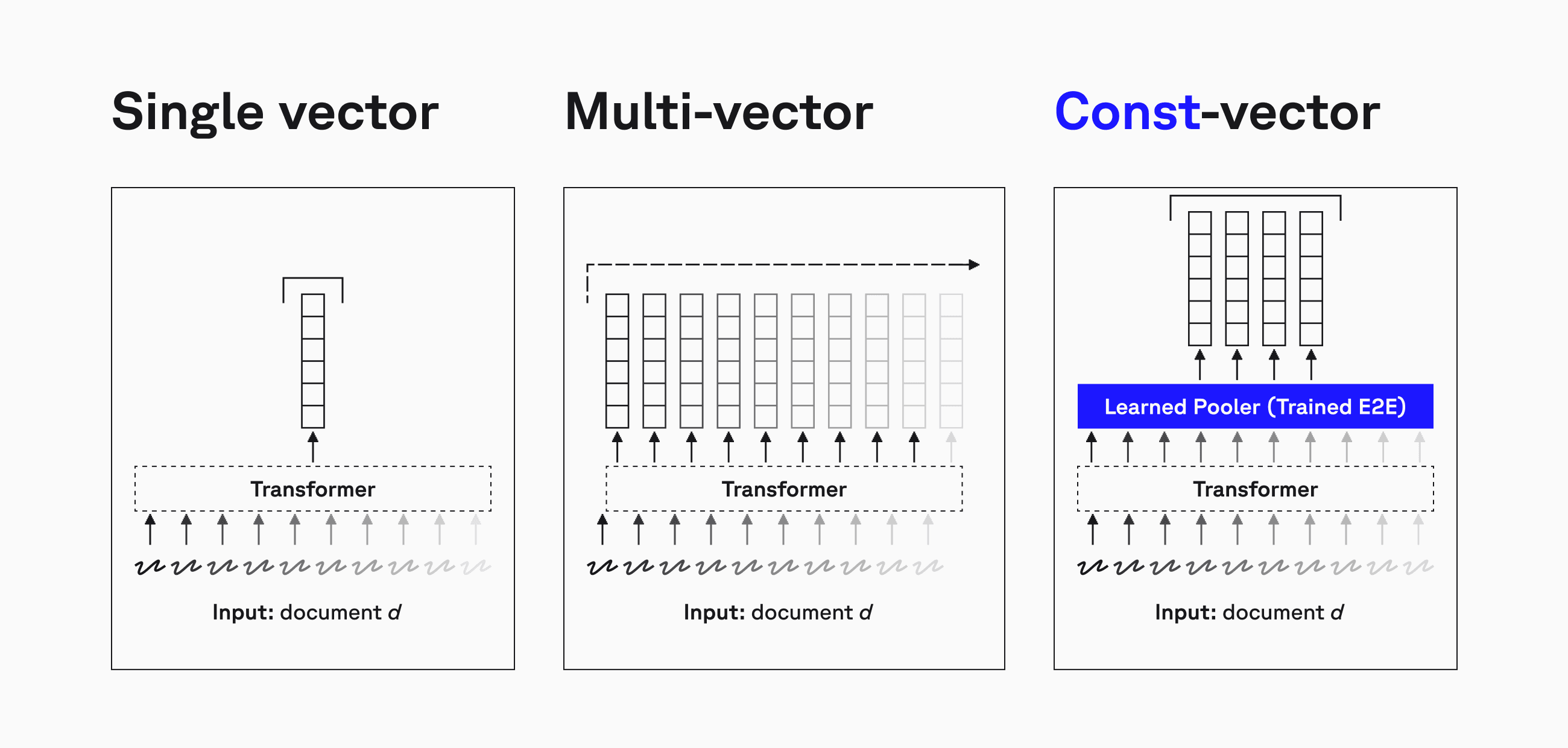
ConstBERT: A Practical Multi-Vector Retrieval Solution
ConstBERT takes a different approach. Instead of storing a separate vector for each token, it learns a fixed-size representation for each document, making multi-vector retrieval more practical, cache-friendly, and easier to integrate into real-world search pipelines.
