Pinecone Assistant is a fully-managed service built to power grounded chat and agent-based applications. The API takes away your need to worry about the many systems and steps required to build an AI assistant for knowledge-intensive tasks with private data. That includes chunking, embedding, file storage, query planning, vector search, model orchestration, reranking, and more.
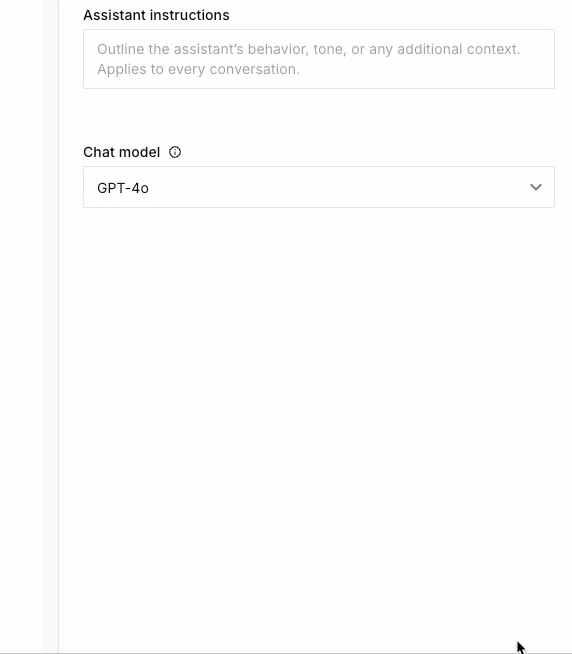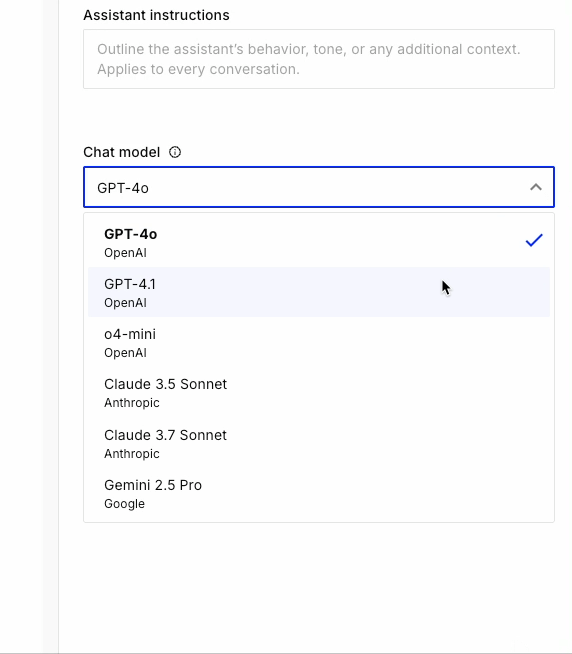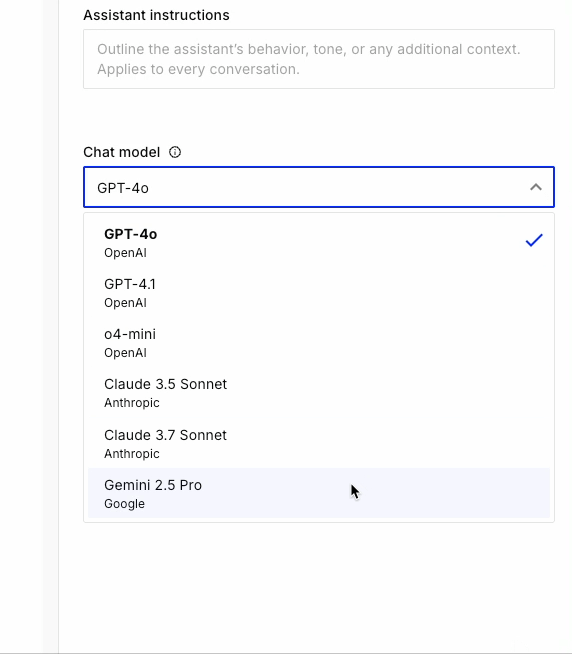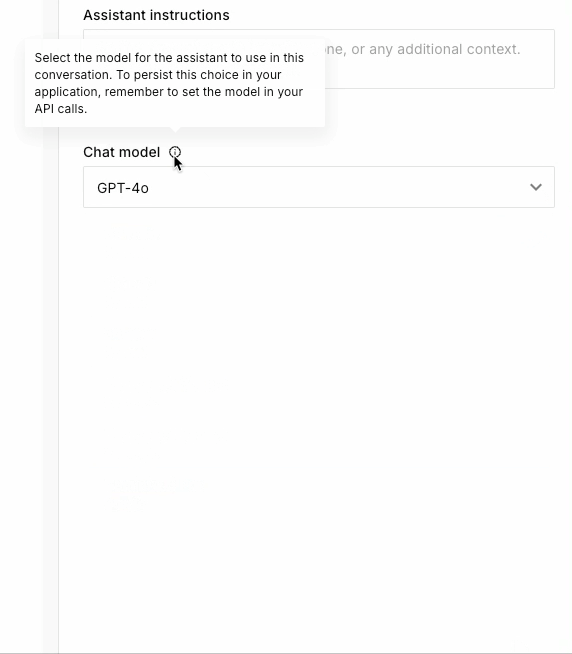
Pinecone Assistant uses LLMs to provide context and final answer generation. Its quality stems first and foremost from the ability to generate highly-relevant context through better search. After a thorough review of models that meet this criteria, as well as strong user demand, today we are excited to add support for new OpenAI (gpt-4.1, o4-mini) and Anthropic (claude-3-7-sonnet) LLMs, and to welcome Gemini (gemini-2.5-pro) to Assistant.
Three main factors guide our model support selection: security, availability, and stability.
Before making new models available through Pinecone Assistant, our team works to ensure that the providers can offer 1. a private cloud deployment with sufficient token-per-minute rate support 2. stability/consistency with regard to response quality and citation formatting.
Changing the LLM you want to use with Pinecone Assistant is done by simply passing the model name with your choice.
msg = {"role":"user", "content":"What triggers the main conflict in Pride and Prejudice?"}
resp = assistant.chat(messages=[msg], model="claude-3-7-sonnet")
Check out the Pinecone Assistant reference and guide in our docs for more information and implementation details.
Customizing output with temperature
In addition to the new selection of models, we’re now giving you more control by exposing the temperature parameter for your chosen LLM. Temperature affects the sampling process from the probability distribution of new tokens. In short, low temperatures (~0.0) yield more consistent, predictable answers and high temperatures (>1.0) increase a model’s explanatory power. Higher temperatures are generally better for creative tasks or when you want to generate multiple completions and select one in post-processing.
You can specify temperature directly in the Pinecone Assistant chat API:
from pinecone import Pinecone
pc = Pinecone(api_key='PINECONE_API_KEY')
assistant = pc.assistant.Assistant(assistant_name="test-amnon")
msg = {"role": "user", "content": "what is the meaning of life?"}
resp = assistant.chat(messages=[msg], temperature=2.5)If the temperature parameter is not passed, Pinecone Assistant falls back to the default value set by the given model provider.
As providers increase the pace of innovation, we’ve updated our infrastructure to be able to quickly adapt and add more models going forward. In the world of knowledgeable AI applications, context is king. We’re excited about what the future holds and to see what Pinecone Assistant users build with increased capabilities. Reach out and let us know!
Was this article helpful?