Fixed-Size Document Representations: The Key Advantage
One of the main limitations of standard multi-vector retrieval is that the number of stored vectors per document varies based on document length. This variability makes it difficult to:
- Optimize indexing structures: Query efficiency suffers when document lengths are inconsistent.
- Leverage cache-friendly memory layouts: OS paging and vector processing become inefficient.
- Scale efficiently: Large documents contribute disproportionately to index growth.
ConstBERT eliminates these issues by enforcing a fixed number of vectors per document (e.g., 32, 64, or 128 vectors), regardless of document length.
This approach makes it:
- Easier to manage and scale in a vector database: All documents have uniform storage sizes, simplifying retrieval logic.
- More efficient for query-time processing: Avoids the overhead of variable-length comparisons, leading to better cache locality and SIMD optimizations.
- Compatible with real-world applications: Allows batch processing of documents without worrying about inconsistent representation sizes.
Efficiency and Memory Optimizations
While the primary motivation behind ConstBERT is its practicality, it also offers significant efficiency benefits:
- Smaller Index Size
- Traditional multi-vector models require storing embeddings for every token in the document.
- ConstBERT compresses the representation into a fixed-size format, reducing index size by 50% or more while maintaining effectiveness.
- Faster Query Processing
- Instead of iterating over dozens or hundreds of vectors per document, ConstBERT enables efficient late interaction scoring across a compact set of learned vectors.
- This results in lower query latency and better computational efficiency.
- Cache-Friendly Retrieval
- With fixed-length representations, memory access patterns become more predictable.
- This improves OS-level paging, CPU cache utilization, and hardware acceleration (SIMD/AVX optimizations).
💡A Parallel in Image Retrieval: ColPali
While ConstBERT optimizes text retrieval with fixed-size representations, a similar idea has been explored for image retrieval through ColPali.
ColPali applies the same principle of fixed-length multi-vector encoding but in the context of image search. Instead of using variable token representations, ColPali extracts a fixed number of learned vectors per image, making image retrieval more efficient and scalable.
This reinforces a broader trend in retrieval models:
Fixed-size multi-vector representations lead to better memory efficiency, computational efficiency, and scalability.
Beyond Retrieve-and-Rerank: Why Multi-Vector Matters
The Retrieve-and-Rerank Paradigm
Traditionally, information retrieval systems follow a two-stage architecture:
- Retrieval (first-stage): A lightweight retriever (like BM25 or a single-vector dense retriever) selects a candidate set of documents—usually a few hundred—from a massive corpus. This step prioritizes speed and recall over precision.
- Reranking (second-stage): A powerful model (often a cross-encoder) re-evaluates these candidates using full query-document attention, producing a highly accurate final ranking.
This paradigm works reasonably well, but the lower retrieval quality of the first stage means a larger amount of data must be sent to the second stage which scales poorly. Cross-encoders are prohibitively expensive to run over large candidate sets, and much of that compute may be spent evaluating irrelevant or low-quality results. Moreover, the quality of retrieved candidates greatly affects reranking effectiveness.
Multi-vector as the Missing Middle Layer of a Retrieval Pipeline
Multi-vector models fill the gap between retrieval and reranking, offering a scalable way to improve relevance before expensive rerankers are applied. Such a method can be functional not only to reduce the number of documents sent to expensive final-stage models, but also to fuse the sparse and dense candidates into a unified, more precise ranking.
Unlike single-vector retrieval, which reduces documents to a single embedding, multi-vector models retain token-level granularity. This allows for more precise scoring through late interaction mechanisms, helping filter out low-quality candidates without needing full attention-based reranking. This property also allows detecting localized relevance—specific passages, phrases, or concepts that match the query—even when the overall document is noisy or lengthy. This leads to more targeted candidate selection compared to single-vector methods.
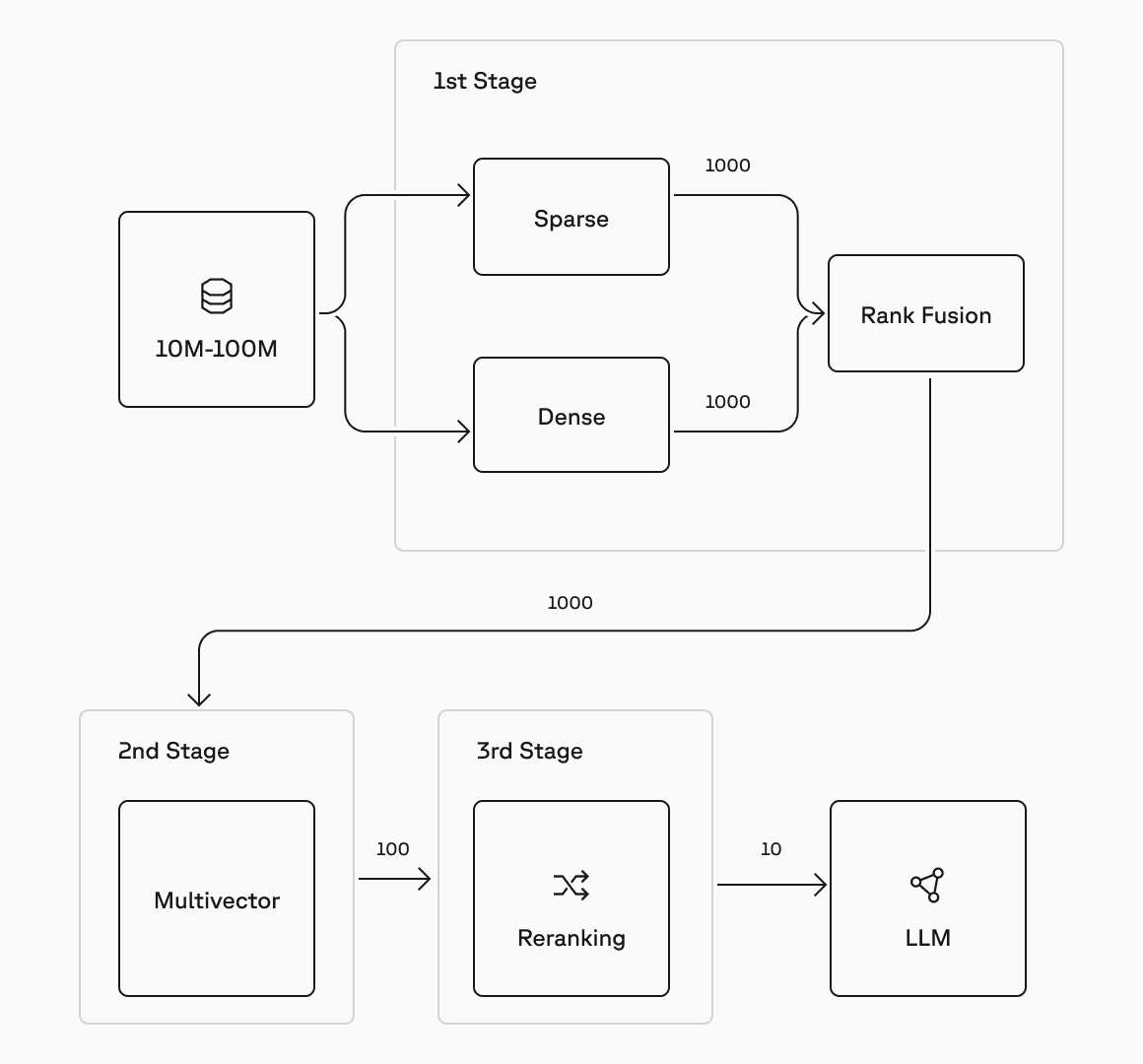
Multi-vector systems can be integrated in retrieval pipelines with flexible cutoffs. Above we see:
- The entire data corpus stored as hundreds of millions, if not billions, of vectors in the database.
- The first stage retrieves around 1000 highly similar records (in this case merging 1000 from both a dense and sparse representation).
- Those 1000 are re-ranked at very high speed using a MaxSim algorithm using their multi-vector representations (which is stored alongside the single-vector) to return a candidate set of 100.
- Those 100 are then sent to a cross-encoder re-ranker which considers them alongside the original query to come with a highly relevant top_k=10 results which can be passed on to an LLM for final response generation.
The key here is that each stage of retrieval progressively improves and shrinks the candidate results so that the following stage has less, but more accurate, data to spend its more expensive resources on. This lets you balance speed and quality dynamically depending on the use case, latency tolerance, or priority (e.g., relevance vs cost).
Implementing Cascading Retrieval with ConstBERT in Pinecone
Integrating ConstBERT into a retrieval pipeline requires careful consideration of efficiency, scalability, and flexibility. Since ConstBERT produces a fixed number of embeddings per document, it can be incorporated into a cascading retrieval system in multiple ways. In this section, we explore a practical approach for using ConstBERT with Pinecone: enhancing an existing index by storing ConstBERT embeddings as metadata.
Metadata-Based Reranking
The simplest way to integrate ConstBERT into Pinecone is by storing ConstBERT embeddings as metadata in an existing single-vector index. This allows you to:
- Keep your current retrieval system (e.g., pinecone-sparse-english-v0, dense retrieval) while benefiting from multi-vector reranking.
- Reduce index duplication by avoiding the need to store a separate multi-vector index.
- Perform lightweight reranking after retrieving an initial set of candidates.
How it works:
- Create a Pinecone index (e.g., storing single-vector dense or sparse representations).
- Store ConstBERT vectors as metadata alongside the single-vector embeddings.
- Retrieve top-k candidates using a first-stage retriever (sparse, dense retriever, etc.).
- Apply late interaction scoring using the stored multi-vector representations.
- Return reranked results for the final ranking.
Let’s begin by doing the necessary imports and defining some utility functions:
import itertools
from pinecone import Pinecone
from tqdm import tqdm
import os
import numpy as np
def chunks(iterable, batch_size=200):
"""A helper function to break an iterable into chunks of size batch_size."""
it = iter(iterable)
chunk = tuple(itertools.islice(it, batch_size))
while chunk:
yield chunk
chunk = tuple(itertools.islice(it, batch_size))
def encode_fp16_to_string(arr):
"""Encode a NumPy float16 array into a hex string."""
byte_data = arr.tobytes()
hex_str = byte_data.hex()
return hex_str
def decode_string_to_fp16(string):
"""Decode a hex string back into a float16 array."""
byte_data = bytes.fromhex(string)
return np.frombuffer(byte_data, dtype=np.float16)
def generate_data(num_examples):
"""Generate random example data for the multi-vector index."""
ids = [str(i) for i in list(range(num_examples))]
embeddings = np.random.randn(num_examples, 1024)
multivector_embeddings = np.random.randn(num_examples, 32, 128).astype(np.float16)
multivector_embeddings = multivector_embeddings.reshape(num_examples, -1)
data = []
for i in range(len(ids)):
data.append({
"id": ids[i],
"values": embeddings[i].tolist(),
"metadata": {
"multivector": encode_fp16_to_string(multivector_embeddings[i])
}
})
return data
def generate_query():
"""Generate a random example query for the multi-vector index."""
query_vector = np.random.randn(1024)
multivector_vector = np.random.randn(32, 128).astype(np.float16)
return query_vector, multivector_vector
def max_sim(q: np.ndarray, d: np.ndarray) -> float:
"""Implementation of the max-sim scoring function, used for multi-vector scoring."""
scores = np.dot(d, q.T)
max_scores = np.max(scores, axis=0)
return float(np.sum(max_scores))We instantiate Pinecone and create an index (if it does not exist):
api_key = os.environ["PINECONE_API_KEY"]
upsert_threads = 30
total_attempts = 10
upsert_batch_size = 64
index_name = "your-index-name"
namespace = "your-namespace"
pc = Pinecone(api_key=api_key, pool_threads=upsert_threads)
# If the index does not exist, create it using the desired settings.
if not pc.has_index(index_name):
pc.create_index_for_model(
name=index_name,
cloud="aws",
region="us-east-1",
embed={
"model": "multilingual-e5-large",
"field_map": {"text": "chunk_text"}
}
)Then, we upsert the vectors in the index:
data = generate_data(num_examples=1000)
# Upsert the data into the index with error handling
with pc.Index(name=index_name, pool_threads=upsert_threads) as index:
chunked_data = list(chunks(data, batch_size=64))
to_upsert = chunked_data
current_attempt = 0
while current_attempt < total_attempts:
async_results = []
for ids_vectors_chunk in tqdm(chunked_data, desc=f"Upsert attempt {current_attempt + 1}/{total_attempts}"):
async_request = index.upsert(vectors=ids_vectors_chunk, async_req=True, namespace=namespace)
async_results.append(async_request)
to_upsert = []
for chunk_id, async_result in enumerate(async_results):
try:
async_result.get()
except Exception:
to_upsert.append(chunked_data[chunk_id])
if len(to_upsert) == 0:
break
chunked_data = to_upsert
current_attempt += 1
if current_attempt == total_attempts:
raise Exception(f"Failed to upsert all data.")Finally, we query the index and print out both first-stage and multi-vector results:
query_embedding, query_multivector_embeddings = generate_query()
query_embedding = query_embedding.tolist()
index = pc.Index(name=index_name)
result = index.query(
vector = query_embedding,
namespace = namespace,
top_k = 100,
include_values = False,
include_metadata = True,
async_req = False,
)
current_results = []
for hit in result["matches"]:
current_results.append({
"id": hit["id"],
"score": hit["score"],
"multivector_string": hit["metadata"]["multivector"],
})
print("Retrieval results:")
for i, hit in enumerate(current_results, start=1):
print(f"\t{i}.\tDoc ID: {hit['id']}; Score: {hit['score']}")
print("\n")
for hit in current_results:
hit["multivector"] = decode_string_to_fp16(hit["multivector_string"]).reshape(32, 128)
hit["multivector_score"] = max_sim(query_multivector_embeddings, hit["multivector"])
# rerank results with multivector scores
current_results.sort(key=lambda x: x["multivector_score"], reverse=True)
print("Multivector reranking results:")
for i, hit in enumerate(current_results, start=1):
print(f"\t{i}.\tDoc ID: {hit['id']}; Score: {hit['multivector_score']}")This approach stores ConstBERT embeddings as metadata alongside document representations in the primary retrieval index. This simplifies system architecture, as all data resides in a single index, reducing the need for additional API calls. Keep in mind that this introduces small query-time retrieval overhead, since metadata storage is not optimized for fast multi-vector lookups. Additionally, embedding large multi-vector representations as metadata can increase storage costs and slightly slow down retrieval operations, particularly when handling a high volume of queries.
Benchmarking Performance & Trade-Offs
In this section, we evaluate the effectiveness of using ConstBERT as a reranker, compared to the standard end-to-end retrieval approaches of both ConstBERT and ColBERT.
Experimental Setup
To evaluate ConstBERT and compare it to alternative retrieval strategies, we designed a controlled experimental setup covering datasets, evaluation metrics, baselines, and system settings:
Datasets & Query Sets
- MSMARCO Passage Collection (8.8M passages): Used as the document corpus for the TREC Deep Learning benchmarks (DL19 and DL20), providing a large-scale retrieval base for evaluating on small but high-quality (TREC DL) query sets.
- BEIR Benchmark: A suite of 12 retrieval tasks spanning domains like fact checking, scientific retrieval, and Question Answering, evaluated using their standard corpora and query sets.
Metrics
- nDCG@10: Normalized Discounted Cumulative Gain at top 10, measures ranking quality by accounting for both the position and relevance grade of retrieved documents—giving more credit to results that surface the most relevant answers earlier.
Results
Multi-vector models like ConstBERT and ColBERT are not optimized for direct first-stage retrieval at massive scale — they are designed to excel as second-stage rerankers within a cascading pipeline.
Latency and Efficiency Trade-Offs
| Sparse | Dense | Late Interaction | Cross-encoder | |
|---|---|---|---|---|
| Pre-computable | ✅ | ✅ | ✅ | ❌ |
| Retrieval-ready | ✅ | ✅ | ⚠️ | ❌ |
| Efficient at scale | ✅ | ✅ | ⚠️ | ❌ |
| High accuracy | ❌ | ❌ | ⚠️ | ✅ |
Late interaction models offer a middle ground: they significantly improve ranking precision compared to dense retrieval, without the heavy compute cost of cross-encoders.
| MSMARCO (nDCG@10) | TREC DL19 | TREC DL20 |
|---|---|---|
| ColBERT (e2e retrieval) | 74.6 | 74.0 |
| ConstBERT (e2e retrieval) | 73.1 | 73.3 |
| ConstBERT (reranking) | 74.4 | 74.0 |
| BEIR 12 (nDCG@10) | c.-fever | dbpedia | fever | fiqa | hotpotqa | nfcorpus | nq | quora | scidocs | scifact | t.-covid | webis-t. | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ColBERT (e2e retrieval) | 16.3 | 43.4 | 75.1 | 33.8 | 67.9 | 32.9 | 55.4 | 84.6 | 15.4 | 63.8 | 70.5 | 216.1 | 48.8 |
| ConstBERT (e2e retrieval) | 14.2 | 41.8 | 69.6 | 31.2 | 62.1 | 32.7 | 53.4 | 82.1 | 15.6 | 60.7 | 74.5 | 26.0 | 47.0 |
| ConstBERT (reranking) | 20.3 | 44.3 | 73.3 | 35.1 | 67.6 | 33.0 | 56.0 | 83.0 | 16.7 | 63.6 | 79.2 | 30.8 | 50.2 |
ConstBERT is most effective when used as a reranker in a cascading pipeline. While slightly behind ColBERT in standalone retrieval, ConstBERT matches or outperforms it when reranking top candidates — combining high accuracy with lower storage and compute overhead. In fact, in the training procedure of end-to-end multi-vector models, the MaxSim score (that you can see in the code example) is computed using all the vector representations of each document, but single-vector retrieval is used as a first stage, despite not optimizing such objective. 48.8
Latencies were not evaluated since multi-vector retrieval is not implemented end-to-end in production. Academic research has shown that end-to-end ColBERT is notably slow, even when using the official PLAID engine, which takes a few hundreds of milliseconds per query. However, when multi-vector is used as a ranking system, the main cost comes from first-stage retrieval as MaxSim computation for hundreds of documents takes only a few milliseconds.
Conclusion & Future Directions
In this post, we explored multi-vector reranking as a strategy to balance efficiency and effectiveness in search pipelines. Instead of relying on single-vector retrieval alone or expensive cross-encoder rerankers, we demonstrated how ConstBERT enables scalable multi-vector retrieval, serving as an efficient intermediate reranking step.
Key takeaways:
- Multi-vector retrieval is essential for improving ranking quality while keeping latency low.
- ConstBERT’s fixed-size representations make multi-vector retrieval practical by reducing storage and improving memory efficiency.
- Pinecone provides a scalable way to integrate ConstBERT through metadata-based reranking.
Looking Ahead: Future Directions
While ConstBERT provides a scalable alternative to traditional multi-vector retrieval, there are still open challenges and opportunities for further optimization:
- Can we further compress multi-vector representations?
- Smaller embeddings without losing retrieval quality.
- Quantization and pruning techniques to reduce storage.
- Can adaptive reranking strategies improve efficiency dynamically?
- Dynamically selecting the best reranking method based on query complexity.
- Hybrid approaches that combine single-vector and multi-vector scoring intelligently.
Try ConstBERT Today!
ConstBERT is an exciting step forward in efficient multi-vector retrieval, and you can try it out in Pinecone today.
- Start building with ConstBERT in Pinecone → Get the open source code and experiment with metadata-based reranking.
- Join the discussion! → Share feedback and insights with the Pinecone community.
- Follow our updates! → Keep up with the latest techniques and best practices in vector search and retrieval.
Was this article helpful?